[编译原理读书笔记][第2章 一个简单的语法制导程序
[编译原理读书笔记][第2章 一个简单的语法制导程序]
标签(空格分隔): 未分类
本章内容是对本书第3章至第六章中介绍的编译技术的综合介绍.
- 通过将一个语句转换为三地址代码的过程来讲解
- 重点是:词法分析,语法分析和中间代码生成.
- 第7章,第8章将讲述如何将三地址代码转换为机器指令
2.1 引言
-
2.2:给出一个广泛使用的表示方法来描述语法,叫做
上下文无关法或者BNF(Backus-Naur范式). -
2.3:面向文法的编译技术:
语法指导翻译 -
2.4:语法分析
-
2.5:一个中缀转后缀的过程
-
2.6:词法分析
-
2.8:构造语法树
2.2 语法定义
介绍一种用于描述程序设计语言语法的表示方法---"上下文无关法"或简称文法.被用于组织编译器前端.
-
何为上下文无关文法?
- V 总可以被字符w 自由替换,而无需考虑字符V出现的上下文
-
Java的
if-else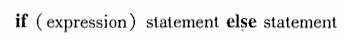
-
文法

2.2.1 文法定义
一个上下文无关法(context-free grammar)由4个元素组成:
- 一个终结符号集合,有时也称做"词法单元".
- 一个非终结符号集合,有时也称做"语法变量"
- 每个
非终结符号表示一个终结符号串的结合.(后面介绍)
- 每个
- 一个产生式集合:表示某个构造的某种书写形式.
- 产生式头或左部:
非终结符号. - 一个箭头
- 产生式体或右部: 终结符号与非终结符号组成的序列
- 如果产生式头代表一个构造,那么产生式体代表该构造的一种书写形式.
- 产生式头或左部:
- 指定一个非终结符号为开始符号
2.2.2 推导
根据文法推倒符号串时.首先从开始符号出发,不断地将某个非终结符号替换为该非终结符号的某个产生式的体.直到全部为终结符号.
- 可以从开始符号推倒得到的所有终结符号串的集合称为该文法定义的语言.
语法分析的任务
-
parsing的任务是: 接受一个终结符号串作为输入,找出从文法的开始符号推倒出该串的方法. -
如果不能推倒出,则报告语法错误.
-
主要语法分析方法,在第四章中介绍
2.2.3 语法分析树
语法分析树用图形方法展现了从文法的开始符号推倒出对应语言中的符号串的过程.

parse tree有以下性质
- 根节点的标号为文法的开始字符.
- 叶子节点为一个终结符号或
e - 内部节点为一个非终结符号
- 如果
非终结符号A它的子节点从左至右有X1,X2..XN,那么必然有产生式A->X1X2X3..XN.
例子
文法:
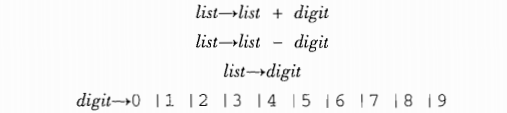
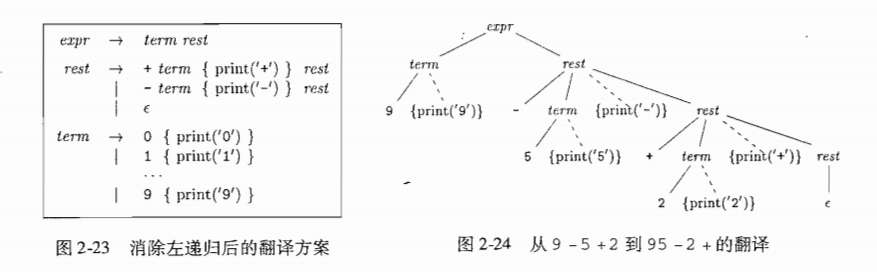
需要推倒的语句: 9 - 5 + 2
语法树:
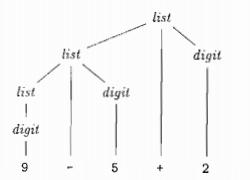
一个文法的语言的另一个定义是任何能够由某颗语法分析树生成的符号串的集合.
为一个给点的终结符号串构建一颗语法分析树的过程称为对该符号穿进行语法分析
2.2.4 二义性
某些语法如果不严谨会产生二义性.比如将上述例子的语法改成
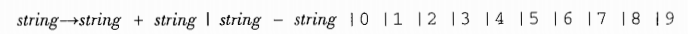
那么对之前的终结符号串的解释可以用两种语法树
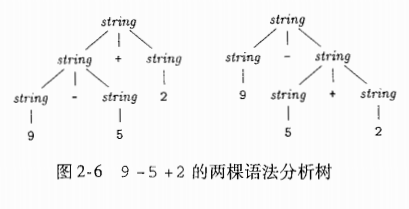
前者的结果是6, 后者是2
显然有问题.所以一个好的文法不应该有二义性.
2.2.5 运算符结合性
- 左结合运算向左下端延伸
- 右结合运算向右下端延伸
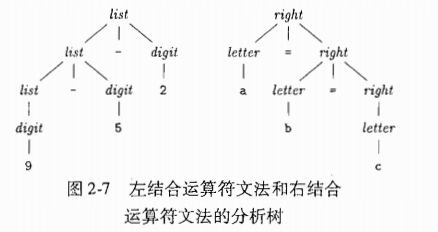
等号的文法:
2.2.6 运算符的优先级
结合性规则只能作用于同一级别的运算
当具有+,-,*,\,(,)时的文法

