MapReduce框架-Join的使用
引言
首先先明白在关系型数据库中Join的用法。
Join在MapReduce中的用法也是用于两个文件之间的连接。
使用MR程序解决两张表的join问题,有两种解决方案 à MR程序的join应用
1. reduce端join
在map端将数据封装成Java对象 à 两张表的复合Java对象
在reduce端根据对象值的不同进行join操作
2. map端join
通过缓冲流将小文件存储起来,在map阶段根据对象值的不同进行join操作
关系型数据库MySQL中Join的用法
(MySQL中JOIN的用法均整理于https://www.cnblogs.com/fudashi/p/7491039.html)
在关系型数据库中,Join主要用于两张表的连接,就如同英语单词“join”一样,可以分为内连接、外连接、左连接、右连接、自然连接。
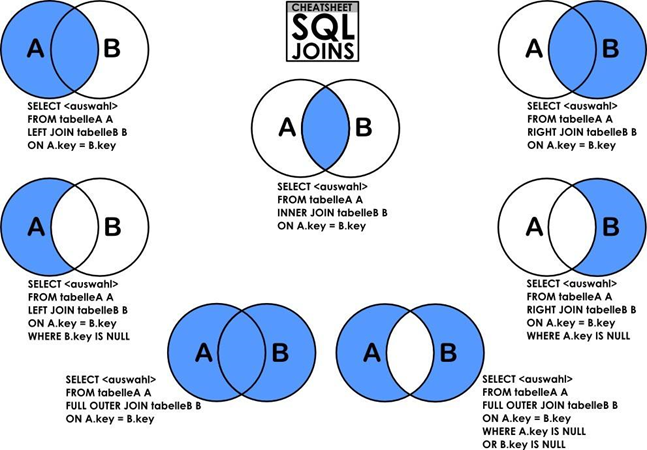
笛卡尔积:CROSS JOIN
笛卡尔积是将A表中的数据和B表中的数据组合在一起,假设A表中有n条记录,B表中有m条记录,经过笛卡尔积组合后就会产生n * m条记录。
内连接:INNER JOIN
内连接INNER JOIN是最常用的连接操作(即求两个表的交集),从笛卡尔积的角度来说就是从笛卡尔积中挑出ON子句成立的记录。有INNER JOIN,WHERE(等值连接),STRAIGHT_JOIN,JOIN(省略INNER)四种写法。
左连接:LEFT JOIN
左连接就是求两个表的交集以及左表的其余数据。从笛卡尔积的角度讲,就是先从笛卡尔积中跳出ON字句条件成立的记录,然后加上左表中剩余的记录。
右连接:RIGHT JOIN
与左连接相同,就是求两个表的交集以及右表的其余数据。
外连接:OUTER JOIN
外连接就是求两个集合的并集。从笛卡尔积的角度讲就是从笛卡尔积中挑出ON字句条件成立的记录,然后加上左表中剩余的记录,再加上右表中剩余的记录。MySQL不支持OUTER JOIN,但是可以对左连接和右连接的结果做UNION操作来实现。
Reduce Join
Reduce Join介绍

案例
需求:
订单数据表t_order:
|
id |
pid |
amount |
|
1001 |
01 |
1 |
|
1002 |
02 |
2 |
|
1003 |
03 |
3 |
商品信息表t_product
|
pid |
pname |
|
01 |
小米 |
|
02 |
华为 |
|
03 |
格力 |
要求将商品信息表中数据根据商品pid合并到订单数据表中。
最终数据形式:
|
id |
pname |
amount |
|
1001 |
小米 |
1 |
|
1004 |
小米 |
4 |
|
1002 |
华为 |
2 |
|
1005 |
华为 |
5 |
|
1003 |
格力 |
3 |
|
1006 |
格力 |
6 |
如果想要实现这一功能,使用MySQL可以利用Select id, b.pname, a.amount from t_order as a left join t_product as b on a.pid=b.pid 轻松实现。但是如果数据量庞大的话,利用MySQL来实现将会耗费非常久的时间,无法即时完成需求。而使用MapReduce可以解决这一问题。
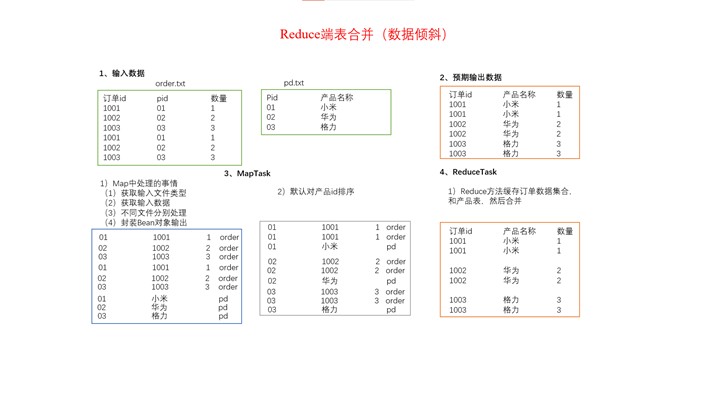
实现思路:reduce端表合并(数据倾斜)
通过将关联条件作为map输出的key,将两表满足join条件的数据并携带数据所来源的文件信息,发往同一个reduce task,在reduce中进行数据的串联。
步骤
第一步:JavaBean对象的编写
先声明一个JavaBean对象---OrderBean,该JavaBean对象是一个复合的JavaBean,其中涵盖了两张表涉及到的所有信息。order表会用到这个bean,product也会用到一个bean。所以为了区分两个表,应该设置一个变量flag,用于定义该表是order表还是product表。同时,为了将这个bean作为一个序列化信息进行中间值传递与输出,还需要将这个bean继承Writable类实现自定义序列化,并且实现其中的序列化和反序列化方法。
第二步:Mapper类的编写
通过Mapper类实现文件切片信息的读取,并且根据文件名不同,封装不同的OrderBean对象。根据之前所学的经验,在Mapper阶段需要将切片数据中获取到的信息传递到JavaBean对象中,然后通过context,write()方法传递给Reducer阶段。然后在Mapper阶段需要考虑一个问题:怎么获取到的切片信息是哪个文件的?怎么把切片信息和所属文件对应起来?只要解决了这两个问题,向Reduce阶段传输数据就迎刃而解了。
首先需要明白MapReduce程序默认的切片机制是TextInputFormat,而在案例需求中可以发现这里不需要再自定义切片机制。所以根据TextInputFormat的切片机制:以文件对数据进行切割,也就是说每个文件最少有一个切片,可以轻松的看出来每一个切片数据都对应着一个固定的文件,不会出现两个文件的部分数据出现在一个切片的现象。所以可以根据切片来获取到文件的路径,之后再将路径和该切片的信息对应起来即可了。
有了上述思想准备,再补充一个方法:setup()方法,该方法可以理解为一个初始化方法,其作用类似于Junit单元测试的@Before,用在Mapper阶段表示在每执行一次map()方法之前都必须执行一次setup()方法。所以可以通过setup()方法,在setup()方法中实现查询切片对应文件路径的操作,以便于map在每进行一次切片时都能标记出他们所处的文件是哪个文件。
