MapReduce框架原理-InputFormat数据输入
InputFormat简介
InputFormat:管控MR程序文件输入到Mapper阶段,主要做两项操作:怎么去切片?怎么将切片数据转换成键值对数据。
InputFormat是一个抽象类,没有实现怎么切片,怎么转换,由它的子类实现。其中InputFormat的默认实现类是FileInputFormat,其也是一个抽象类,没有具体实现,最终是由FileInputFormat的子类去实现的。子类一共有五个,每一个子类的分片机制和转换成key-value键值对数据的格式都不一样,其中默认使用的是 TextInputFormat<K,V>
InputFormat是一个抽象类,里面有两个方法:
- getSplits(JobContext var1):定义了我们的输入文件如何进行切片
- createRecordReader(InputSplit var1, TaskAttemptContext var2):MR程序map阶段的输入是一个key-value键值对,这个方法定义了切片完成之后,MapTask在处理分片数据时如何将切片数据读取成key-value键值对。换句话说,这个方法就是用来做将输入的数据映射成为map阶段的输入的key-value键值对形式的
MR程序在运行的时候分为MapTask阶段和ReduceTask阶段,MapTask和ReduceTask可以有多个,但是存在一个问题:
MapTask到底设置多少个比较合适?
ReduceTask设置多少个比较合适?
MapTask设置多少个是基于什么来设置的?文件内容还是文件大小?
切片与MapTask任务的并行度问题
并行度:在MR运行期间,同时运行了多少个MapTask任务
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
数据块:Block是HDFS物理上把数据分成一块一块。Hadoop2.x版本一个block块默认是128M。假设要存储200MB的数据,则分成两块:0-128MB、128MB-200MB
数据切片:数据切片是MR程序运行的时候才有的一个概念,代表的是将HDFS上的文件数据按照某种算法进行切割,切割的每一块数据我们称之为切片,而且在MR程序中,一个切片需要用一个MapTask任务去处理。切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。
MapTask并行度:MapTask并行度由切片数量决定,切片数量多少,那么MapTask就有多少。
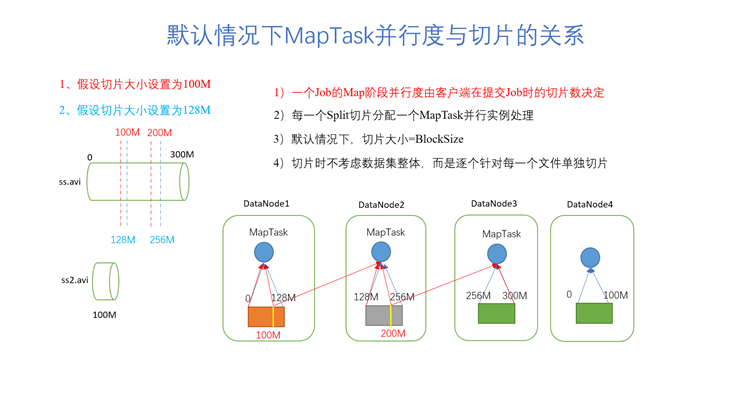
【练习】假设要处理4个文件,第一个文件大小为400M,第二个文件大小为112M,第三个为50M,第四个为200M,对文件进行切片(看MapTask的并行度),切片大小使用默认大小---blocksize大小:128M
【解答】总共有8个切片,即MapTask的并行度为8。第一个文件有四个切片(0-128M、129-256M、257-384M、385-400M),第二个文件有一个切片(0-112M),第三个文件有一个切片(0-50M),第四个文件有两个切片(0-128M,129-200M)
Notes:切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
【问题1】为什么要对数据进行切片?
【答案】切片的主要原因是将一个大文件数据切成多片,每一片启动一个MapTask任务去处理,这样比较快速高效。
【问题2】什么时候切片?切片在什么时机定义的切片规则?
