HDFS的Java API操作
通过Java代码操作HDFS集群
目录
连接HDFS文件系统------是必备操作(见二、idea连接HDFS)
引言
要想在Windows上操作HDFS,首先需要在Windows上安装HDFS。由于Hadoop官网没有提供Windows下载版本,所以需要对 Hadoop.tar.gz进行两次解压(推荐用7-zip软件),解压完成后添加相应环境变量:HADOOP_HOME、Path
Idea连接HDFS
第一步:引入HDFS依赖
第一种引入方式(jar包)
自己找jar包然后插入程序中(HDFS编程所需jar包都在Hadoop安装目录的share目录下,此处将jar包归类了三个文件夹)



导入到idea中:
第二种引入方式(使用maven引用)
maven项目创建后是如下结构:
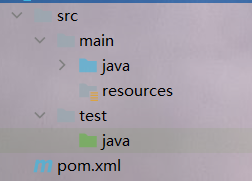
其中:
src
main
java:Java源代码
resource:Java中的一些静态紫竹院,如文件、图片、HTML文件等
test
Java:专门用来编写Java Junit单元测试代码
引入项目依赖的时候:
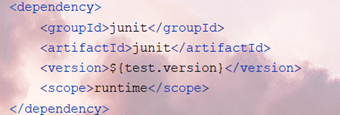
gav....
scope:引入的依赖jar包的一个作用范围
runtime:项目运行过程中也要使用
test:项目在测试过程中才能去使用
provided:项目在编译时和运行时都起作用
maven项目的几个核心的生命周期:

clean:清楚上一次编译的结果
compile:编译源代码
test:执行maven项目的test包下的单元测试代码
package:如果test阶段测试通过,那么将项目打包成对应的包
install:创建maven项目的时候也指定了当前项目的gav坐标,执行install之后会将项目放入本地的maven仓库
第二步:idea操作
引入配置文件,指定我们在去连接HDFS的时候我们应该采取什么样的配置:
import org.apache.hadoop.conf.Configuration; Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.218.55:9000");
这个操作就是配置HDFS文件的core-site.xml

- 根据配置项获取文件系统
import org.apache.hadoop.fs.FileSystem; FileSystem = FileSystem.get(conf);
此时运行程序,控制台显示
![]()
说明运行成功,此时可以通过fileSystem实现对HDFS的远程操作。例如:
(1)创建一个目录
Path pm = new Path("/test"); fileSystem.mkdirs(pm);
(2)创建一个文件
Path pf = new Path("/a.txt"); fileSystem.create(pf);
Notes:此处进行操作时有可能报的错误:

这个错误产生的原因是:在 / 这个目录下只有root用户能进行 rwx 操作,而用本机的idea进行操作时使用的是Windows的当前用户,故需要将该目录设置为:所有用户都可以进行 rwx 操作。
还可能产生一个错误:HADOOP_HOME and Hadoop.home.dir are unset. 这个错误是找不到 HADOOP_HOME的配置路径,如果配置没问题但是还是出错的话(有可能是电脑版本型号的问题),可以直接在idea中配置好Hadoop所在目录:
conf.set("hadoop.home.dir", "d:\\software\\hadoop");
单元测试
在编写Java代码的时候,如果想要运行一个Java程序,那么必须创建一个main方法,比较麻烦,比如现在想要测试HDFS的JavaAPI的文件上传 和文件下载 的功能,那如果使用main方法,我们需要创建两个Java类,比较复杂,后期找的时候也比较麻烦。因此在Java中提供了一个工具-----Junit单元测试
单元测试是属于Java的一个测试方法,最直接的表现形式就是在一个Java文件中可以创建多个“main”方法,如果想要使用单元测试,那么必须引入单元测试的jar包
单元测试最大的特点就是可以让Java中的普通方法拥有main方法的权利。使用方法:在方法前加入注解:@Test / @Before / @After
@Test:注解就是给Java类的普通方法增加main方法的执行权限,并且在运行的时候只会运行当前的这个方法单元,在一个类中可以存在多个方法单元
@Before:此处补充一个概念:代码块:有一个特点,在执行构造器时先执行代码块。而@Before方法类似于Java中的代码块,@Test单元测试方法执行之前必须先执行@Before修饰的方法中的内容。通常做一些前提准备
@After:在@Test修饰的单元测试代码方法执行完成之后,会调用@After修饰的方法。通常做一些销毁工作
HDFS的JavaAPI基本操作
Maven依赖准备
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <hadoop.version>2.8.5</hadoop.version> </properties> <!--引入单元测试需要的jar包--> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13.1</version> <scope>compile</scope> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.19</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>${hadoop.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> </dependencies>
hdfs文件系统的API使用
注意:这些类都在hadoop包下
- Configuration类:HDFS的配置相关类,等同于hadoop中的*-site.xml中的配置。配置文件在代码中采用类似于map集合的key-value键值对的表现形式。配置文件当中配置的配置项执行的优先级要高于我们在Hadoop软件中的配置
- FileSystem类:HDFS文件系统对应的Java类,可以通过这个类获取HDFS上的任何文件和目录
copyFromLocalFile
copyToLocalFile
moveFromLocalFile
moveToLocalFile
rename
delete
mkdirs
listFiles
listStatus
- Path类:是HDFS上文件在Java中的一个抽象表示,类似于File类
- FileStatus(LocatedFileStatus):里面包含文件的详情信息(文件路径、文件权限、文件用户、文件修改时间、文件大小等)
操作HDFS:
-
连接HDFS文件系统------是必备操作(见二、idea连接HDFS)
-
对HDFS进行操作
- FileSystem
- 文件上传
命令:moveFromLocal、copyFromLocal、put
javaAPI:copyFromLocalFile(Path, Path):复制文件
moveFromLocalFile(Path, Path):剪切文件 - 文件下载
命令:copyToLocal、moveToLocal、get
JavaAPI:copyToLocalFile(Path, Path)
