MIT6.824 Lab1 实现记录
准备工作
在做该实验前需要先阅读下论文《MapReduce: Simplified Data Processing on Large Clusters》
Lab1 的实验任务是实现 Word Count,测试文件在 src/main 下,以 pg-*.txt 格式命名。
由于该系列课程是使用 Go 实现,入门 Go 可以看这个:Go 指南,我大概看了半小时就开始上手写了。
主要流程
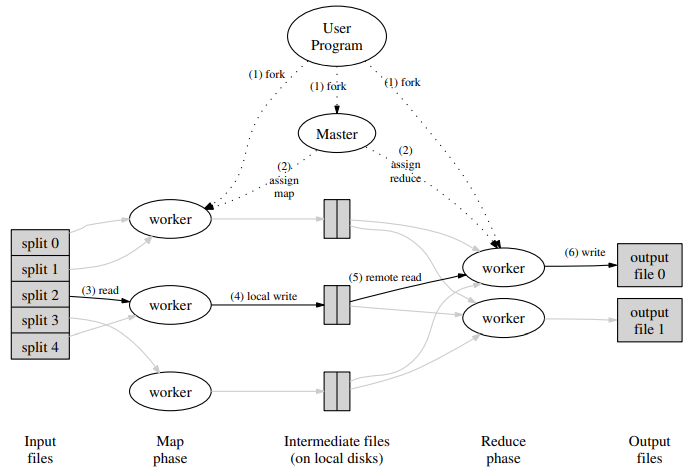
1. 在该实验中,map 和 reduce 函数已经实现,我们只需要实现 coordinator 和 worker 模块,完成完成单词计数功能。
2. coordinator 与 worker 之间通过 RPC 进行通信,首先 worker 通过 RPC 找 coordinator 索要任务,coordinator 先分配 map 任务,当 worker 将所有的 map 任务完成之后,coordinator 再分配 reduce 任务。
3. 在此期间 coordinator 需要记录每个任务的运行时间,若运行时间超过了10s,则 coordinator 需要将任务分配给其它 worker。
4. 当 worker 完成所有的 reduce 任务之后结束流程。
实验要求:
- nReduce对应的Reduce数及输出的文件数,也要作为MakeCoordinator()方法的参数;
- Reduce任务的输出文件的命名为mr-out-X,这个X就是来自nReduce;
- mr-out-X的输出有个格式要求,参照main/mrsequential.go,"%v %v" 格式;
- Map输出的中间值要放到当前目录的文件中,Reduce任务从这些文件来读取;
- 当Coordinator.go的Done()方法返回true,MapReduce的任务就完成了;
- 当一个任务完成,对应的worker就应该终止,这个终止的标志可以来自于call()方法,若它去给Master发送请求,得到终止的回应,那么对应的worker进程就可以结束了。
实验提示:
- 修改mr/worker.go的Worker(),发送RPC请求给coordinator要任务。然后修改Coordinator将还没有被Map执行的文件作为响应返回给worker。然后worker读取文件并执行Map方法函数,就如示例文件 mrsequential.go;
- Map和Reduce函数加载来自插件wc.go,如果改了这些东西需要使用命令重新编译生成新的.so文件,尽量不要动这些东西;
- 中间文件的命名方式推荐为mr-X-Y,X对应Map任务Id,Y对应的Reduce任务Id;
- 为顺利存储中间数据,采用json,以便读取;
- worker 的 map 部分可以使用ihash(key)函数(在worker.go 中)为给定的键选择 reduce 任务;
- Coordinator作为一个 RPC 服务器,将是并发的;不要忘记锁定共享数据;
- 在所有Map任务完成后,Reduce任务才会开始,所以对应的worker可能会需要等待,那么可以使用time.sleep()或其他方法;
- worker可能挂掉或其他原因崩了,Coordinator在这个实验中等待10s,超过时间将会分配给其他的worker;
- 您可以使用 ioutil.TempFile 创建一个临时文件,并使用 os.Rename 对其进行原子重命名;
- test-mr.sh 运行子目录 mr-tmp 中的所有进程,因此如果出现问题并且您想查看中间文件或输出文件,请查看那里。您可以修改 test-mr.sh 以在测试失败后退出,这样脚本就不会继续测试(并覆盖输出文件)。
Task 结构体
首先需要构造任务的结构体,由于我们需要读取文件,所以 Task 必须包含文件名;在实验提示中提到中间文件的命名方式推荐为 mr-X-Y,所以 Task 需要 Id 信息;每个 Task 还需要计时,所以 Task 需要运行时间或时间戳信息。
