

Python接口自动化测试工具(Pytest+Allure+jsonpath+xlrd+excel、支持Restful接口规范)
废话
和几个朋友聊天然后出来的产物希望能帮到大家学习接口自动化测试,欢迎大家交流指出不合适的地方,源码在文末
功能
- 实现:get/post请求(上传文件)::理论上其他delete/put等请求也实现了,支持restful接口规范
- 发送邮件
- 生成allure测试报告
- 压缩测试报告文件
- 数据依赖
运行机制
- 通过读取配置文件,获取到host地址、提取token的jsonpath表达式,提取实际响应结果用来与预期结果比对的jsonpath表达式。
- 读取excel用例文件数据,组成一个符合pytest参数化的用例数据,根据每列进行数据处理(token操作、数据依赖)
- token,写,需要使用一个正常登录的接口,并且接口中要返回token数据,才可以提取,token,读为该请求将携带有token的header,token 无数据的将不携带token
- 数据依赖处理,从excel中读取出来的格式{"用例编号":["jsonpath表达式1", "jsonpath表达式2"]},通过用例编号来获取对应case的实际响应结果(实际响应结果在发送请求后,回写到excel中),通过jsonpath表达式提取对应的依赖参数字段,以及对应的值,最终会返回一个存储该接口需要依赖数据的字典如{"userid":500, "username": "zy7y"},在发送请求时与请求数据进行合并,组成一个新的data放到请求中
- 每次请求完成之后将回写实际的响应结果到excel中
- 根据配置文件中配置的jsonpath表达式提取实际响应内容与excel中预期结果的数据对比
- 生成测试报告
- 压缩测试报告文件夹
- 发送邮件
已知问题
执行接口消耗时间变长,代码乱(语言学的不扎实),频繁读写excel(可考虑用字典存每个接口的实际响应,取值直接从响应字典中取出)
整体代码结构优化未实现,导致最终测试时间变长,其他工具单接口测试只需要39ms,该框架中使用了101ms,考虑和频繁读写用例数据导致
环境与依赖
| 名称 | 版本 | 作用 |
|---|---|---|
| python | 3.7.8 | |
| pytest | 6.0.1 | 底层单元测试框架,用来实现参数化,自动执行用例 |
| allure-pytest | 2.8.17 | allure与pytest的插件可以生成allure的测试报告 |
| jsonpath | 0.82 | 用来进行响应断言操作 |
| loguru | 0.54 | 记录日志 |
| PyYAML | 5.3.1 | 读取yml/yaml格式的配置文件 |
| Allure | 2.13.5 | 要生成allure测试报告必须要在本机安装allure并配置环境变量 |
| xlrd | 1.2.0 | 用来读取excel中用例数据 |
| yagmail | 0.11.224 | 测试完成后发送邮件 |
| requests | 2.24.0 | 发送请求 |
目录结构

执行顺序
运行test_api.py -> 读取config.yaml(tools.read_config.py) -> 读取excel用例文件(tools.read_data.py) -> test_api.py实现参数化 -> 处理是否依赖数据 ->base_requests.py发送请求 -> test_api.py断言 -> read_data.py回写实际响应到用例文件中(方便根据依赖提取对应的数据)
config.ymal展示
server: test: http://127.0.0.1:8888/api/private/v1/ # 实例代码使用的接口服务,已改为作者是自己的云服务器部署。(后端源码来自b站:https://www.bilibili.com/video/BV1EE411B7SU?p=10) dev: http://49.232.203.244:8888/api/private/v1/ # 实际响应jsonpath提取规则设置 response_reg: # 提取token的jsonpath表达式 token: $.data.token # 提取实际响应的断言数据jsonpath表达式,与excel中预期结果的数据进行比对用 response: $.meta file_path: case_data: ../data/case_data.xlsx report_data: ../report/data/ report_generate: ../report/html/ report_zip: ../report/html/apiAutoTestReport.zip log_path: ../log/运行日志{time}.log email: # 发件人邮箱 user: 123456.com # 发件人邮箱授权码 password: ASGCSFSGS # 邮箱host host: smtp.163.com contents: 解压apiAutoReport.zip(接口测试报告)后,请使用已安装Live Server 插件的VsCode,打开解压目录下的index.html查看报告 # 收件人邮箱 addressees: ["收件人邮箱1","收件人邮箱2","收件人邮箱3"] title: 接口自动化测试报告(见附件) # 附件地址 enclosures: ["../report/html/apiAutoTestReport.zip",]
EXcel用例展示


脚本一览
请求方法封装
#!/usr/bin/env/python3 # -*- coding:utf-8 -*- """ @project: apiAutoTest @author: zy7y @file: base_requests.py @ide: PyCharm @time: 2020/7/31 """ from test import logger import requests class BaseRequest(object): def __init__(self): pass # 请求 def base_requests(self, method, url, parametric_key=None, data=None, file_var=None, file_path=None, header=None): """ :param method: 请求方法 :param url: 请求url :param parametric_key: 入参关键字, get/delete/head/options/请求使用params, post/put/patch请求可使用json(application/json)/data :param data: 参数数据,默认等于None :param file_var: 接口中接受文件的参数关键字 :param file_path: 文件对象的地址, 单个文件直接放地址:/Users/zy7y/Desktop/vue.js 多个文件格式:["/Users/zy7y/Desktop/vue.js","/Users/zy7y/Desktop/jenkins.war"] :param header: 请求头 :return: 返回json格式的响应 """ session = requests.Session() if (file_var in [None, '']) and (file_path in [None, '']): files = None else: # 文件不为空的操作 if file_path.startswith('[') and file_path.endswith(']'): file_path_list = eval(file_path) files = [] # 多文件上传 for file_path in file_path_list: files.append((file_var, (open(file_path, 'rb')))) else: # 单文件上传 files = {file_var: open(file_path, 'rb')} if parametric_key == 'params': res = session.request(method=method, url=url, params=data, headers=header) elif parametric_key == 'data': res = session.request(method=method, url=url, data=data, files=files, headers=header) elif parametric_key == 'json': res = session.request(method=method, url=url, json=data, files=files, headers=header) else: raise ValueError('可选关键字为:get/delete/head/options/请求使用params, post/put/patch请求可使用json(application/json)/data') logger.info(f'请求方法:{method},请求路径:{url}, 请求参数:{data}, 请求文件:{files}, 请求头:{header})') return res.json()
读取excel用例数据
#!/usr/bin/env/python3 # -*- coding:utf-8 -*- """ @project: apiAutoTest @author: zy7y @file: read_data.py @ide: PyCharm @time: 2020/7/31 """ import xlrd from test import logger class ReadData(object): def __init__(self, excel_path): self.excel_file = excel_path self.book = xlrd.open_workbook(self.excel_file) def get_data(self): """ :return: data_list - pytest参数化可用的数据 """ data_list = [] table = self.book.sheet_by_index(0) for norw in range(1, table.nrows): # 每行第4列 是否运行 if table.cell_value(norw, 3) == '否': continue value = table.row_values(norw) value.pop(3) # 配合将每一行转换成元组存储,迎合 pytest的参数化操作,如不需要可以注释掉 value = tuple(value) value = tuple(value) logger.info(f'{value}') data_list.append(value) return data_list
存储接口实际结果响应
#!/usr/bin/env/python3 # -*- coding:utf-8 -*- """ @project: apiAutoTest的副本 @author: zy7y @file: save_response.py @ide: PyCharm @time: 2020/8/8 """ import json import jsonpath from test import logger class SaveResponse(object): def __init__(self): self.actual_response = {} # 保存实际响应 def save_actual_response(self, case_key, case_response): """ :param case_key:用例编号 :param case_response:对应用例编号的实际响应 :return: """ self.actual_response[case_key] = case_response logger.info(f'当前字典数据{self.actual_response}') # 读取依赖数据 def read_depend_data(self, depend): """ :param depend: 需要依赖数据字典{"case_001":"['jsonpaht表达式1', 'jsonpaht表达式2']"} :return: """ depend_dict = {} depend = json.loads(depend) for k, v in depend.items(): # 取得依赖中对应case编号的值提取表达式 try: for value in v: # value : '$.data.id' # 取得对应用例编号的实际响应结果 actual = self.actual_response[k] # 返回依赖数据的key d_k = value.split('.')[-1] # 添加到依赖数据字典并返回 depend_dict[d_k] = jsonpath.jsonpath(actual, value)[0] except TypeError as e: logger.error(f'实际响应结果中无法正常使用该表达式提取到任何内容,发现异常{e}') return depend_dict
处理依赖数据逻辑
#!/usr/bin/env/python3 # -*- coding:utf-8 -*- """ @project: apiAutoTest @author: zy7y @file: data_tearing.py @ide: PyCharm @time: 2020/8/10 """ import json from json import JSONDecodeError import jsonpath from test import logger class TreatingData(object): """ 处理hader/path路径参数/请求data依赖数据代码 """ def __init__(self): self.no_token_header = {} self.token_header = {} def treating_data(self, is_token, parameters, dependent, data, save_response_dict): # 使用那个header if is_token == '': header = self.no_token_header else: header = self.token_header logger.info(f'处理依赖前data的数据:{data}') # 处理依赖数据data if dependent != '': dependent_data = save_response_dict.read_depend_data(dependent) logger.debug(f'依赖数据解析获得的字典{dependent_data}') if data != '': # 合并组成一个新的data dependent_data.update(json.loads(data)) data = dependent_data logger.info(f'data有数据,依赖有数据时 {data}') else: # 赋值给data data = dependent_data logger.info(f'data无数据,依赖有数据时 {data}') else: if data == '': data = None logger.info(f'data无数据,依赖无数据时 {data}') else: data = json.loads(data) logger.info(f'data有数据,依赖无数据 {data}') # 处理路径参数Path的依赖 # 传进来的参数类似 {"case_002":"$.data.id"}/item/{"case_002":"$.meta.status"},进行列表拆分 path_list = parameters.split('/') # 获取列表长度迭代 for i in range(len(path_list)): # 按着 try: # 尝试序列化成dict: json.loads('2') 可以转换成2 path_dict = json.loads(path_list[i]) except JSONDecodeError as e: # 序列化失败此path_list[i]的值不变化 logger.error(f'无法转换字典,进入下一个检查,本轮值不发生变化:{path_list[i]},{e}') # 跳过进入下次循环 continue else: # 解析该字典,获得用例编号,表达式 logger.info(f'{path_dict}') # 处理json.loads('数字')正常序列化导致的AttributeError try: for k, v in path_dict.items(): try: # 尝试从对应的case实际响应提取某个字段内容 path_list[i] = jsonpath.jsonpath(save_response_dict.actual_response[k], v)[0] except TypeError as e: logger.error(f'无法提取,请检查响应字典中是否支持该表达式,{e}') except AttributeError as e: logger.error(f'类型错误:{type(path_list[i])},本此将不转换值 {path_list[i]},{e}') # 字典中存在有不是str的元素:使用map 转换成全字符串的列表 path_list = map(str, path_list) # 将字符串列表转换成字符:500/item/200 parameters_path_url = "/".join(path_list) logger.info(f'path路径参数解析依赖后的路径为{parameters_path_url}') return data, header, parameters_path_url
启动文件
#!/usr/bin/env/python3 # -*- coding:utf-8 -*- """ @project: apiAutoTest @author: zy7y @file: test_api.py @ide: PyCharm @time: 2020/7/31 """ import json import jsonpath from test import logger import pytest import allure from api.base_requests import BaseRequest from tools.data_tearing import TreatingData from tools.read_config import ReadConfig from tools.read_data import ReadData from tools.save_response import SaveResponse # 读取配置文件 对象 rc = ReadConfig() base_url = rc.read_serve_config('dev') token_reg, res_reg = rc.read_response_reg() case_data_path = rc.read_file_path('case_data') report_data = rc.read_file_path('report_data') report_generate = rc.read_file_path('report_generate') log_path = rc.read_file_path('log_path') report_zip = rc.read_file_path('report_zip') email_setting = rc.read_email_setting() # 实例化存响应的对象 save_response_dict = SaveResponse() # 读取excel数据对象 data_list = ReadData(case_data_path).get_data() # 数据处理对象 treat_data = TreatingData() # 请求对象 br = BaseRequest() logger.info(f'配置文件/excel数据/对象实例化,等前置条件处理完毕\n\n') class TestApiAuto(object): # 启动方法 def run_test(self): import os, shutil if os.path.exists('../report') and os.path.exists('../log'): shutil.rmtree(path='../report') shutil.rmtree(path='../log') # 日志存取路径 logger.add(log_path, encoding='utf-8') pytest.main(args=[f'--alluredir={report_data}']) os.system(f'allure generate {report_data} -o {report_generate} --clean') logger.warning('报告已生成') @pytest.mark.parametrize('case_number,case_title,path,is_token,method,parametric_key,file_var,' 'file_path, parameters, dependent,data,expect', data_list) def