factor不可被分开.- 一个(不是因子)的
term可能被高优先级的运算符*和/分开 - 一个
expr可以被任意优先级分开 - 根据这种思想,我们可以用多个
非终结字符来确定n个优先级的语法.

2.2.7 2.2节的练习

从以下代码能看出如何增加一个优先级.

2.3 语法指导翻译
语法制导翻译是通过向一个文法的产生式附加一些规则或程序片段而得到的.

看不懂
2.3.1 后缀表示

2.3.2 综合属性

-
语法制导定义(syntax-directed definition)把每个文法符号和一个属性集合相关联,并且把每个产生式和一组语义规则(semantic rule)相关联,这些规则用于计算与该产生式相关联的属性值. -
注释语法分析树:如果一颗语法分析树的各个结点上标记了相应的属性值,那么这颗语法分析树就称为注释语法分析树,简称注释分析树.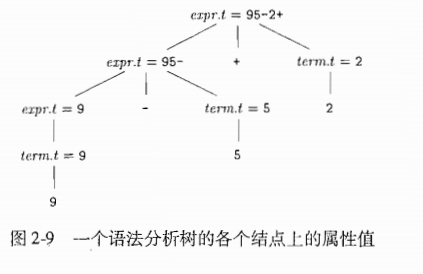
-
综合属性:如果某个属性在语法分析树结点N上的值由N的子节点和N本身的属性值确定,那么这个属性叫做综合属性- 性质: 只需要对语法分析树进行一次自底向上的遍历,既可以算出属性的值.
-
5.1.1节将会讲述一种
继承属性:继承属性在某个语法分析树的结点的值由其本身,兄弟,父节点属性值决定.
关于语法制导一个十分不错的例子

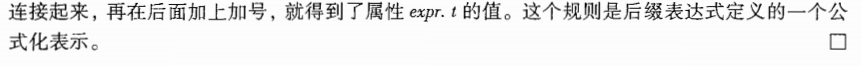
2.3.3 简单语法制导定义
上述例子的语法制导定义具有以下重要性质:

2.3.4 树的遍历
关于树的遍历就不再赘述了

- 如果只有综合属性,和继承属性单一一种,那么求值问题很好解决,否则很难求值.
2.3.5 翻译方案(语法制导翻译方案)
之前上述的语法翻译的例子将字符串作为属性值附加在结点上,从而得到翻译结果.
我们来考虑一种不需要操作字符串的方法,通过运行程序片段,逐步生成相同的翻译结果.
语义动作