知道了切片信息处于哪一个文件之后,还需要考虑的问题就是该如何将切片信息和所属文件的数据信息对应起来?每一行切片数据经过split()方法将行数据进行切割后都会生成一个数组文件,这个数组数组文件可以有三项,那么它就是order表中的数据,也可能有两项,那么他就是product表中的数据,所以该怎么确定数组中有三项还是有两项呢?可以根据setup中定义的操作去得到该切片信息的文件名,然后根据文件名传出对应的值就可以了。此时要回忆起JavaBean对象中定义的flag。可以根据flag值的不同,区分出两个文件数据的不同。
总而言之,map阶段可以分为以下几步:
1、 MR程序读进来的是两个文件:order.txt、product.txt。通过InputFormat将数据读入后,先按照不同的文件执行不同的数据封装
2、 读取文件切片信息,根据文件名不同,封装不同的OrderBean对象(主要的含义还是在Mapper阶段对数据打上你是那个表的数据的标签)
3、 数据封装完成后,如果做join逻辑,那么需要将两张表的连接字段作为key,对象当做value,发送给Reducer
Map阶段处理完成的数据格式是:
|
key |
value |
|
1 |
OrderBean(1001 1 1 order) |
|
1 |
OrderBean(1 小米 product) |
|
1 |
OrderBean(1002 1 3 order) |
也就是将pid(产品id)作为key值,两张表对应key值的其他信息作为value值传给Reduce阶段。
第三步:Reducer类的编写
通过Map阶段,可以得到如上的key-value键值对,通过对表的分析可以得出两表之间的关系为:一个产品可以对应多个订单,而一个订单只能对应一个产品。而Reduce阶段的任务就是将Map阶段得到的数据合起来,将product表中的pname(产品名)和order表中的oid(订单编号)、count(订单数量)作为结果值输出到结果文件中。
此时可以以pid为key,读取到pid一样的OrderBean的集合数据。毫无疑问的是 pid一样的OrderBean集合中,只有一条产品信息的OrderBean,但是会有很多个订单的OrderBean。此时可以设置一个OrderBean对象用于存储Map阶段得到的product表中的数据,设置一个OrderBean对象的集合来存储map阶段得到的order表中的数据,这个可以通过在Map阶段中定义的flag值来区分什么时候该存储什么值。最后通过遍历将订单中的产品id修改为产品信息中的名字,输出到结果文件中,即可以完成该案例需求。
第四步:Driver类的编写
Driver类还是按照常规编写,需要注意的是此处传入的文件是两个文件。
源代码
a) OrderBean.java
@Data public class OrderBean implements Writable { private String orderId = ""; private String pid = ""; private int amount; private String pname = ""; /** * 用来区分是order表的封装对象还是product表的封装对象 */ private String flag = ""; @Override public void write(DataOutput dataOutput) throws IOException { dataOutput.writeUTF(orderId); dataOutput.writeUTF(pid); dataOutput.writeInt(amount); dataOutput.writeUTF(pname); dataOutput.writeUTF(flag); } @Override public void readFields(DataInput dataInput) throws IOException { this.orderId = dataInput.readUTF(); this.pid = dataInput.readUTF(); this.amount = dataInput.readInt(); this.pname = dataInput.readUTF(); this.flag = dataInput.readUTF(); } @Override public String toString() { return orderId + " " + pname + " " + amount; } }
b) OrderMapper.java
public class OrderMapper extends Mapper<LongWritable, Text, Text, OrderBean> { /** * 当前切片所在文件名字 */ String fileName; @Override protected void setup(Context context) throws IOException, InterruptedException { // 获得切片 FileSplit fileSplit = (FileSplit) context.getInputSplit(); // 获取切片数据所在文件路径 Path path = fileSplit.getPath(); // 获取文件名 fileName = path.getName(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] array = line.split("\t"); OrderBean ob = new OrderBean(); String file = "order"; if (fileName.contains(file)) { // 如果是订单表,只需要向OrderBean对象中封装:orderId、pid、amount、flag ob.setOrderId(array[0]); ob.setPid(array[1]); ob.setAmount(Integer.parseInt(array[2])); ob.setFlag("order"); } else { // 如果是产品表,只需要向OrderBean对象中封装:pid、flag ob.setPid(array[0]); ob.setPname(array[1]); ob.setFlag("product"); } context.write(new Text(ob.getPid()), ob); } }
