MySQL数据库之数据类型和完整性约束
补充:
select * from mysql.user #显示出来乱了 select * from mysql.user\G #加了\G后一行一行显示了
一.数据类型:分不同种类去存不同类型的数据
存储引擎决定了表的类型,而表内存放的数据也要有不同的类型,美中数据类型都有自己的宽度,但宽度是可选的
1.数字(默认是有符号的)
数字又分为:
整型:tinyint(小整型):一个字节
int(整型):四个字节.注意:int的宽度指的是显示宽度,与存储无关
bigint(大整型):八个字节
======================================== tinyint[(m)] [unsigned] [zerofill] 小整数,数据类型用于保存一些范围的整数数值范围: 有符号: -128 ~ 127 无符号:0~ 255 PS: MySQL中无布尔值,使用tinyint(1)构造。 [unsigned]参数和[zerofill]参数的应用 3.将有符号的修改为无符号的:alter table t1 modify unsigned;(注意,如果里面有值了, 得把里面的值清空了再修改) 4.alter table t2 modify id int(10) zerofill; 如果显示不够,就用zerofill填充 ======================================== int[(m)][unsigned][zerofill] 整数,数据类型用于保存一些范围的整数数值范围: 有符号: -2147483648 ~ 2147483647 无符号:0~ 4294967295 ======================================== bigint[(m)][unsigned][zerofill] 大整数,数据类型用于保存一些范围的整数数值范围: 有符号:-9223372036854775808 ~ 9223372036854775807 无符号: 0~ 18446744073709551615
小数:
float:在为数比较短的情况下不精准(****数值越大,越不准确****)
double:在位数比较长的情况下不精准(****数值越大,越不准确****)
decimal:如果是小数,则推荐使用decimal
因为精准,内部原理是以字符串的形式去存


先创建一个数据库:create datdabase test; -----------验证1:int,tinyint,bigint---- create table t1(id tinyint); create table t1(id int); create table t1(id bigint); #如果数字比较大的时候就用bigint 1.如果没有指定符号。默认的是有符号的 2.insert into t1(-129) #就会报错了,因为范围是-128~127 3.将有符号的修改为无符号的:alter table t1 modify unsigned;(注意,如果里面有值了,得把里面的值清空了再修改) 4.alter table t2 modify id int(10) zerofill; 如果显示不够,就用zerofill填充 5.宽度:跟存的没有关系,指的是显示的宽度 ----------验证2:float,double------ create table t3(salary float(5,2)) #5代表salary总共多宽,2代表小数点后保留2位,那么整数部分有3位 insert into t3 values(3.725454); insert into t3 values(-3.725454); insert into t3 values(1111.725454); #像这个就会报错了 insert into t3 values(111.725454); bit类型了解就好了 bit类型:代表二进制的类型 ----------验证3:bit-------- create table t3(x bit); insert into t3 values(0),(1); insert into t3 values(0),(2)); #只能存二进制的,这样的话就会报错 select * from t3;
最后:整型类型,其实没有必要指定显示宽度,使用默认的就ok
2.字符
char:简单粗暴,不够就用空格凑够固定长度存放起来,浪费空间,但是存储速度快(牺牲空间,提高速度)
varchar(你有几个就存几个):精准,计算出带存放数据的长度,节省空间,存取速度慢(牺牲速度,提高效率)
1.----------------- create table t6(name char(4)); insert into t6 values('alexsb'); insert into t6 values('欧德博爱'); insert into abc values('艾利克斯a'); 2.------------- create table t7(x char(5),y varchar(5)); insert into t7 values('sff','aaaaa'); select char_length(x),char_length(y) from t7; 查看字符长度 set sql_mode='pad_char_to_full_length'; #打回原形 insert into t7 values('你好啊','好好好!');#utf-8里面一个汉字代表三个字节,那'你好啊'就代表九个, #加上两个空格就是11个字节 select length(x),length(y) from t7; 查看字节长度
查看字符长度
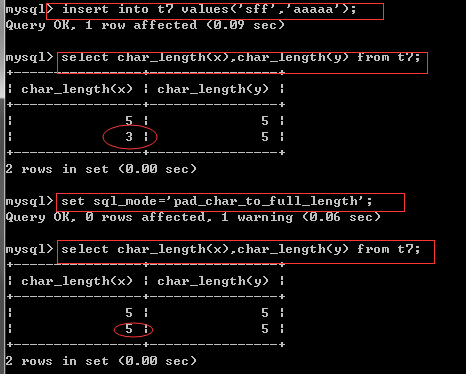
查看字节的长度

3.日期