moveToLocalFile(Path, Path) - 文件删除
命令:-rm -r -rmdir
JavaAPI:delete(Path, boolean) - 创建文件夹
命令:mkdir -p
JavaAPI:mkdirs(Path) - 更改文件名
命令:mv 文件路径 更改重命名的文件路径
JavaAPI:rename(Path, Path) - 查询某一路径下的文件,可以递归:listFiles
- 查询某一路径下文件或文件夹,不可以递归:listStatus(常用)
- 文件上传
- FileStatus(LocatedFileStatus):里面包含了文件的详情信息:文件路径、文件权限、文件用户、文件修改时间、文件大小....
- 案例:
- FileSystem
public class HDFSTestDemo { private FileSystem fs; @Before public void init() { // hdfs的连接配置 Configuration conf = new Configuration(); // 配置hdfs副本数 conf.set("dfs.replication", "1"); // 配置hdfs的地址----就是NameNode的地址,NameNode的地址在core-site.xml文件中配置的fs.defaultFS // conf.set("fs.defaultFS", "hdfs://192.168.218.55:9000"); // 获取文件系统 try { // fs = FileSystem.get(conf); fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), conf, "root"); System.out.println(fs); System.out.println("文件系统获取成功"); } catch (IOException | URISyntaxException | InterruptedException e) { e.printStackTrace(); } } /** * 文件上传测试 */ @Test public void upload() { Path localSrc = new Path("C:\\Users\\15336\\Desktop\\mm.txt"); Path linuxDe = new Path("hdfs://192.168.218.55:9000/test"); try { fs.copyFromLocalFile(localSrc, linuxDe); System.out.println("文件上传成功"); } catch (IOException e) { e.printStackTrace(); } } /** * 文件下载测试 */ @Test public void download() { Path localDst = new Path("E:\\"); Path linuxSrc = new Path("hdfs://192.168.218.55:9000/test/mm.txt"); try { fs.copyToLocalFile(linuxSrc, localDst); System.out.println("文件下载成功"); } catch (IOException e) { e.printStackTrace(); } } /** * 创建目录 */ @Test public void mkdir() throws IOException { boolean mkdirs = fs.mkdirs(new Path("hdfs://192.168.218.55:9000/test/school")); if (mkdirs) { System.out.println("目录创建成功"); } } /** * 删除目录 */ @Test public void delete() throws IOException { /** * 需要传入两个参数 * @params1: 目录路径 * @params2: boolean类型的值,代表是否递归删除(如果要删除多层目录,则为true) */ boolean delete = fs.delete(new Path("hdfs://192.168.218.55:9000/school"), false); if (delete) { System.out.println("删除成功"); } } /** * 重命名或更改文件目录 */ @Test public void rename() throws IOException { boolean rename = fs.rename(new Path("hdfs://192.168.218.55:9000/test/mm.txt"), new Path("hdfs://192.168.218.55:9000/test/vv.txt")); if (rename) { System.out.println("重命名成功"); } } /** * 查看HDFS文件系统上有哪些文件和文件夹 */ @Test public void listFiles() throws IOException { /** * listFiles 只是查询文件的,目录不能查询 * Path:查询的是哪一个路径 * boolean:如果这个路径下有一个子文件夹,那么是否把这个子文件夹也遍历查询一下,true是遍历查询,false不是 * * * RemoteIterator接口是一个迭代器(有我们查询出来的所有文件信息),它有两个方法: * hasNext():判断有没有下一个文件 * next():获取下一个文件 */ RemoteIterator<LocatedFileStatus> files = fs.listFiles(new Path("hdfs://192.168.218.55:9000/test"), true); while (files.hasNext()) { LocatedFileStatus next = files.next(); System.out.println(next.getPath()); } } /** * 查询hdfs文件系统上的某一文件夹下有哪些文件和文件夹,不能递归 */ @Test public void listAll() throws IOException { /** * listStatus(Path) 代表的是查看当前路径下有哪些文件和文件夹 * 返回值:FileStatus[] 文件状态的一个数组 FileStatus 就代表一个文件的状态:是文件还是文件夹、路径、权限等等 */ FileStatus[] fileStatuses = fs.listStatus(new Path("hdfs://192.168.218.55:9000/test")); for (FileStatus: fileStatuses) { /** * fileStatus是一个文件状态对象,里面有很多方法去获取文件的相关信息 */ System.out.println("文件路径:" + fileStatus.getPath()); System.out.println("文件权限:" + fileStatus.getPermission()); System.out.println("文件所属用户:" + fileStatus.getOwner()); System.out.println("文件所属组:" + fileStatus.getGroup()); System.out.println("文件大小:" + fileStatus.getLen()); System.out.println("文件修改时间:" + fileStatus.getModificationTime()); System.out.println("文件副本数:" + fileStatus.getReplication()); System.out.println("判断是不是一个文件" + fileStatus.isFile()); System.out.println("判断是不是一个目录" + fileStatus.isDirectory()); } } /** * 销毁资源 */ @After public void destroy() { if (fs != null) { try { fs.close(); } catch (IOException e) { e.printStackTrace(); } } } }
递归获取HDFS所有文件
遍历某一个路径下的所有文件和文件夹
* 递归:
* 如果一个文件夹下有文件的话,那么文件的权限直接打印
* 如果是一个文件夹,那么对这个文件夹遍历
public class ListPathAllFile { public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException { // hadoop的配置文件,执行的优先级最高 Configuration conf = new Configuration(); // 连接文件系统 FileSystem fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), conf, "root"); Path p = new Path("/"); /** * 以前判断一个文件是file还是目录,我们使用的是FileStatus里面的isFile() / isDirectory() * FileSystem中也提供了两个方法,用来判断是文件还是文件夹 * isFile(Path path) * isDirectory(Path path) */ listStatus(fs, p); } public static void listStatus(FileSystem fs, Path path) throws IOException { if (fs.isFile(path)) { System.out.println("有一个文件是:" + path.toString()); } else if (fs.isDirectory(path)) { System.out.println("有一个目录:" + path.toString()); FileStatus[] fileStatuses = fs.listStatus(path); for (FileStatus fss: fileStatuses) { Path path1 = fss.getPath(); listStatus(fs, path1); } } } }
FileSystem其他方法
- createNewFile(Path):创建一个文件
- create(Path):根据HDFS上的一个文件file创建一个文件输出流,然后就可以通过IO流的方式将数据传输到本地
- isFile(Path):判断一个文件是不是file
- isDirectory(Path):判断一个文件是不是目录(文件夹)
- exists(Path):查看路径是否存在
- getFileStatus(Path)):查看某个文件或者文件夹的状态
- createNewFile(Path):创建一个文件
IO流操作HDFS
利用IO流实现文件的上传和下载
- 使用IO流完成文件的上传
FileSystem
create(Path, boolean):根据HDFS文件创建一个文件输出流,可以实现一个流的数据输出到HDFS这个文件系统中
public void testUpload() throws IOException { FileInputStream fis = new FileInputStream(new File("E:\\college_data.txt")); // 如果想要通过IO流实现文件的上传,指定overwrite为false,那么hdfs上的文件路径不能提前存在,否则报错 // 如果指定为true(即追加),则不报错 FSDataOutputStream = fs.create(new Path("/test/college_data.txt"), false); IOUtils.copyBytes(fis, fsDataOutputStream, 1024); System.out.println("文件上传完成"); }
- 使用IO流完成文件的下载
FileSystem:open():用来返回一个文件对应的输入流
public void testIODownload() throws IOException { FSDataInputStream fis = fs.open(new Path("/test/d.txt")); FileOutputStream fos = new FileOutputStream("E:\\b.txt"); IOUtils.copyBytes(fis, fos, 1024); System.out.println("文件下载成功"); }
利用IO流实现定位文件读取
Notes:HDFS存储的文件都是以block块存储的,一个block块默认是128M。假设有一个200M的文件上传到HDFS上,有两个block快,一个是128M,一个是72M(应该有128M,实际占用了72M)
使用IO流实现文件的定位读取意思就是比如一个文件分成了两个block快,那么我先下载第一个block块,之后再下载第二个block块
public class IOHDFSTest2 { public static void main(String[] args) throws URISyntaxException, IOException, InterruptedException { /** * 使用IO流完成文件的定位下载 * 比如一个文件分成了两个block快,那么我先下载第一个block块,之后再下载第二个block块 */ Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), conf, "root"); FSDataInputStream open = fs.open(new Path("/test/hadoop-2.8.5.tar.gz")); /** * 下载第一个block块:128M */ FileOutputStream fos = new FileOutputStream("E:\\part1.tar.gz"); byte[] buf = new byte[1024]; for (int i = 0; i < 128 * 1024; i++) { open.read(buf); fos.write(buf); } /** * 下载第二个block块:从128M开始 */ FileOutputStream fos1 = new FileOutputStream("E:\\part2.tar.gz"); /** * 定位到128M的位置,定位之后只用IO流开始下载 */ // 定位偏移量 open.seek(128 * 1024 * 1024); IOUtils.copyBytes(open, fos1, 1024); } }