c) OrderReduce.java
public class OrderReducer extends Reducer<Text, OrderBean, NullWritable, OrderBean> { /** * @param key 产品id * @param values 产品id相同的订单信息和产品信息 * @param context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Text key, Iterable<OrderBean> values, Context context) throws IOException, InterruptedException { // 订单有多个 List<OrderBean> orders = new ArrayList<>(); // 产品信息只有一个 OrderBean product = new OrderBean(); /** * 在使用增强的for循环时,前面的变量永远都是同一个对象,只不过指向的地址不一样了。 * 如果直接把value的值赋给其他变量,那么value的地址值变化,那么赋值给的变量也就发生变化了 */ for (OrderBean value: values) { // 如果是订单数据,将订单数据加到集合中 if ("order".equals(value.getFlag())) { OrderBean orderBean = new OrderBean(); // 将value中的数据copy到orderBean中。增强的for循环中每一次获取的对象都复制给同一个值,如果加到集合中只能加上一个,所以需要通过这种方式将两个对象区分开 orderBean.setOrderId(value.getOrderId()); orderBean.setPid(value.getPid()); orderBean.setAmount(value.getAmount()); orderBean.setFlag(value.getFlag()); orders.add(orderBean); } else { // 如果是产品信息,那么将产品信息数据赋值给product对象 product.setPid(value.getPid()); product.setPname(value.getPname()); product.setFlag(value.getFlag()); } } // 将订单中的产品名字修改为产品信息中的名字 for (OrderBean order: orders) { order.setPname(product.getPname()); context.write(NullWritable.get(), order); } } }
d) OrderDriver.java
public class OrderDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.218.55:9000"); Job job = Job.getInstance(conf); job.setJarByClass(OrderDriver.class); job.setMapperClass(OrderMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(OrderBean.class); job.setReducerClass(OrderReducer.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(OrderBean.class); FileInputFormat.setInputPaths(job, new Path("/school/join/*")); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), conf, "root"); Path output = new Path("/school/join/test_reduce"); if (fs.exists(output)) { fs.delete(output, true); } FileOutputFormat.setOutputPath(job, output); boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); } }
运行截图

Reduce Join缺点
这种方式中,介于产品表中有可能有几百M数据,但是订单表有可能有几T数据,合并的操作是在reduce阶段完成,reduce端的处理压力太大,map节点的处理逻辑比较简单,运算负载很低,容易导致资源利用率不彻底,且在reduce阶段极易产生数据倾斜。
解决方案:Map Join
Map Join
使用场景
Map Join适用于一张表十分小、一张表很大的场景。
优点
思考:在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜。
具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在驱动函数中加载缓存。
// 缓存普通文件到Task运行节点。
job.addCacheFile(new URI("file://e:/cache/pd.txt"));