作用:存储用户注册时间,文章发布时间,员工入职时间,出生时间,过期时间等
有下面几种类型:
datatime:2017-09-06 10:30:22
data:2017-09-06
time:10:30:22
year:2017
timeatamp:和datatime是一样的,就是支持的范围比datatime的大
---------------验证4:日期类型------- create table stu( id int, name char(5), born_data date, born_year year, reg_time datetime, class_time time ); insert into stu values(1,'ao',now(),now(),now(),now()); insert into stu values(1,'xiao','2017-09-06','2017','2017-09-06 10:39:00','08:30:00'); #了解 insert into stu values(1,'alex','2017-09-06',2017,'2017-09-06 10:39:00','08:30:00'); insert into stu values(1,'alex','2017/09/06',2017,'2017-09-06 10:39:00','08:30:00'); 没有-的可以不用加引号 insert into stu values(1,'alex','20170906',2017,'20170906103900','083000'); 也可以吧符号取了连写 ============注意啦,注意啦,注意啦=========== 1. 单独插入时间时,需要以字符串的形式,按照对应的格式插入 2. 插入年份时,尽量使用4位值 3. 插入两位年份时,<=69,以20开头,比如50, 结果2050 >=70,以19开头,比如71,结果1971 MariaDB [db1]> create table t12(y year); MariaDB [db1]> insert into t12 values -> (50), -> (71); MariaDB [db1]> select * from t12; +------+ | y | +------+ | 2050 | | 1971 | +------+
在实际应用的很多场景中,MySQL的这两种日期类型都能够满足我们的需要,存储精度都为秒,但在某些情况下,会展现出他们各自的优劣。下面就来总结一下两种日期类型的区别。 1.DATETIME的日期范围是1001——9999年,TIMESTAMP的时间范围是1970——2038年。 2.DATETIME存储时间与时区无关,TIMESTAMP存储时间与时区有关,显示的值也依赖于时区。在mysql服务器,操作系统以及客户端连接都有时区的设置。 3.DATETIME使用8字节的存储空间,TIMESTAMP的存储空间为4字节。因此,TIMESTAMP比DATETIME的空间利用率更高。 4.DATETIME的默认值为null;TIMESTAMP的字段默认不为空(not null),默认值为当前时间(CURRENT_TIMESTAMP),如果不做特殊处理,并且update语句中没有指定该列的更新值,则默认更新为当前时间。
4.枚举和集合
字段的值只能在给定范围中选择,如单选框,多选框
enum枚举:规定一个范围:这个范围可以有多个,但是为该字段传值时,只能取规定范围内的其中一个
set集合:规定一个范围:这个范围可以有多个,但是为该字段传值时,可以取规定范围内的一个或多个
enum如果你不传值,默认是第一个值,或者为NUll
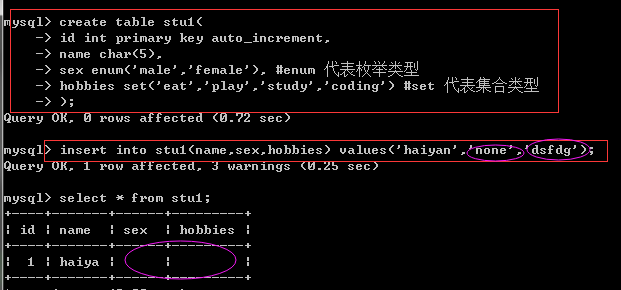
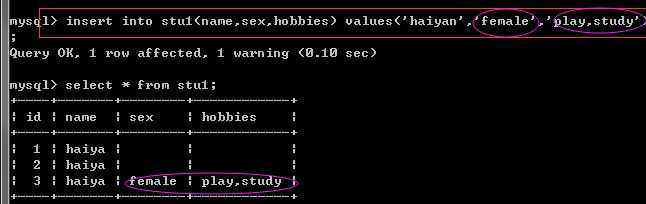
----------枚举和集合----------- create table stu1( id int primary key auto_increment, name char(5), sex enum('male','female'), #enum 代表枚举类型 hobbies set('eat','play','study','coding') #set 代表集合类型 ); insert into stu1(name,sex,hobbies) values('haiyan','none','dsfdg'); select * from stu1; #如果设置了sex是枚举类型,就的从设定的里面选其中的一个存 insert into stu1(name,sex,hobbies) values('haiyan','female','play,study'); select * from stu1; #如果设置了hobbies是集合类型,就得从设定的里面选其中一个或者多个值来存
没有按照枚举或集合规定的传值的结果
按照枚举或集合规定的传值结果
二.完整性约束
1.介绍
约束条件与数据类型的宽度一样,都是可选参数
作用:用于保证数据的完整性和一致性
主要分为:
PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录
FOREIGN KEY (FK) 标识该字段为该表的外键
NOT NULL 标识该字段不能为空
UNIQUE KEY (UK) 标识该字段的值是唯一的
AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键)
DEFAULT 为该字段设置默认值
UNSIGNED 无符号
ZEROFILL 使用0填充
说明:
1. 是否允许为空,默认NULL,可设置NOT NULL,字段不允许为空,必须赋值 2. 字段是否有默认值,缺省的默认值是NULL,如果插入记录时不给字段赋值,此字段使用默认值 sex enum('male','female') not null default 'male' age int unsigned NOT NULL default 20 必须为正值(无符号) 不允许为空 默认是20 3. 是否是key 主键 primary key 外键 foreign key 索引 (index,unique...)
2.not null 和default
是否可空,null表示空,非字符串
not null - 不可空
null - 可空
default默认值,创建列时可以指定默认值当插入数据时如果未主动设置,则自动添加默认值
create table t1(
id int not null defalut 2,
num int not null
)
3.unique约束(唯一性约束)
单列唯一
-----1.单列唯一--------- create table t2( id int not null unique, name char(10) ); insert into t2 values(1,'egon'); insert into t2 values(1,'alex'); #上面创建表的时候把id设置了唯一约束。那么在插入id=1,就会出错了
多列唯一
-----2.多列唯一--------- #255.255.255.255 create table server( id int primary key auto_increment, name char(10), host char(15), #主机ip port int, #端口 constraint host_port unique(host,port) #constraint host_port这个只是用来设置唯一约束的名字的,也可以不设置默认就有了 ); insert into server(name,host,port) values('ftp','192.168.20.11',8080); insert into server(name,host,port) values('https','192.168.20.11',8081); #ip和端口合起来唯一 select * from server;
4.primary key (主键约束)
primary key字段的值不为空,且唯一
一个表中可以:
单列做主键
多列做主键(复合主键)
但一个表内只能有一个主键primary key
============单列做主键=============== #方法一:not null+unique create table department1( id int not null unique, #主键 name varchar(20) not null unique, comment varchar(100) ); mysql> desc department1; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | NO | UNI | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.01 sec) #方法二:在某一个字段后用primary key create table department2( id int primary key, #主键 name varchar(20), comment varchar(100) ); mysql> desc department2; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.00 sec) #方法三:在所有字段后单独定义primary key create table department3( id int, name varchar(20), comment varchar(100), constraint pk_name primary key(id); #创建主键并为其命名pk_name mysql> desc department3; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.01 sec)
==================多列做主键================ create table service( ip varchar(15), port char(5), service_name varchar(10) not null, primary key(ip,port) ); mysql> desc service; +--------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------------+-------------+------+-----+---------+-------+ | ip | varchar(15) | NO | PRI | NULL | | | port | char(5) | NO | PRI | NULL | | | service_name | varchar(10) | NO | | NULL | | +--------------+-------------+------+-----+---------+-------+ rows in set (0.00 sec) mysql> insert into service values -> ('172.16.45.10','3306','mysqld'), -> ('172.16.45.11','3306','mariadb') -> ; Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> insert into service values ('172.16.45.10','3306','nginx'); ERROR 1062 (23000): Duplicate entry '172.16.45.10-3306' for key 'PRIMARY'