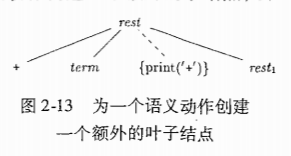
例子
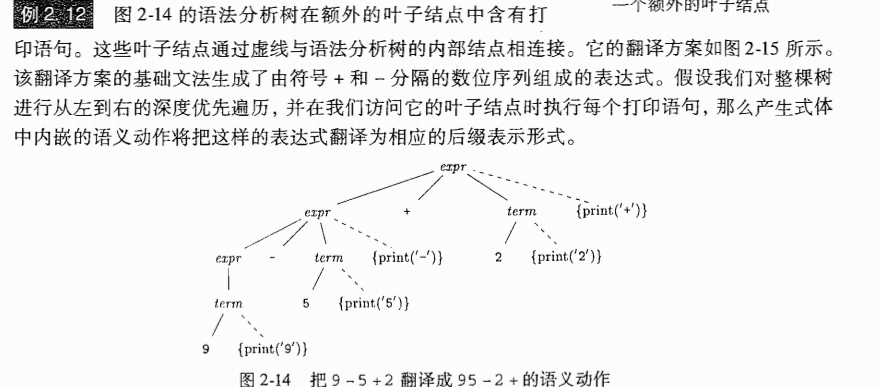
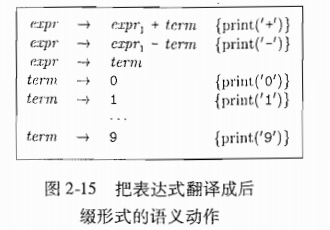
2.4 语法分析
-
语法分析是决定如何使用一个文法生成一个终结符号串的过程. -
本书将会介绍一种叫做
递归下降的语法分析方法,该方法用于语法分析和实现语法制导翻译器.- 下一节会给出一个完整实现例子的JAVA程序
- 4.9会介绍一种
Yacc的工具直接根据方案生成一个翻译器.
-
对于任何上下文无关法,都能构造出一个O(n^3)的语法分析器,但是对于实际的语言设计,基本都是线性时间构造出来的.
-
大部分的语法分析方法可以分为两类:
自顶向上,自底向上.- 这两个术语指的是语法分析节点的构造顺序.
- 在
自顶向上语法,构造过程从根节点开始,逐步向叶子节点进行.- 更容易手工构造出高效的语法分析器
自底向上语法则相反- 可以处理更多种文法和翻译方案,所以文法生成语法分析器的软件工具常常使用这种.
2.4.1 自顶向下分析方法


向前看(lookahead)
- 输入中当前被扫描的终结符号通常称为
向前看(lookahead)符号.- 在开始时,向前看符号是输入串的第一个终结符号.
例子
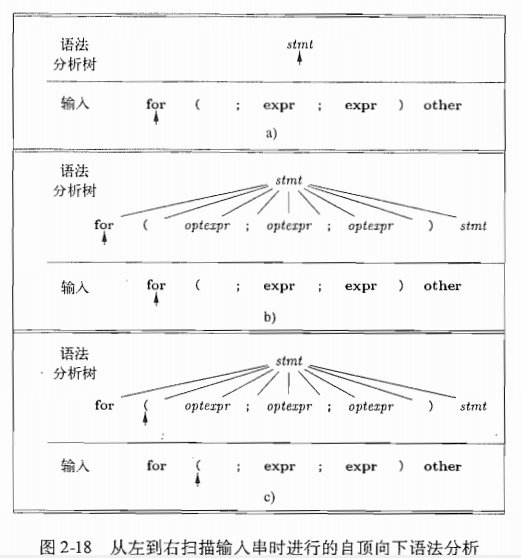
-
为一个非终结符号 选择产生式是一个尝试并犯错的过程,我们首先选择一个产生式,如果这个产生式不合适将会进行回溯,再尝试另一个产生式.
-
预测语法分析的特殊情况不需要回溯.
2.4.2 预测分析法
递归下降分析方法(recursive-descent parsing)是一种自顶向下的语法分析方法,他使用一组递归过程来处理输入.
这里我们考虑递归下降方法的一个简单形式,称为预测分析法(predictive parsing)
- 在
预测分析法中,各个非终结符对应的过程中的控制流可以由向前看无二义的确定.在分析输入串时出现的过程调用序列隐式地定义了该输入串的一颗语法分析树.

FIRST(α)

-
关于计算的方法在4.2.2中介绍
-

-
预测分析法要求
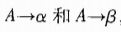 时
时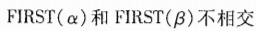
2.4.3 何时使用ε 产生式
- 如果向前看符号不在其他产生式中,就用ε 产生式
- 更加深入了解何时使用ε 产生式,参见4.4.3节中关于 LL(1)文法的讨论.
2.4.4 设计一个预测分析器
当满足能够使用预测分析器时:

-
对于语法动作如何处理


2.4.5 左递归

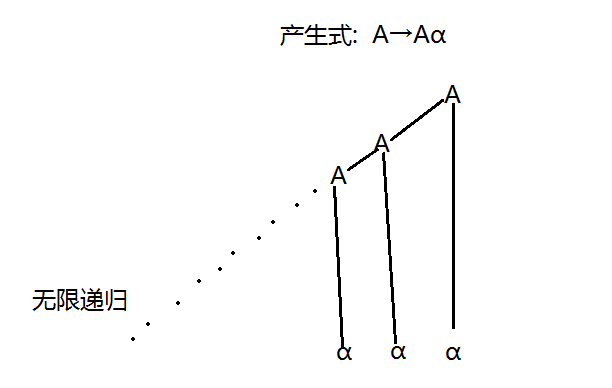
左递归:
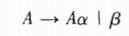
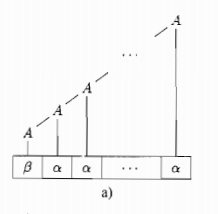
右递归:
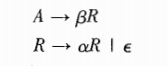
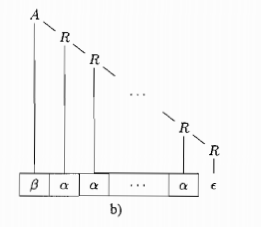
-
右递归对于左结合运算的翻译会变得困难
-
4.3.3节将考虑更一般的左递归形式
2.4.6 练习

-
(1)
void S(){ swithch( lookahead ) { case +: match(+);S();S();break; case -: match(-);S();S();break; case a; match(a);break; default: report("syntax error"); } } -
(2)要注意最终的结果,并消除左递归
void S(){
if(lookahead == "("){
match("("); S(); match(")"); S();
}
}
```
-
(3)两个产生式的FIRST都是0,需要注意
void S() { if(lookahead==0) { match(0); if(lookahead!=1) S(); match(1); } else report("syntax error"); }
2.5 简单表达式的翻译器
使用前三节技术,我们将使用Java语言编写一个语法制导翻译器.
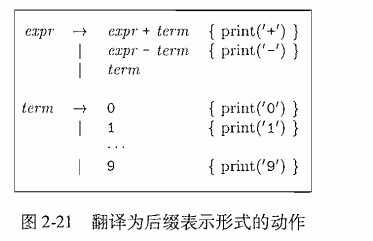
现在我们处于矛盾中:
-
一方面,我们需要一个能够支持翻译规约的文法;
-
另一方面,我们需要一个明显不同的能够支持语法分析过程的文法;
-
所以先使用易于翻译的文法,然后小心的转换,使之能够语法分析.
我们将消除2-21的左递归,得到一个适用于预测递归下降翻译器的文法.
2.5.1 抽象语法和具体语法
-
设计一个翻译器是,名为
抽象语法树(abstract syntax tree)的数据结构是一个很好的起点.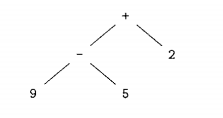
-
语法分析树叫做
具体语法树(concrete syn-tax tree),相应的文法叫做该语言的具体文法(concrete syntax)
2.5.2 调整翻译方案
2个左递归产生式和一个非左递归产生式 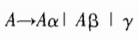
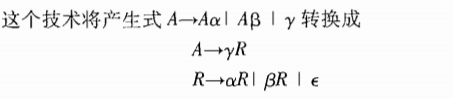
- 我们要转换的不只是终结符号和非终结符号,还包括内嵌动作.
- 嵌入在产生式中的语义动作在转换时被当做终结符号直接进行复制.
例子
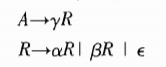

2.5.3 非终结符号的过程

2.5.4 翻译器的简化


2.5.5 完整代码


2.6 词法分析

2.6.1 剔除空白和注释

- 统计行号有利于定位错误
2.6.2 预读
一般都会预读一些字符放在缓冲区.有两个好处
- 缓冲区的效率问题,csapp有介绍就不多说了
- 有利于词法分析,判断是
>还是>=等 - 通常在简单的情况,只需要预读一个
本节的词法分析器会预读一个字符,本节中的词法分析器不变式断言如下:
当词法分析器返回一个词法单元时:
- 变量
peek要么保存当前词法单元词素后的那个字符,要么保存空白
2.6.3 常量

当在输入流出现一个数位序列时,词法分析器将向语法分析器传送一个词法单元.
- 该词法单元包括终结符
num和根据数位计算出来的值 如:<num,31>
2.6.4 识别关键词和标识符
-
关键词(keyword):大多数程序使用for,do,if这样的固定字符串作为标点符号,或者用于某种构造,这些字符串加做关键词. -
字符串还能作为标识符为变量,数组,函数等命名.
- 为了简化语法分析器,语言的文法通常把标识符当做终结符号处理.
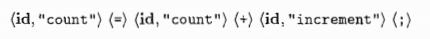
-
关键词通常也满足标识符的组成规则,当将关键词作为保留字时,相对容易解决.
对于本节中的词法分析器
使用一个字符串表来保存字符串.


2.6.5 词法分析器

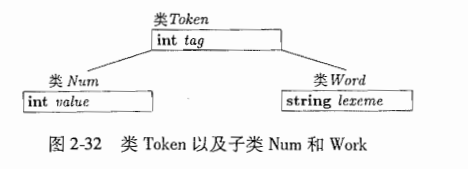





2.7 符号表
符号表(symbol table)是一种供编译器用于保存有关源程序构造的各种信息的数据结构.
- 在编译器分析阶段逐步收集
- 在综合阶段用于生成目标代码
- 标识符的字符串,词素,类型,存储位置,其他相关信息.
2.7.1 为每个作用域设置一个符号表


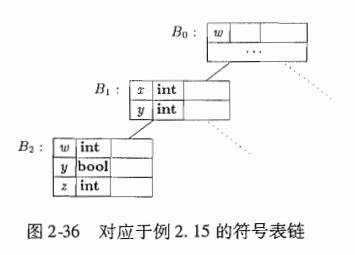
类Env
一颗 有前向边的树
支持三种操作
- 创建一个新符号表
- 加入新条目
- 得到标识符的条目

2.7.2 符号表的使用


2.8 生成中间代码
2.8.1 两种中间表现形式
两种最重要的中间表现形式
- 树形结构,包括语法分析树和(抽象)语法树
- 线性表现形式,特别是"三地址代码".
2.8.2 语法树的构造


- 可以发现从下到上的运算,运算级从高到低
语句的抽象语法树
在抽象语法树中表示语句块
表达式的语法树
2.8.3 静态检查

左值右值问题

类型检查
期望<=,>=之后的结构是boolean
- 自动类型转换
- 重载
2.8.4 三地址码
我们将说明如何通过遍历语法树来生成三地址代码.
具体来说,我们将显示如何编写一个抽象语法树的函数,并同时生成必要的三地址代码.
三地址指令

语句的翻译



- 类
If是类Stmt的一个子类. Stmt的子类都有一个构造函数和一个gengen是一个生成三地址代码的函数.
表达式的翻译
我们将考虑包含二目运算符op,数组访问,和赋值运算,并包含常量及标识符的表达式,以此来说明对表达式的翻译.
两个函数lvalue,rvalue