test_main(self, case_number, case_title, path, is_token, method, parametric_key, file_var, file_path, parameters, dependent, data, expect): """ :param case_number: 用例编号 :param case_title: 用例标题 :param path: 接口路径 :param is_token: token操作:写入token/读取token/不携带token :param method: 请求方式:get/post/put/delete.... :param parametric_key: 入参关键字:params/data/json :param file_var: 接口中接受文件对象的参数名称 :param file_path: 文件路径,单文件实例:/Users/zy7y/PycharmProjects/apiAutoTest/test/__init__.py 多文件实例['/Users/zy7y/PycharmProjects/apiAutoTest/test/__init__.py','/Users/zy7y/PycharmProjects/apiAutoTest/test/test_api.py'] :param parameters: path参数(携带在url中的参数)依赖处理 users/:id(id携带在url中) 实例:{"case_001": '$.data.id'},解析 从用例编号为case_001的实际结果响应中提取data字典里面的id的内容(假设提取出来是500), 最后请求的路径将是host + users/500 :param dependent: data数据依赖,该接口需要上一个接口返回的响应中的某个字段及内容:实例{"case_001",["$.data.id","$.data.username"]} 解析: 从用例case_001的实际响应结果中提取到data下面的id,与username的值(假设id值为500,username为admin),那么提取的数据依赖内容将是{"id":500, "username":"admin"} 纳闷最终请求的data 将是 {"id":500, "username":"admin"} 与本身的data合并后的内容 :param data: 请求数据 :param expect:预期结果,最后与config/config.yaml下的response_reg->response提取出来的实际响应内容做对比,实现断言 :return: """ # 感谢:https://www.cnblogs.com/yoyoketang/p/13386145.html,提供动态添加标题的实例代码 # 动态添加标题 allure.dynamic.title(case_title) logger.debug(f'⬇️⬇️⬇️...执行用例编号:{case_number}...⬇️⬇️⬇️️') with allure.step("处理相关数据依赖,header"): data, header, parameters_path_url = treat_data.treating_data(is_token, parameters, dependent, data, save_response_dict) with allure.step("发送请求,取得响应结果的json串"): res = br.base_requests(method=method, url=base_url + path + parameters_path_url, parametric_key=parametric_key, file_var=file_var, file_path=file_path, data=data, header=header) with allure.step("将响应结果的内容写入实际响应字典中"): save_response_dict.save_actual_response(case_key=case_number, case_response=res) # 写token的接口必须是要正确无误能返回token的 if is_token == '写': with allure.step("从登录后的响应中提取token到header中"): treat_data.token_header['Authorization'] = jsonpath.jsonpath(res, token_reg)[0] with allure.step("根据配置文件的提取响应规则提取实际数据"): really = jsonpath.jsonpath(res, res_reg)[0] with allure.step("处理读取出来的预期结果响应"): expect = json.loads(expect) with allure.step("预期结果与实际响应进行断言操作"): assert really == expect logger.info(f'完整的json响应: {res}\n需要校验的数据字典: {really} 预期校验的数据字典: {expect} \n测试结果: {really == expect}') logger.debug(f'⬆⬆⬆...用例编号:{case_number},执行完毕,日志查看...⬆⬆⬆\n\n️') if __name__ == '__main__': TestApiAuto().run_test() # 使用jenkins集成将不会使用到这两个方法(邮件发送/报告压缩zip) # from tools.zip_file import zipDir # from tools.send_email import send_email # zipDir(report_generate, report_zip) # send_email(email_setting)
运行测试
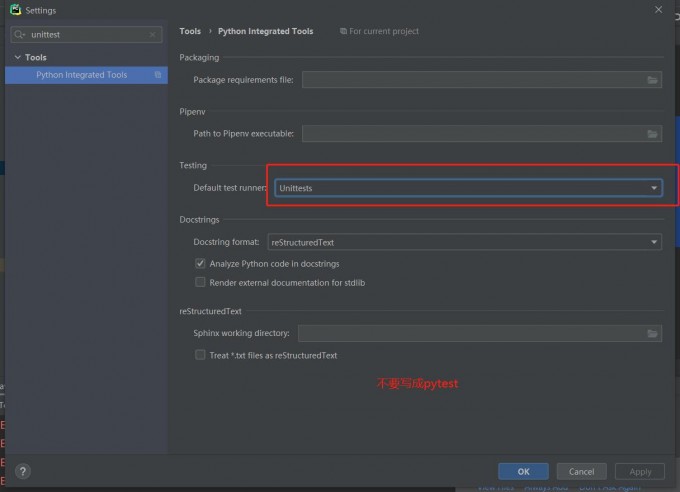
首先确保需要的环境与依赖包无问题之后,使用Pycharm打开项目,找到settings修改为unitest或者其他非pytest,具体操作如下
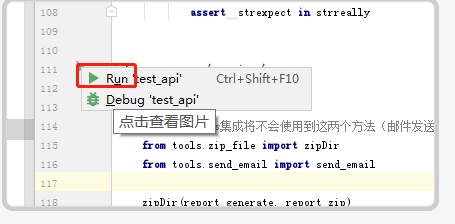
运行结果

致谢
jsonpath语法学习:https://blog.csdn.net/liuchunming033/article/details/106272542
zip文件压缩:https://www.cnblogs.com/yhleng/p/9407946.html
欢迎交流。
源码地址
源码地址Gitee - version1.0分支: https://gitee.com/zy7y/apiAutoTest/tree/version1.0/
源码地址GitHub- version1.0 分支:https://github.com/zy7y/apiAutoTest/tree/version1.0/
更新
2020/11/23 - 优化数据参数、路径参数依赖处理方式,现版本与之前同等环境下,测试时间提升2S
介绍:https://www.cnblogs.com/zy7y/p/14022398.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)