5.auto_increment(自增约束)
3.--------偏移量:auto_increment_offset--------- ==============没有设置偏移量的时候 create table dep( id int primary key auto_increment, name char(10) ); insert into dep(name) values('IT'),('HR'),('EFO'); select * from dep; ================设置自增的时候以10开头 create table dep1( id int primary key auto_increment, name char(10) )auto_increment = 10; insert into dep1(name) values('IT'),('HR'),('EFO'); select * from dep1; ===============auto_increment_increment:自增步长 create table dep3( id int primary key auto_increment, name char(10) ); 会话:通过客户端连到服务端(一次链接称为一次会话) set session auto_increment_increment = 2; #会话级,只对当前会话有效 set global auto_increment_increment=2; #全局,对所有的会话都有效 insert into dep3(name) values('IT'),('HR'),('SALE'),('Boss'); -----------查看变量---------- show variables like '%auto_in%';#查看变量。只要包含auto_in就都查出来了 =========auto_increment_offset:偏移量+auto_increment_increment:步长=========== 注意:如果auto_increment_offset的值大于auto_increment_increment的值, 则auto_increment_offset的值会被忽略 set session auto_increment_offset=2; set session auto_increment_increment=3; show variables like '%auto_in%'; create table dep4( id int primary key auto_increment, name char(10) ); insert into dep4(name) values('IT'),('HR'),('SALE'),('Boss');
6.foreign key (外键约束)
员工信息表有三个字段:工号 姓名 部门
公司有3个部门,但是有1个亿的员工,那意味着部门这个字段需要重复存储,部门名字越长,越浪费
解决方法:
我们完全可以定义一个部门表
然后让员工信息表关联该表,如何关联,即foreign key
如下图简单的表示了一下员工表与部门表的关系,即员工表的(dep_id)要关联部门表的id字段
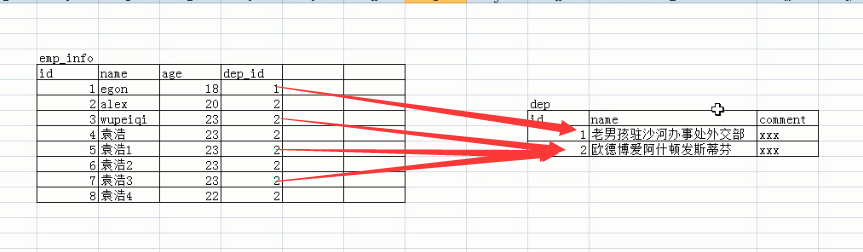
多对一(一个表多条记录的某一字段关联另一张表的唯一一个字段):员工有部门,部门又有好多信息,所以 分开建了一张部门表,部门表的id 和员工表里面 的dep_id相关联。(dep_id要关联部门表的id字段 (注意:1.先建被关联的表, 2.被关联的字段必须唯一 3.先给被关联的表插入记录 ) 先建张部门表(被关联表) create table dep( id int not null unique, #id int primary key auto_increment, name varchar(50), comment varchar(100) ); 再建张员工表(关联表) create table emp_info( id int primary key auto_increment, name varchar(20), dep_id int, constraint FK_depid_id foreign key(dep_id) references dep(id) #references :关联 on delete cascade #关联的表删了,被关联的表也删了 on update cascade #关联的表修改了,被关联的表也修改了 ); #先给被关联的表初始化记录 insert into dep values (1,'欧德博爱技术有限事业部','说的好...'), (2,'艾利克斯人力资源部','招不到人'), (3,'销售部','卖不出东西'); insert into emp_info values (1,'egon',1), (2,'alex1',2), (3,'alex2',2), (4,'alex3',2), (5,'李坦克',3), (6,'刘飞机',3), (7,'张火箭',3), (8,'林子弹',3), (9,'加特林',3); #修改 update dep set id =301 where id = 2; select * from dep; delect * from em_info; 如果部门解散了,员工也就走吧,就是部门表没了, 员工表也就没有了。
运行结果:
查看创建的表

修改id=301

查看被关联表和关联表


 浙公网安备 33010602011771号
浙公网安备 33010602011771号