MapReduce实现PageRank算法(稀疏图法)
前言
本文用Python编写代码,并通过hadoop streaming框架运行。
算法思想
下图是一个网络:

考虑转移矩阵是一个很多的稀疏矩阵,我们可以用稀疏矩阵的形式表示,我们把web图中的每一个网页及其链出的网页作为一行,即用如下方式表示:
1 A B C D 2 B A D 3 C C 4 D B C
Map阶段
在Map阶段,Map操作的每一行,对所有出链发射当前网页概率值的1/k,k是当前网页的出链数,比如对第一行输出<B,1/3*1/4>,<C,1/3*1/4>,<D,1/3*1/4>。
Reduce阶段
Reduce操作收集同一网页的值,累加并按权重计算,即$P_{i} = \alpha \cdot (b_{1}+b_{2}+\cdots +b_{m})+\frac{(1-\alpha )}{N}$,其中$m$是指向网页$j$的网页数,$N$为所有网页数。
实践的时候,怎样在Map阶段知道当前行网页的概率值,需要一个单独的文件专门保存上一轮的概率分布值,先进行一次排序,让出链行与概率值按网页id出现在同一Mapper里面,整个流程如下:
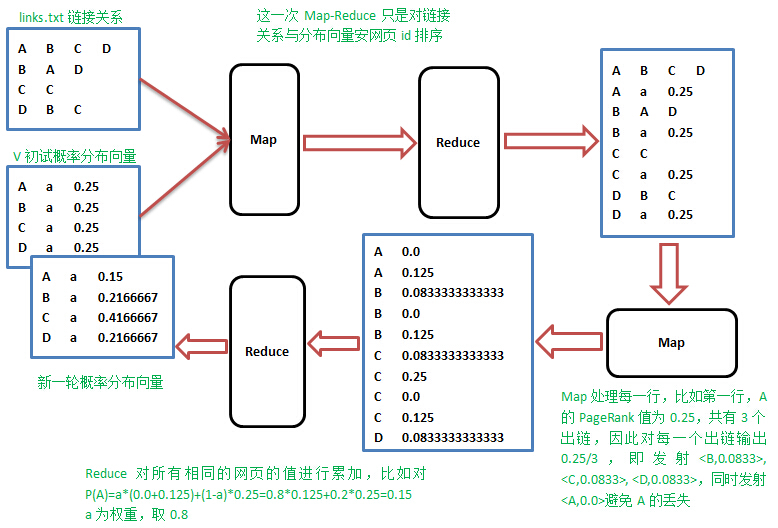
算法实现
sortMapper.py 和 sortReducer.py的功能就是将图和概率矩阵读入并进行排序。
sortMapper.py
#!/usr/bin/env python3
import sys
for line in sys.stdin:
print(line.strip())
sortReducer.py
#!/usr/bin/env python3
import sys
for line in sys.stdin:
print(line.strip())
pageRankMapper.py
#!/usr/bin/env python3
import sys
node1 = node2 = None
count1 = count2 = 0
page_rank = 0.0
for line in sys.stdin:
if line.count('\n') == len(line):
continue # 除去空行
data = line.strip().split('\t')
if data[1] == 'a': # 该行数据是PageRank
count1 += 1
if count1 > 1: # 避免某个结点的PageRank丢失,因为有可能连着两行数据是PageRank
print('%s\t%s' % (node1, 0.0))
node1 = data[0] # 记录出发结点
page_rank = float(data[2]) # 记录出发结点的PageRank
else: # 该行是链
node2 = data[0]
reach_node_list = data[1:]
if node1 == node2 and node1: # 注意除去None的情况
node_number = len(reach_node_list) # 出链数
for reach_node in reach_node_list:
print('%s\t%s' % (reach_node, page_rank*1.0/node_number))
print('%s\t%s' % (node1, 0.0))
node1 = node2 = None
count1 = 0
pageRankReducer.py
#!/usr/bin/env python3
import sys
alpha = 0.8
node = None # 记录当前结点
page_rank_sum = 0.0 # 记录当前结点的PageRank总和
N = 4
for line in sys.stdin:
if line.count('\n') == len(line): continue
data = line.strip().split('\t')
if node is None or node != data[0]:
if(node): print('%s\ta\t%s' % (node, alpha*page_rank_sum + (1.0-alpha)/N))
node = data[0]
