MapReduce概述
单词计数案例
需求
在一堆给定的文本文件中统计输出每一个单词出现的总次数
环境准备
在 /opt/test 目录下创建一个文件 wordcount.txt ,里面键入几个单词,并用空格分隔开
Java实现
package com.zyd; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.BufferedInputStream; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.URI; import java.net.URISyntaxException; import java.util.HashMap; import java.util.Map; /** * @Author: ZYD * @Date: 2021/7/30 下午 21:28 */ /** * 如果使用Java实现这个单词计数存在的问题: * 1. 操作的数据是HDFS分布式集群,可能这个文件有几个G的大小,如果使用Java,那么我们必须把这些数据全部拉取到JVM内存中去运行,可能会导致Java内存崩溃 * 2. 如果我们不把这些数据全部拉取到本地操作,那么可能会把这个Java程序运行在不同的电脑上执行,只需要处理当前机器上的block块的数据即可 * 但是这样也会存在问题: * Java代码需要分布式的运行在不同的电脑上,那么处理结束之后将面临如何将处理结果汇总起来、如何把控每一个节点上程序有没有运行结束这些问题 */ public class WordCountJava { public static void main(String[] args) { // 1. 连接HDFS集群 Configuration conf = new Configuration(); FileSystem fs = null; try { fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), conf, "root"); /** * 2. 读取文件数据 ----- IO流 * 四个抽象父类: * 字节流:InputStream、OutputStream * 字符流:Reader、Writer */ // 创建单词计数文件的输入流 FSDataInputStream open = fs.open(new Path("/test/wordcount.txt")); // 字节转字符流 InputStreamReader isr = new InputStreamReader(open); BufferedReader br = new BufferedReader(isr); String line; // 准备一个map集合存放数据,数据格式:单词,单词出现的次数 Map<String, Integer> map = new HashMap<>(); // 通过BufferedReader字符缓冲流的readline方法依次读取一行数据 // 将每一行数据按空格分隔,统计次数 /** * 为什么要用(line = br.readLine()) != null 而不用下面的方法? * 之所以使用(line = br.readLine()) != null判断,是因为readline()方法的特性: * readline是用来判断当前行有没有数据,如果有数据的话,那么将这一行的数据赋值给一个String类型的变量,然后将这个指针下移 * 用下面的方法的话,意味着调用了两次readline方法,再调用这个readline方法的时候,他返回的就不是当前行的数据了,而是下一行的数据 * 此时也就代表 line 这个字符串里存储的是第二行的数据 */ while (((line = br.readLine()) != null)) { // while (br.readLine() != null) { // line = br.readLine(); System.out.println(line); String[] words = line.split(" "); /** * 如果单词还没有在map集合添加,name在map集合加入 word,1 * 如果出现,那么在map集合添加 word,以前的次数+1 */ for (String word: words) { if (map.get(word) == null) { map.put(word, 1); } else { map.put(word, map.get(word) + 1); } } } System.out.println(map); } catch (Exception e) { e.printStackTrace(); } finally { if (fs != null) { try { fs.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
Java操作注意事项
- (面试题)通过代码的编写可以发现,在写while循环时,使用了(line = br.readLine()) != null 判断,而不是while (br.readLine() != null) {line = br.readLine(); ……},这是为什么呢?
原因:之所以使用(line = br.readLine()) != null判断,是因为readline()方法的特性:
* readline是用来判断当前行有没有数据,如果有数据的话,那么将这一行的数据赋值给一个String类型的变量,然后将这个指针下移
* 用下面的方法的话,意味着调用了两次readline方法,再调用这个readline方法的时候,他返回的就不是当前行的数据了,而是下一行的数据
* 此时也就代表 line 这个字符串里存储的是第二行的数据
- 使用Java实现这个单词计数存在的问题:
- 操作的数据是HDFS分布式集群,可能这个文件有几个G的大小,如果使用Java,那么我们必须把这些数据全部拉取到JVM内存中去运行,可能会导致Java内存崩溃
- 如果我们不把这些数据全部拉取到本地操作,那么可能会把这个Java程序运行在不同的电脑上执行,只需要处理当前机器上的block块的数据即可。但是这样也会存在问题:Java代码需要分布式的运行在不同的电脑上,那么处理结束之后将面临如何将处理结果汇总起来、如何把控每一个节点上程序有没有运行结束这些问题
MapReduce实现
编写MR程序过程:
- 编写Mapper阶段:继承Mapper类,定义好数据的输入和输出类型
- 编写Reducer阶段:继承Reducer类,定义好数据的输入和输出类型
- 编写Driver类:程序的运行入口,将Mapper阶段和Reducer阶段关联圈起来,并且定义输入文件和输出文件地址
源代码:
1. WordCountMapper.java
package MapReduce; /** * @Author: ZYD * @Date: 2021/8/1 下午 22:44 */ import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * 第一步:继承Mapper类(定义数据的输入格式和数据的输出形式) * 如果要使用MR程序,我们要指定数据输入的kye-value键值对类型 * 同时要指定数据输出的key-value键值对类型 * Mapper阶段----一行数据执行一次Mapper * Mapper阶段的输入key-value键值对格式很固定:LongWritable Text * 其中LongWritable 是 long 基本数据类型的hadoop序列化的类,一般情况下Map阶段的key代表的是文件的偏移量----理解为行号 * Text 是String类型的hadoop序列化类,代表的是每一行的数据 * */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> { /** * mapTask的核心处理逻辑: * 每一行文件数据需要走一个map方法 * @param key ----- Mapper阶段输入的key值-----行号 * @param value -----Mapper阶段输入的value值-----当前行对应的字符串数据 * @param context ------上下文对象,主要功能是为了实现将Map阶段的数据输入到Reduce阶段 * @throws IOException * @throws InterruptedException */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 第一步:将每一行数据value按照空格切割,然后将每一个得到的单词当做 key,1当做value,将他们输出到Reduce阶段 String line = value.toString(); String[] words = line.split(" "); for (String word: words) { // 将每一行数据空格切割后的单词以单词为key,1为value输出到reduce阶段 // 到了reduce阶段,会根据key值将value给聚合起来 context.write(new Text(word), new LongWritable(1)); } } }
2. WordCountReducer.java
package MapReduce; /** * @Author: ZYD * @Date: 2021/8/1 下午 23:01 */ import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.Iterator; /** * 继承Reducer类 * Reducer类也粗腰指定输入的key-value的数据类型,也需要指定输出的key-value数据类型 * * 此时Reducer阶段的输入的key-value键值对类型不能随便指定,它应该是Mapper阶段的输出数据类型 */ public class WordCountReduce extends Reducer<Text, LongWritable, Text, LongWritable> { /** * reduceTask核心处理业务逻辑的方法 * 他是每一组key值相同的数据执行一次 * @param key ------ map阶段输出的key值 ---- 单词 * @param values ------ values是一个类似于集合的数据,里面放的是key相同的数据的所有value值的集合 * @param context ------ 上下文对象,将结果以<key, value>键值对的形式输出到最终的结果文件中 * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { /** * 思路:将values中的数据累加起来 ,这样的话单词对应出现的次数就确定了 */ Iterator<LongWritable> iterator = values.iterator(); long result = 0L; while (iterator.hasNext()) { LongWritable next = iterator.next(); result += next.get(); } context.write(key, new LongWritable(result)); } }
3. WordCountDriver.java
package MapReduce; /** * @Author: ZYD * @Date: 2021/8/1 下午 23:01 */ import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.Iterator; /** * 继承Reducer类 * Reducer类也粗腰指定输入的key-value的数据类型,也需要指定输出的key-value数据类型 * * 此时Reducer阶段的输入的key-value键值对类型不能随便指定,它应该是Mapper阶段的输出数据类型 */ public class WordCountReduce extends Reducer<Text, LongWritable, Text, LongWritable> { /** * reduceTask核心处理业务逻辑的方法 * 他是每一组key值相同的数据执行一次 * @param key ------ map阶段输出的key值 ---- 单词 * @param values ------ values是一个类似于集合的数据,里面放的是key相同的数据的所有value值的集合 * @param context ------ 上下文对象,将结果以<key, value>键值对的形式输出到最终的结果文件中 * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { /** * 思路:将values中的数据累加起来 ,这样的话单词对应出现的次数就确定了 */ Iterator<LongWritable> iterator = values.iterator(); long result = 0L; while (iterator.hasNext()) { LongWritable next = iterator.next(); result += next.get(); } context.write(key, new LongWritable(result)); } }
为什么要使用MapReduce
- 海量数据在单机上处理因为硬件资源限制,无法胜任
- 而一旦将单机版程序(普通程序)扩展到集群在分布式运行,将极大增加程序的复杂度和开发难度
- 引入MapReduce框架(本身就是分布式)后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将分布式计算中的复杂性交由框架来处理
分布式方案考虑的问题:
- 运行逻辑要不要先分后合(先把代码运行在不同的服务器上,最终将结果合并起来)
- 程序如何分配运算任务(切片)
- 两个阶段的程序如何启动?如何协调?
- 整个程序运行过程中的监控?容错?重试?
分布式方案需要考虑很多问题,但是我们可以将分布式程序中的公共功能封装成框架,让开发人员将精力集中在业务逻辑上,而MapReduce就是这样一个分布式程序的通用框架
MapReduce核心思想-----分而治之,先分后合
分布式的运算程序需要分成至少两个阶段:
- 将程序分布在不同的节点(电脑)上,将不同节点的程序相互运算出结果(完全并行运行),互不相干 -------- maptask阶段
- 并行运行,这一阶段数据需要依赖于上一阶段的并发实例的输出(即maptask阶段全部执行完毕才可以开始这一阶段)-------- reducetask阶段'
MapReduce编程模型只能包含一个map阶段和一个reduce阶段,如果用户业务逻辑非常复杂,那就只能使用多个MapReduce程序串行运行
Notes:Reduce Task的个数由业务来决定'
MapReduce进程
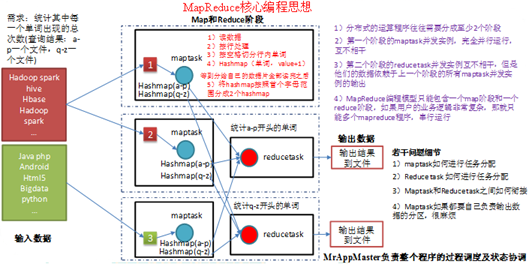
一个完整的mapreduce程序在分布式运行时有三类实例进程:
- MrAppMaster:负责整个程序的过程调度及状态协调(YARN),是程序的管理者,管理Map和Reduce任务
- MapTask:负责map阶段的整个数据处理流程(只分,不合),将程序运行在不同节点上,每个节点只负责一部分数据, 并行运行,互不干扰
- ReduceTask:负责reduce阶段的整个数据处理流程,将Mapper阶段处理完成的数据合并起来处理,也可以有多个reduce,并且多个reduce之间是并行运行,互不干扰的,但是reduce的执行需要依赖map阶段的数据
MapReduce编程规范(八股文)
用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端)------三步编程法
Mapper阶段----编写Mapper类,即MapTask任务
- 用户自定义的Mapper要继承自己的父类
- Mapper的输入数据是KV对的形式(KV的类型可自定义)
- Mapper中的业务逻辑写在map()方法中
- Mapper的输出数据是KV对的形式(KV的类型可自定义)
- map()方法(maptask进程)对每一个<K,V>调用一次(即一行调用一次map方法)
Reducer阶段----编写Reducer类,即ReduceTask任务
- 用户自定义的Reducer要继承自己的父类
- Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
- Reducer的业务逻辑写在reduce()方法中
- Reducetask进程对每一组相同k的<k,v>组调用一次reduce()方法(一个key调用一次reduce方法)
Driver阶段----关联MapTask和ReduceTask任务,并且提交运行
整个程序需要一个Drvier来进行提交,提交的是一个描述了各种必要信息的job对象
Notes:
- MapReduce程序处理的数据大部分都是HDFS上的文件数据
- Map阶段和Reduce阶段数据都需要通过key-value键值对形式进行输入和输出
- 一般情况下Map阶段的输出的key-value的键值对就是Reducer阶段输出的key-value键值对
- 一般情况下一个MapReduce程序只能有一个Map阶段和一个Reduce阶段,如果程序复杂,需要编写多个MR程序串行运行
MapReduce程序运行流程
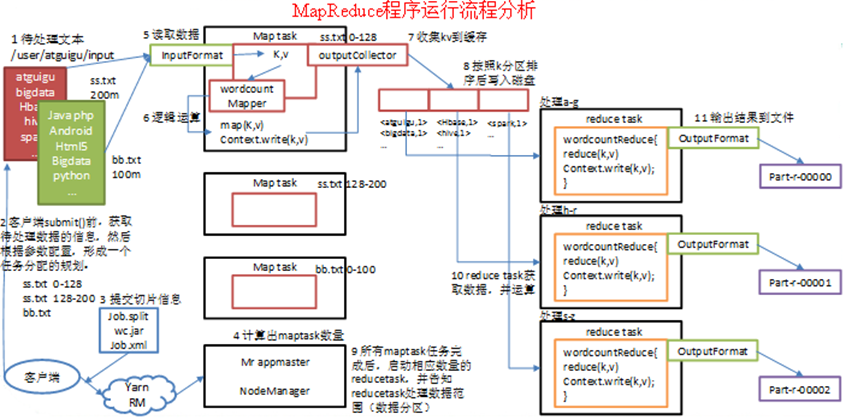
首先将存储在文件中的数据分片(假设分为三片),之后三个maptask同时作业,当所有maptask任务完成后,启动相应数量的ReduceTask,并告知ReduceTask处理数据的范围(数据分区)
1) 在MapReduce程序读取文件的输入目录上存放相应的文件。客户端程序在submit()方法执行前,获取待处理的数据信息,然后根据集群中参数的配置形成一个任务分配规划。
2) 客户端提交job.split、jar包、job.xml等文件给yarn,yarn中的resourcemanager启动MRAppMaster。
3) MRAppMaster启动后根据本次job的描述信息,计算出需要的maptask实例数量,然后向集群申请机器启动相应数量的maptask进程。
4) maptask利用客户指定的inputformat来读取数据,形成输入KV对。
5) maptask将输入KV对传递给客户定义的map()方法,做逻辑运算
6) map()运算完毕后将KV对收集到maptask缓存。
7) maptask缓存中的KV对按照K分区排序后不断写到磁盘文件
8) MRAppMaster监控到所有maptask进程任务完成之后,会根据客户指定的参数启动相应数量的reducetask进程,并告知reducetask进程要处理的数据分区。
9) Reducetask进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台maptask运行所在机器上获取到若干个maptask输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算。
10) Reducetask运算完毕后,调用客户指定的outputformat将结果数据输出到外部存储。