此外,在 MapReduce 中分为 map 和 reduce 两个任务,事实上这两个任务应该由不同的 worker 来执行,但在该实验中,一个 worker 既可以处理 map 任务,也可以处理 reduce 任务,所以 Task 必须指出它是 map 任务还是 reduce 任务。
1 2 3 4 5 6 7 8 | type Task struct { FileName string // 文件名 TaskType int TaskId int NMap int NReduce int TimeStamp int64} |
Coordinator
coordinator 的作用是给 worker 分配任务,如果当前还有 map 任务未完成,那么就将 map 任务分配给 worker;否则分配 reduce 任务。所以在 Coordinator 中需要存储当前还未完成的任务,当然任务也可能在执行过程中,这部分也需要记录,我在这里使用 map 记录未完成和正在执行中的 Task,只要 MapTasksReady 和 MapTasksInProgress 为空则说明当前 map 任务已处理完。
1 2 3 4 5 6 7 8 9 10 11 | type Coordinator struct { // Your definitions here. Mu sync.Mutex MapTasksReady map[int]Task ReduceTasksReady map[int]Task MapTasksInProgress map[int]Task ReduceTasksInProgress map[int]Task ReduceReady bool NReduce int NMap int} |
我们在 func MakeCoordinator(files []string, nReduce int) *Coordinator中生成 coordinator。files 是输入的文件,nReduce 是 reduce 任务的个数。我们需要为每个输入文件生成一个 map 任务,将任务保存在 MapTasksReady 中,表示待分配给 worker 执行。
1 2 3 4 5 6 7 8 9 10 | for i, file := range files { c.MapTasksReady[i] = Task{ FileName: file, TaskType: Map, TaskId: i, NMap: numFile, NReduce: nReduce, TimeStamp: time.Now().Unix(), }} |
Worker
worker 的工作很简单,就是在func Worker(mapf func(string, string) []KeyValue, reducef func(string, []string) string) 函数中不停的向 coordinator 索要 Task 并执行,所以在这里需要分别实现对 map 任务的处理和 reduce 任务的处理。根据返回值中的 TaskType 来执行相应的代码。
每个 map 任务都需要将处理的中间结果保存到不同的文件中,从而 reduce 可以读取相应的文件。在实验中采用的命名方式是 mr-X-Y,其中 X 是 map 的任务 Id,Y 是 reduce 的任务 Id。
对于 map 任务的处理,实验中提供了相应的 ihash 函数,计算某个 key 应该输出到哪个 reduce 任务。所以最后会输出多个 mr-X-Y 的文件;对于 reduce 任务来说,我们根据其 TaskId 则可以读取对应的 *.Y 文件,对其中的单词进行统计并最终输出 mr-out- 文件即可。
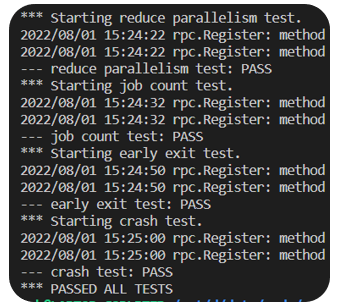
实验结果
参考:
- MIT 6.824 分布式系统 | Lab 1:MapReduce
- 6.824 Lab 1: MapReduce
- mit6.824分布式lab1-MapReduce(1)
- MIT6.824Lab1代码与思路
- 《Distributed Systems》(6.824)LAB1(mapreduce)
- 【分布式】MIT 6.824 Lab1-MapReduce
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架