【答案】Driver驱动程序中Job的工作流程
Job提交流程源码
通过debug调试代码,查看Job提交流程:
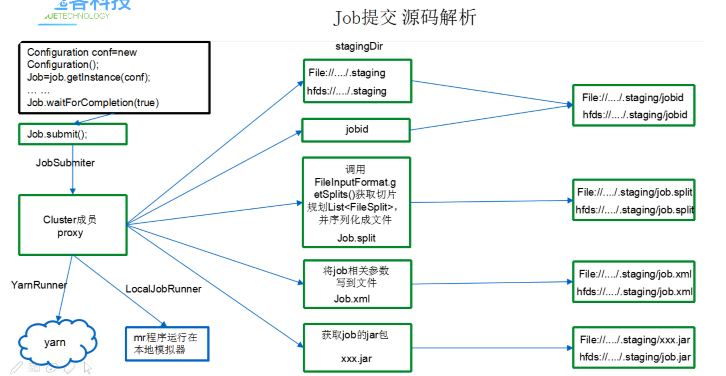
- 创建Cluster对象-----判断代码是在本地运行还是在YARN运行
- 判断输出路径存在与否,存在则报错
- 创建MR程序资源的提交路径(资源:jar包、切片规划文件、job运行的配置参数)----- 主要目的是job在运行任务之后,需要把job中配置的所有配置项还有切片规划文件先上传到一个资源提交路径,job运行时会找这个资源提交路径下的配置文件
- 生成jobID(任务ID):最后资源都是提交在资源提交路径+jobid的文件夹路径下的
-
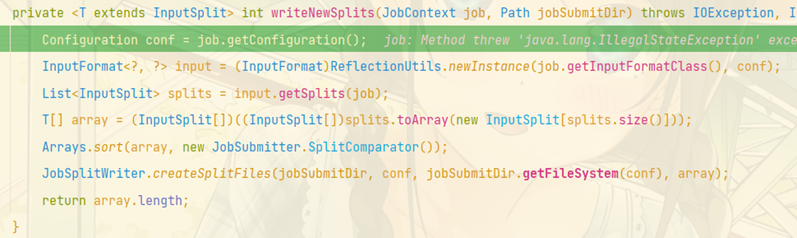
调用InputFormat实现类中的getSplits(),生成切片规划文件,放到提交路径中------FileInputFormat类的切片规划
其中的 int maps = this.writeSplits(job, submitJobDir); 方法定义了FileInputFormat的默认切片机制。
如果没有指定使用的是哪个InputFormat实现类,那么默认调用TextInputFormat实现类进行切片
-
将job依赖的Configuration中的所有配置参数写到job.xml文件中,并将其放在提交路径下
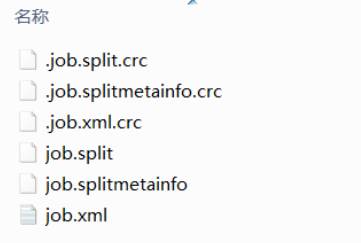
提交之前job的作业目录中会生成以下文件:
- job.split: 当前Job的切片信息,有几个切片对象
- job.splitmetainfo: 切片对象的属性信息
- job.xml: job所有的属性配置
- jar包:仅在集群模式下存在,本地运行环境下没有
- 所有资源全部提交完成,job根据提交路径的资源文件去运行MR程序
job提交详细代码流程:
|
waitForCompletion() submit(); // 1建立连接 connect(); // 1)创建提交job的代理 new Cluster(getConfiguration()); // (1)判断是本地yarn还是远程 initialize(jobTrackAddr, conf); // 2 提交job submitter.submitJobInternal(Job.this, cluster) // 1)创建给集群提交数据的Stag路径 Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); // 2)获取jobid ,并创建job路径 JobID jobId = submitClient.getNewJobID(); // 3)拷贝jar包到集群 copyAndConfigureFiles(job, submitJobDir); rUploader.uploadFiles(job, jobSubmitDir); // 4)计算切片,生成切片规划文件 writeSplits(job, submitJobDir); maps = writeNewSplits(job, jobSubmitDir); input.getSplits(job); // 5)向Stag路径写xml配置文件 writeConf(conf, submitJobFile); conf.writeXml(out); // 6)提交job,返回提交状态 status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials()); |
InputFormat实现子类
InputFormat默认的实现子类也是我们最常用的实现子类:FileInputFormat()。
FileInputFormat()也是一个抽象类,里面并没有定义我们应该怎么去分片,怎么去读取数据成key-value键值对。
FileInputFormat()常用的一共有五个实现子类:
- TextInputFormat<K,V>
- CombineFileInputFormat<K,V>
- KeyValueTextInputFormat<K,V>
- NLineInputFormat<K,V>
-
SequenceFileInputForma<K,V>----只能处理SequenceFile文件
FileInputFormat的切片机制
job提交任务运行过程当中,中间有一部需要调用InputFormat实现类的getSplits()方法去实现切片规划,并且将切片规划写到一个切片规划文件中(job.split)提交到资源路径中
InputFormat实现类有很多,不同的实现类切片机制和输入映射成为key-value键值对的方式都不一样。如果在运行程序时没有指定InputFormat的实现类,那么默认使用TextInputFormat中的切片机制和映射KV方法。
// 定义InputFormat的默认实现类。如果没有定义,默认使用TextInputFormat job.setInputFormatClass(TextInputFormat.class);
FileInputFormat的默认切片机制在JobSubmitter.java的int maps = this.writeSplits(job, submitJobDir); 方法中被定义。
一、切片机制:
- 获取在FileInputFormat中定义的切片的最小值minSize(1B)和最大值maxSize(long.MAX_VALUE)
- 获取输入的文件路径下的所有文件
- 在默认切片机制下,一个文件要进行一次切片计算
- 拿到某一个文件之后先判断一下这个文件可以不可以切片,如果不能,这个文件不管多大都只是一个切片。(在MR中有些压缩包不支持分片,如tar.gz文件不可分片)
- 继续判断如果文件的大小没有超过默认定义切片大小的1.1倍,那么也不切片
-
如果文件可以切片,并且超过了定义的最小切片大小的1.1倍,那么按照切片规则去切片。
如splitSize=100M,文件120M,切片:0-100M,100-120M
-
SplitSize的计算规则:
FileInputFormat.class:Math.max(minSize, Math.min(maxSize, blockSize))
二、切片源码分析
JobSubmitter.class:224行-----定义切片规则

getSplits(job):
while(true) { while(true) { while(i$.hasNext()) { FileStatus file = (FileStatus)i$.next(); Path path = file.getPath(); // 获取文件路径 long length = file.getLen(); // 获取文件长度 if (length != 0L) { BlockLocation[] blkLocations; if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus)file).getBlockLocations(); } else { FileSystem fs = path.getFileSystem(job.getConfiguration()); blkLocations = fs.getFileBlockLocations(file, 0L, length); } if (this.isSplitable(job, path)) { // 判断文件是否可以切片 long blockSize = file.getBlockSize(); // 获取block块的大小 long splitSize = this.computeSplitSize(blockSize, minSize, maxSize); // 计算分片大小 long bytesRemaining; int blkIndex; for(bytesRemaining = length; (double)bytesRemaining / (double)splitSize > 1.1D; bytesRemaining -= splitSize) { // 判断文件的大小有没有超过默认分片大小的1.1倍,如果有则进行下面切片 blkIndex = this.getBlockIndex(blkLocations, length - bytesRemaining); splits.add(this.makeSplit(path, length - bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); } if (bytesRemaining != 0L) { blkIndex = this.getBlockIndex(blkLocations, length - bytesRemaining); splits.add(this.makeSplit(path, length - bytesRemaining, bytesRemaining, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); } } else { splits.add(this.makeSplit(path, 0L, length, blkLocations[0].getHosts(), blkLocations[0].getCachedHosts())); } } else { splits.add(this.makeSplit(path, 0L, length, new String[0])); } } } } protected long computeSplitSize(long blockSize, long minSize, long maxSize) { return Math.max(minSize, Math.min(maxSize, blockSize)); }
三、切片步骤(PPT)


四、FileInputFormat默认的切片大小参数配置

例如:
// 修改默认最大切片大小,下面两种方法都可以 conf.set("mapreduce.input.fileinputformat.split.maxsize", "128"); FileInputFormat.setMaxInputSplitSize(job, 128);
TextInputFormat实现类的使用
InputFormat中有一个抽象子类FileInputFormat:InputFormat中常用的实现类都是FileInputFormat的子类
TextInputFormat是默认的 FilelnputFormat实现类
一、 切片机制
按照文件切片,不看整体数据集,每一个文件单独切片。文件之间按照计算公式切片
二、 切片步骤
- 判断切片能不能切:isSplitable()。一般压缩文件都不能切
- 计算切片的大小:Math.max(minSize, Math.min(maxSize, blockSize))
- 文件切割完成后的剩余部分是不是splitSize的1.1倍,如果不是,那么不切割;如果是,按照splitSize大小切割成两块
三、 数据读取(映射成为key-value键值对的方式)
createRecordReader():记录读取器RecordReader是按行读取每条记录,读取后, 键Key是存储该行在整个文件中的起始字节偏移量, LongWritable类型。值Value是这行的内容,不包括任何行终止符(换行符和回车符),定义为Text类型。这个键值对之后会作为Mapper的输入

CombineTextInputFormat实现类的使用
CombineTextInputFormat是CombineFileInputFormat的实现类。
这个InputFormat的实现类主要作用是为了去合并小文件。如果我们要处理的数据有很多小文件,那么这些小文件在TextInputFormat切片机制下会把一个文件(只要不超过定义的splitSize)成为单独的一个切片。如果针对处理的数据有大量小文件的话,我们就不要使用TextInputFormat实现类了,这样太浪费资源了。Hadoop中提供了一个可以对小文件进行切片的实现类:CombineTextInputFormat
CombineTextInputFormat类的作用
可以将小文件合并成一个或者多个切片处理,避免资源浪费
设置CombineTextInputFormat切片机制
// 定义使用CombineTextInputFormat去实现切片机制,合并小文件 job.setInputFormatClass(CombineTextInputFormat.class); // 需要告诉切片的处理者,每一个切片的大小 CombineTextInputFormat.setMaxInputSplitSize(job, 4*1024*1024);
切片机制
getSplits()。按照数据集的整体来切片,而不是对每一个文件的单独切片。
思想:
将文件在切片过程中划分了两步计算:
- 虚拟存储过程:根据传入的合并文件大小的一个参数,现将文件从逻辑上将每一个文件分片
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
- 切片 :将分出来的每一个片合并和参数作对比,决定最终的每一个切片的大小
因为FileInputFormat是对每个文件进行独立切片,不管文件多小每个文件都会单独产生1个或者多个切片. 而CombineTextInputFormat可以将多个小文件从逻辑上规划到一个切片中,这样就可以只交给一个MapTask处理
过程:
- 判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
- 如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
- 测试举例:有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M),最终会形成3个切片,大小分别为:(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M

数据读取:createRecordReader()
与TextInputFormat一样,都是将每个切片的内容按行读取输出的key为该行在整个文件中的起始字节偏移量, value为该行的内容
KeyValueInputFormat实现类的使用
主要用于处理数据中具有明显的key-value样式的数据
设置KeyValueInputFormat作为切片机制
// 设置KeyValueTextInputFormat切片形式 job.setInputFormatClass(KeyValueTextInputFormat.class); // 设置分隔符,分隔开的前半部分为key,后半部分为value conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " ");
切片机制
与FileInputFormat一致
数据读取
按行读取,按照你给定的分隔符(如果没有规定,则默认是\t制表符)将每一行的数据分隔,第一个字段当做key,剩余字段当成value。所以key是Text类型,value也是Text类型

NlineInputFormat实现类的使用
设置NLineInputFormat作为切片机制
// 设置NLineInputFormat切片形式 job.setInputFormatClass(NLineInputFormat.class); // 设置文件的分隔行数,即几行为一个切片 NLineInputFormat.setNumLinesPerSplit(job, 1);
切片机制
按照文件的行数切割,不管有多少文件。与FileInputFormat不同,它是按设置的行数来切片,也是每一个文件单独切片。5个文件,最少5个切片。
数据读取
而记录读取器RecordReader机制与TextInputFormat的一致。key也是LongWritable类型的,value也是Text类型的

自定义InputFormat
在很多情况下,我们通过这四个实现类并不能把所有的数据处理完成,总有一个文件切片使得转换规则的四个实现类不能应用在某一特殊文件上
MapReduce帮助我们提供了另外一个机制:可以不用这些实现类,自定义一个InputFormat
自定义InputFormat实现KeyValueTextInputFormat的功能:
步骤
- 定义一个InputFormat类继承FileInputFormat
-
重写getSplits()方法和createRecordReader()方法
如果不需要重新定义切片规则,那么就不必去重写
在去重写createRecordReader()方法时,需要我们返回一个RecordReader对象,而这个对象就是Map输入的key-value的封装对象,所以我们应该新建一个自定义的RecordReader类用于继承RecordReader类中的方法并且重写。其中需要继承的方法有5个:
-
initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext)
初始化方法:需要传入一个切片和一个上下文对象,然后才能进行切割:在MyInputFormat中的createRecordReader()方法中调用该方法完成传入
- nextKeyValue()
-
核心方法----用来决定key是什么值,value是什么值。
一个切片有很多数据,如果是按行读取,那么每读取一行会调用这个方法,判断还有没有下一行数据。有则返回true,继续读取;没有则返回false,当前切片数据读取完成
-
getCurrentKey()
获取当前读取的一次数据中的key值
-
getCurrentValue()
读取每一次读取的数据的value值
-
getProgress()
目前的进度-----可以不用写
-
close()
关闭资源
- 在Driver中通过job.setInputFormatClass()去指定自定义的InputFormat类
代码实操
-
MyInputFormat.java
/** * 自定义的InputFormat * @Author: ZYD * @Date: 2021/8/7 上午 11:54 */ public class MyInputFormat extends FileInputFormat<Text, Text> { /** * 如果你觉得他默认的切片机制不满意,可以重写getSplits()方法去规定切片规则,如果满意的话就不需要重写了 * 此时FileInputFormat会调用它默认的切片机制 */ /*@Override public List<InputSplit> getSplits(JobContext job) throws IOException { return super.getSplits(job); }*/ /** * 定义我们读取的切片数据怎么去实现key-value转换规则的 * @param inputSplit------某一个切片 * @param taskAttemptContext-----上下文对象 * @return * @throws IOException * @throws InterruptedException */ @Override public RecordReader<Text, Text> createRecordReader(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException { MyRecordReader myRecordReader = new MyRecordReader(); myRecordReader.initialize(inputSplit, taskAttemptContext); return myRecordReader; } }
-
MyRecordReader.java
/** * 自定义的底层输入的数据转换成key-value的核心方法 * @Author: ZYD * @Date: 2021/8/7 下午 12:02 */ public class MyRecordReader extends RecordReader<Text, Text> { /** * 创建了一个属性,这个对象也是一个RecordReader,只不过他的key是偏移量,value是每一行的数据 * 可以使用这个方法去读取切片中的每一行数据 */ LineRecordReader lineRecordReader = new LineRecordReader(); Text key = new Text(); Text value = new Text(); String split = "\t"; /** * 初始化方法:需要传入一个切片和一个上下文对象,然后才能进行切割:在MyInputFormat中的createRecordReader()方法中调用该方法完成传入 * @param inputSplit:切片对象 * @param taskAttemptContext:切片对象的数据 * @throws IOException-IO流异常 * @throws InterruptedException- */ @Override public void initialize(InputSplit inputSplit, TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException { lineRecordReader.initialize(inputSplit, taskAttemptContext); } /** * 核心方法----用来决定key是什么值,value是什么值 * 一个切片有很多数据,如果是按行读取,那么每读取一行会调用这个方法,判断还有没有下一行数据 * 有则返回true,继续读取;没有则返回false,当前切片数据读取完成 * @return boolean * @throws IOException-IO流异常 * @throws InterruptedException- */ @Override public boolean nextKeyValue() throws IOException, InterruptedException { Text line = null; if (lineRecordReader.nextKeyValue()) { line = lineRecordReader.getCurrentValue(); String[] underSplit = line.toString().split(this.split); key.set(underSplit[0]); int length = underSplit[0].length(); String substring = line.toString().substring(length); value.set(substring); } return line != null; } /** * 获取当前读取的一次数据中的key值 * @return key * @throws IOException- * @throws InterruptedException- */ @Override public Text getCurrentKey() throws IOException, InterruptedException { return key; } /** * 读取每一次读取的数据的value值 * @return value * @throws IOException * @throws InterruptedException */ @Override public Text getCurrentValue() throws IOException, InterruptedException { return value; } /** * 目前的进度-----可以不用写 * @return float * @throws IOException- * @throws InterruptedException- */ @Override public float getProgress() throws IOException, InterruptedException { return 0; } /** * 关闭资源 * @throws IOException- */ @Override public void close() throws IOException { } }