Map阶段的join主要用到了一个技术:MR缓存小文件的技术----在Mapper的setup中去处理缓存的小文件即可
案例一:订单信息表
需求
同Reduce Join案例
思路
可以将小表分发到所有的map节点,这样,map节点就可以在本地对自己所读到的大表数据进行合并并输出最终结果,可以大大提高合并操作的并发度,加快处理速度。
这里要求将所有数据都放到Map端处理,处理逻辑为:
1. 在setup()阶段把缓存的小数据读取到内存的集合中,缓存备用
2. 在map()阶段读取大文件(大表 order.txt),根据我们缓存的小表数据进行join操作即可

源代码
1) OrderDriver.java
public class OrderDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.218.55:9000"); Job job = Job.getInstance(conf); job.setJarByClass(OrderDriver.class); job.setMapperClass(OrderMapper.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); job.setNumReduceTasks(0); // 需要把小文件提前缓存下来-----需要在map阶段的setup方法中读取缓存进行数据处理 job.addCacheFile(new URI("/school/join/product.txt")); // 输入文件只需要指定大文件,即订单文件的输入路径即可 FileInputFormat.setInputPaths(job, new Path("/school/join/order.txt")); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), conf, "root"); Path output = new Path("/school/join/test_map"); if (fs.exists(output)) { fs.delete(output, true); } FileOutputFormat.setOutputPath(job, output); boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); } }
2) OrderMapper.java
public class OrderMapper extends Mapper<LongWritable, Text, NullWritable, Text> { Map<String, String> products = new HashMap<>(); /** * 缓存的小文件数据读取、存储集合备用。 * 小文件是产品表,一个字段是pid,一个字段是pname * @param context * @throws IOException * @throws InterruptedException */ @Override protected void setup(Context context) throws IOException, InterruptedException { // 获取缓存的小文件 URI[] cacheFiles = context.getCacheFiles(); URI cacheFile = cacheFiles[0]; // 获取缓存文件的路径 String path = cacheFile.getPath(); try { // 创建一个文件系统,用来获取缓存文件的io流 FileSystem fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), context.getConfiguration(), "root"); // 获取缓存文件的io流 FSDataInputStream open = fs.open(new Path(path)); // 将io流转换为字符缓冲流,可以实现一次读取文件的一行数据 BufferedReader br = new BufferedReader(new InputStreamReader(open)); String line = null; while ((line = br.readLine()) != null) { // 把一行数据切割,得到[1, 小米] String[] array = line.split("\t"); // 将数据传到集合中 products.put(array[0], array[1]); } } catch (URISyntaxException e) { e.printStackTrace(); } } /** * map只需要处理订单表的数据即可 * @param key * @param value * @param context * @throws IOException * @throws InterruptedException */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // order.txt中的一行数据 [1001, 01, 5] String[] array = value.toString().split("\t"); String orderId = array[0]; String pid = array[1]; String amount = array[2]; // 获取产品名---根据订单文件的pid去刚刚缓存下来的产品集合中获取值即可 String pname = products.get(pid); String line = orderId + "\t" + pname + "\t" + amount; context.write(NullWritable.get(), new Text(line)); } }
