torch.nn.Embedding使用
在RNN模型的训练过程中,需要用到词嵌入,而torch.nn.Embedding就提供了这样的功能。我们只需要初始化torch.nn.Embedding(n,m),n是单词数,m就是词向量的维度。
一开始embedding是随机的,在训练的时候会自动更新。
举个简单的例子:
word1和word2是两个长度为3的句子,保存的是单词所对应的词向量的索引号。
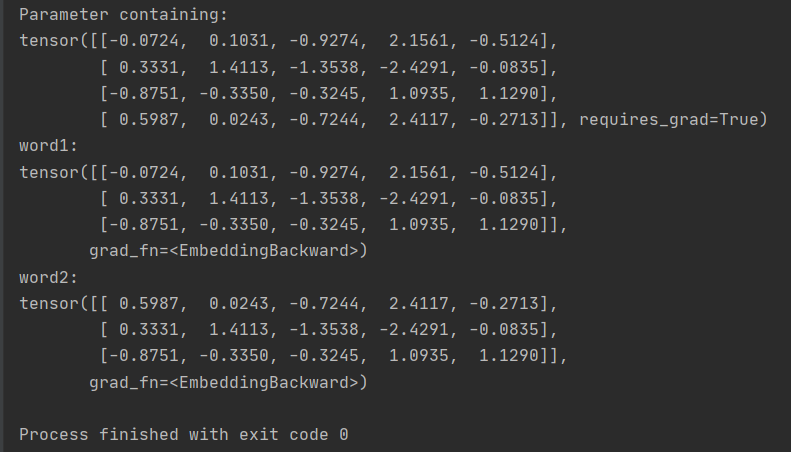
随机生成(4,5)维度大小的embedding,可以通过embedding.weight查看embedding的内容。
输入word1时,embedding会输出第0、1、2行词向量的内容,word2同理。
1 2 3 4 5 6 7 8 9 10 11 | import torchword1 = torch.LongTensor([0, 1, 2])word2 = torch.LongTensor([3, 1, 2])embedding = torch.nn.Embedding(4, 5)print(embedding.weight)print('word1:')print(embedding(word1))print('word2:')print(embedding(word2)) |
除此之外,我们也可以导入已经训练好的词向量,但是需要设置训练过程中不更新。
如下所示,emb是已经训练得到的词向量,先初始化等同大小的embedding,然后将emb的数据复制过来,最后一定要设置weight.requires_grad为False。
1 2 3 4 5 | self.embedding = torch.nn.Embedding(emb.size(0), emb.size(1))self.embedding.weight = torch.nn.Parameter(emb)# 固定embeddingself.embedding.weight.requires_grad = False |
如果您觉得阅读本文对您有帮助,请点一下“推荐”按钮,您的“推荐”将是我最大的写作动力!欢迎各位转载,但是未经作者本人同意,转载文章之后必须在文章页面明显位置给出作者和原文连接,否则保留追究法律责任的权利。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架
2017-10-09 SPOJ 839 Optimal Marks(最小割的应用)