page_rank_sum = 0.0
page_rank_sum += float(data[1])
print('%s\ta\t%s' % (node, alpha*page_rank_sum + (1.0-alpha)/N))
算法运行
由于该算法需要迭代运行,所以编写shell脚本来运行。
我也不是很会写shell脚本,所以写了一个感觉比较傻的。
run.sh
#!/bin/bash
max=50
for i in `seq 1 $max`
do
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-streaming-2.9.2.jar \
-mapper /usr/local/hadoop/sortMapper.py \
-file /usr/local/hadoop/sortMapper.py \
-reducer /usr/local/hadoop/sortReducer.py \
-file /usr/local/hadoop/sortReducer.py \
-input links.txt pageRank.txt \
-output out1
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/hadoop-streaming-2.9.2.jar \
-mapper /usr/local/hadoop/pageRankMapper.py \
-file /usr/local/hadoop/pageRankMapper.py \
-reducer /usr/local/hadoop/pageRankReducer.py \
-file /usr/local/hadoop/pageRankReducer.py \
-input out1/part-00000 \
-output out2
/usr/local/hadoop/bin/hadoop fs -rm pageRank.txt
/usr/local/hadoop/bin/hadoop fs -cp out2/part-00000 pageRank.txt
/usr/local/hadoop/bin/hadoop fs -rm -r -f out1
/usr/local/hadoop/bin/hadoop fs -rm -r -f out2
rm -r ~/Desktop/tmp.txt
/usr/local/hadoop/bin/hadoop fs -get pageRank.txt ~/Desktop/tmp.txt
echo $i | ~/Desktop/slove.py
done
解释一下该脚本,首先每次需要执行sortMapper.py,sortReducer.py,pageRankMapper.py,pageRankReducer.py四段代码,执行完之后会产生新的结点pageRank值,即保存在part-00000中。因为下一次运行需要用到这新的数据,所以此时把旧的pageRank.txt文件删除,再把新产生的数据复制过去。
为了记录每次迭代的结果,我还额外编写了一段代码来将记录每次结果。代码如下:
slove.py
#!/usr/bin/env python3
import sys
number = sys.stdin.readline().strip()
f_src = open("tmp.txt","r")
f_dst = open("result.txt", "a")
mat = "{:^30}\t"
f_dst.write('\n' + number)
lines = f_src.readlines()
for line in lines:
if line.count('\n') == len(line):
continue
data = line.strip().split('\t')
f_dst.write(mat.format(data[2]))
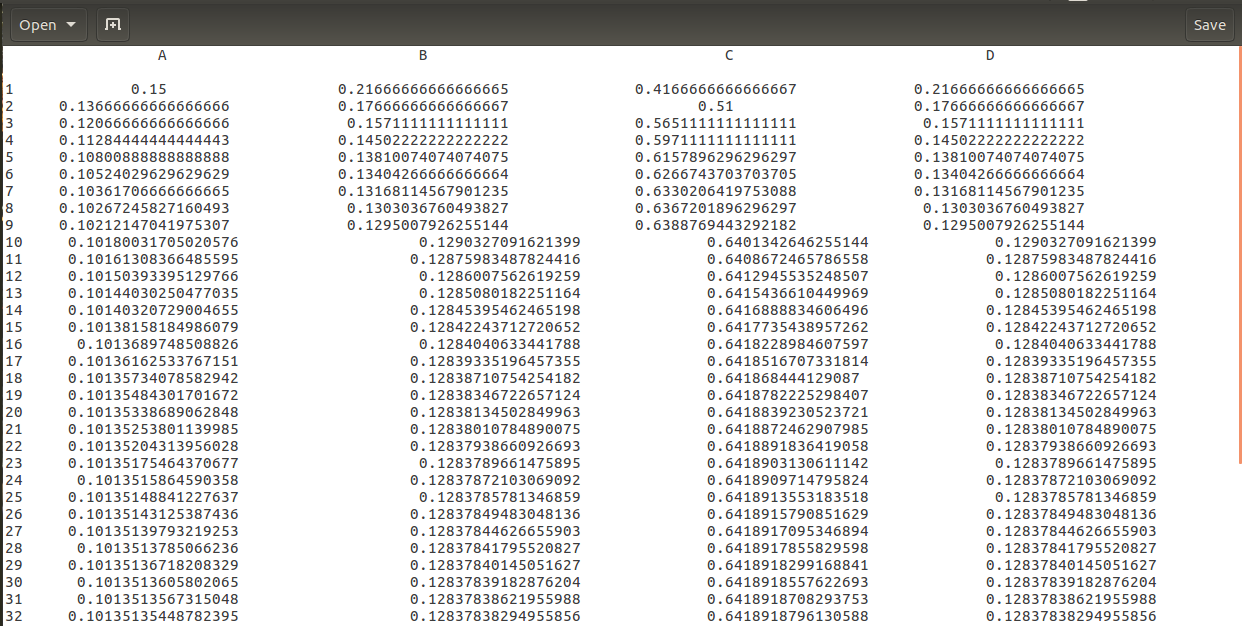
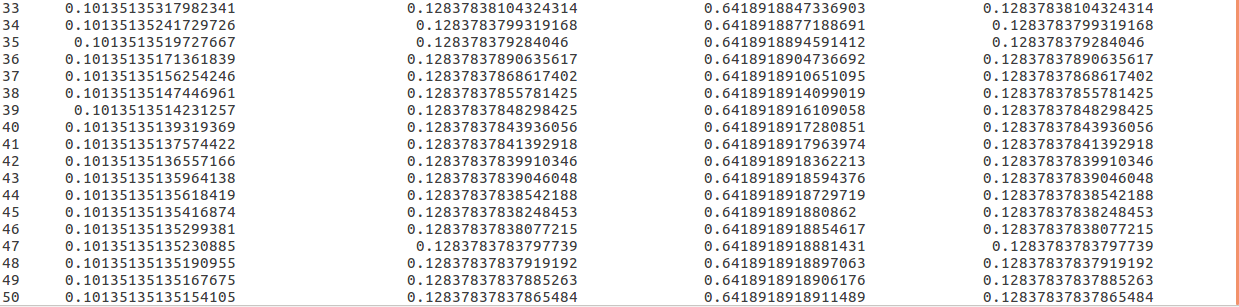
最后的运行结果为:
后记
上面实现的稀疏图的算法,后来我又实现了矩阵的算法。有兴趣的可以转至:传送门
参考:

