Python爬虫学习——1.爬虫入门
HTTP和HTTPS
HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。
HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTTP下加入SSL层。
SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
HTTP的端口号为80,HTTPS的端口号为443
HTTP请求方式
- get请求:从服务器上获取指定页面信息
特点:比较便捷
缺点:不安全,参数的长度有限制
- post请求:向服务器提交数据并获取页面信息
特点:比较安全,数据整体没有限制,通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传操作等)
当发送网络请求时(需要带一定的数据给服务器,不带数据也可以),会看到请求头:request header和客户端返回数据的相应:response
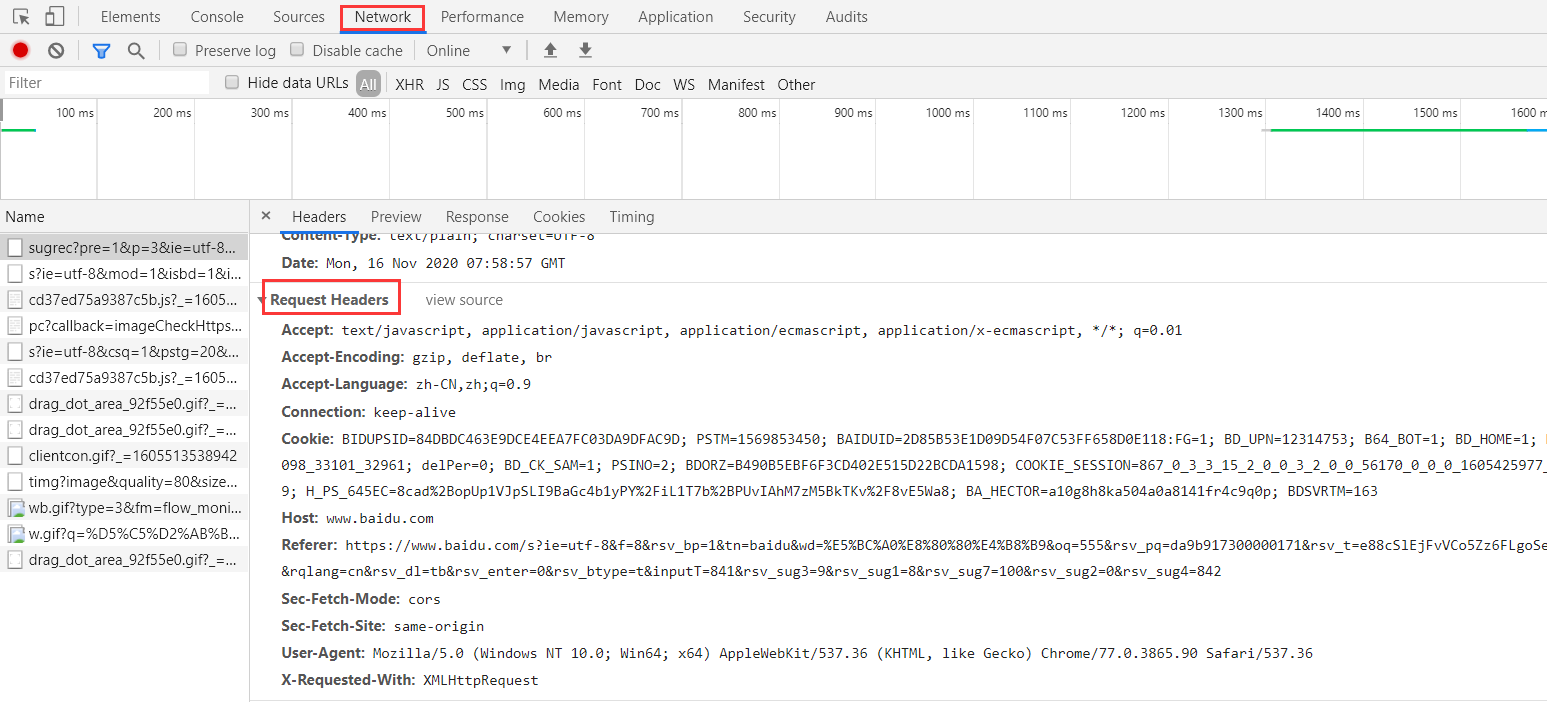
request headers包含信息:
- Accept:文本的格式
- Accept-Encoding:编码格式
- Connection:长链接/短链接
- Cookie:验证用的信息
- Host:域名
- Referer:标志从那个页面跳转过来的
- User-Agent:浏览器和用户的信息
爬虫入门
1. 什么是爬虫?
使用代码模拟用户,批量的发送网络请求,批量的获取数据。
2. 爬虫的价值?
买卖数据(高端的领域价格昂贵!!);数据分析;流量;......
3. 爬虫的合法性?
灰色产业(没有法律明确规定是否违法)。
4. 爬虫可以爬取所有东西吗?
不可以。爬虫只能怕去到用户所能访问到的信息。如腾讯视频vip用户可以爬取vip视频,普通用户只可爬取非vip的视频。
5. 爬虫的分类?
- 通用爬虫:使用搜索引擎
- 优势:开放性,速度快
- 劣势:目标不明确,返回内容大多用户不需要,不清楚用户的需求
- 聚焦爬虫!!!
- 优势:目标明确,能够精准捕捉用户需求,返回的内容固定
6. 爬虫的工作原理 ?
(1)确认你抓取目标的url是哪一个
(2)使用Python代码发送网络请求来获取数据
(3)解析获取到的数据(精确数据)
(4)数据持久化(将数据存储在本地)
学习课程:B站《廖雪峰爬虫》