运行截图

案例二:学生信息表(三表连接)
需求
总共有三张表:一张表是student表,里面存储了学生id,学生所在班级id以及学生的分数;一张表是class表,里面记录了班级id、班级所在系的id、班级名称;一张表是dept表,里面存储了系id以及系名称。
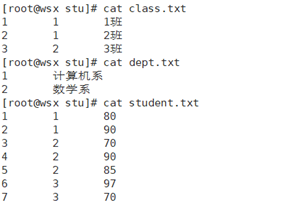
最后要求以“学生id 班级名称 系名称 分数”这样的格式输出到结果文件中。
思路
同案例一,分析需求可以将class表和dept表视作小标,通过缓冲流存储在两个Map集合中,键值都为他们的id,然后在map()方法中读取学生表信息,将学生表中存储的id和Map集合中对应起来,获得到对应的值,最后输出到结果文件中
源代码
1) SchoolDriver.java
public class SchoolDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.218.55:9000"); Job job = Job.getInstance(conf); job.setJarByClass(SchoolDriver.class); job.setMapperClass(SchoolMapper.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); job.setNumReduceTasks(0); job.addCacheFile(new URI("/school/stu/class.txt")); job.addCacheFile(new URI("/school/stu/dept.txt")); FileInputFormat.setInputPaths(job, new Path("/school/stu/student.txt")); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), conf, "root"); Path path = new Path("/test/school/school_map"); if (fs.exists(path)) { fs.delete(path, true); } FileOutputFormat.setOutputPath(job, path); boolean b = job.waitForCompletion(true); System.exit(b ? 0 : 1); } }
2) SchoolMapper.java
public class SchoolMapper extends Mapper<LongWritable, Text, NullWritable, Text> { Map<String, String> dept = new HashMap<>(); Map<String, String[]> cla = new HashMap<>(); @Override protected void setup(Context context) throws IOException, InterruptedException { URI[] cacheFiles = context.getCacheFiles(); URI file1 = cacheFiles[0]; URI file2 = cacheFiles[1]; String path1 = file1.getPath(); String path2 = file2.getPath(); FileSystem fs = FileSystem.get(context.getConfiguration()); FSDataInputStream open1 = fs.open(new Path(path1)); FSDataInputStream open2 = fs.open(new Path(path2)); BufferedReader br1 = new BufferedReader(new InputStreamReader(open1)); BufferedReader br2 = new BufferedReader(new InputStreamReader(open2)); String line = null; while ((line = br1.readLine()) != null) { String[] split = line.split("\t"); cla.put(split[0], new String[]{split[1], split[2]}); } while ((line = br2.readLine()) != null) { String[] split = line.split("\t"); dept.put(split[0], split[1]); } } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] split = line.split("\t"); String[] classInfo = cla.get(split[1]); String sid = split[0]; String className = classInfo[1]; String deptName = dept.get(classInfo[0]); String score = split[2]; String result = sid + "\t" + className + "\t" + deptName + "\t" + score; context.write(NullWritable.get(), new Text(result)); } }
运行截图

