[编译原理读书笔记][第一章 引论]
[编译原理读书笔记][第一章 引论]
标签(空格分隔): 未分类
第一章 引论
1.1 语言处理器
简单的说,一个编译器就是一个程序,它可以阅读以某一种语言(源语言)编写的程序,并把该程序翻译称为一个等价的,用另一种(目标语言)编写的程序。
-
编译器的重要任务之一是报告它在翻译过程中发现的错误。
-
解释器(interpreter)是另一种常见的语言处理器。直接利用源代码和输入来产生输出。
Java 结合了编译和解释过程。
- Java源代码首先被编译成一个称为
字节码(bytecode)的中间表现形式。- 然后
JVM对得到的字节码加以解释和执行。
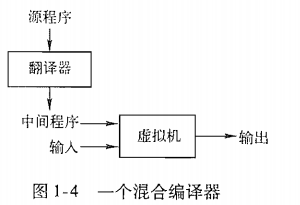
为了更快地完成输入和输出的处理,有些被称为
即使(just in time,JIT)编译器的JAVA编译器在运行中间程序处理输入的那一刻,首先把字节码翻译为机器语言,而不用解释器,这样能加快速度。
具体过程
出了编译器之外,创建一个可执行的目标程序还需要一些其他程序。
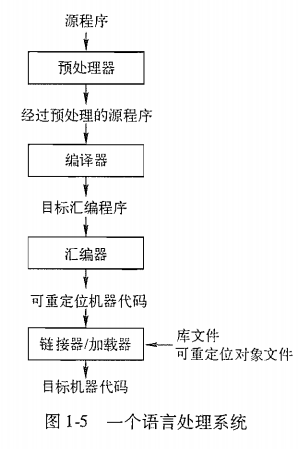
- 预处理器:一个程序可能被分为多个模块,存放于独立的文件中。把源程序聚合在一起的任务会由一个被称为
预处理器(preprocessor)的程序独立完成。- 预处理器还负责把宏的转为实际的语句。
- 编译器:预处理后的源程序经
编译器可能产生一个汇编语言作为输出。- 因为汇编语言容易调试和输出。
- 汇编器:汇编语言程序由
汇编器(assembler)的程序进行处理,生成可重定位的机器代码。 - 链接器/加载器:大型程序经常被分为多个部分进行编译。因此,可重定位的机器代码有必要和其他可重定位的目标文件以及库文件连接到一起,形成真正运行的代码。
链接器(linker)解决外部内存地址的问题。加载器(loader)把所有的可执行目标文件加载进内存执行。
1.2 一个编译器的结构
编译器由两部分组成:分析部分和综合部分
分析部分简述
分析(analysis)部分把源程序分解为多个组成要素,并在这些要素之上加入语法结构。然后,它使用这个结构来创建该源程序的一个中间表示。
- 如果分析部分检查出源程序有错误,必须提供有用的信息供用户修改。
- 分析部分还会收集源程序的信息,并存到
符号表(symbol table)的数据结构中。
符号表和中间表现形式一起传送给综合部分。
综合部分简述
综合(synthesis)部分根据中间表示和符号表中的信息构造用户期待的目标程序。
编译器详细过程简述
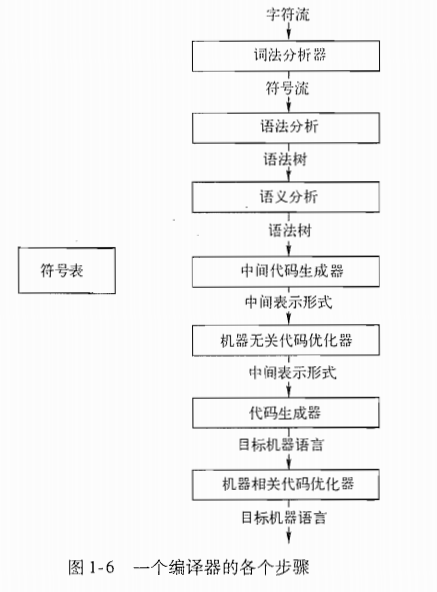
分析部分经常被称为编译器的前端,而综合部分被称为后端。- 有些编译器在前端和后端之间有一个与机器无关的优化步骤,是可选的。
1.2.1 词法分析
编译器的第一个步骤称为词法分析(lexical analysis)或扫描(scanning)。
词法分析器读入组成源程序的字符流,并且将它们组织成为有意义的词素(lexeme)的序列
- 对于每个
词素,词法分析器产生如下形式的词法单元(token)
<token-name,attribute-value>
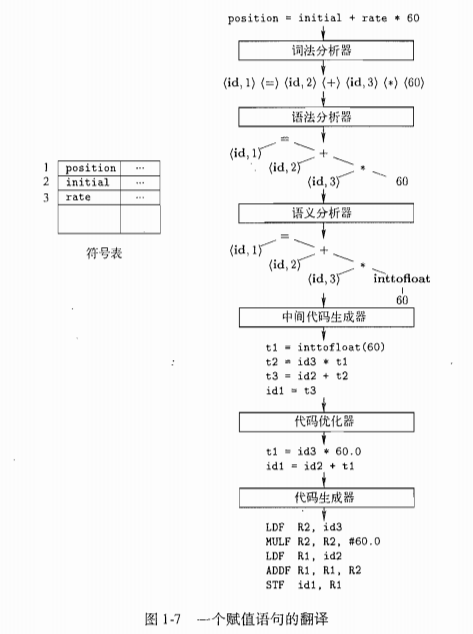
例子: position = initial + rate * 60
经过词法分析后转变为<id,1> <=> <id,2> <+> <id,3> <*> <60>
从技术上讲,60应该被描述为
<number,4>,4指向符号表中对应于60的条目。
1.2.2 语法分析
语法分析(syntax analysis)或解析(parsing)。
根据词法分析的结果,进行语法分析,结果一般是一颗语法树等语法结构,如图1-7。
编译器的后续步骤使用这个语法结构来帮助分析源程序,并生成目标程序。在第四章,我们将使用上下文无关文法来描述程序设计语言的语法结构,
1.2.3 语义分析
语义分析器(semantic analyzer)使用语法树和符号表中的信息来检查源程序是否和语言定义的语义一致。同时收集类型信息,并把信息存放在语法树或符号表中,以便在随后的中间代码中使用。
类型检查与自动类型转换
这就是语义分析中一个十分重要的功能,具体例子就是图中的inttofloat。
我们将在第六章详细介绍。
1.2.4 中间代码生成
将语法树等中间形式翻译为三地址代码的中间形式。
第六章我们将将详细介绍。
1.2.5 代码优化
机器无关的代码优化步骤试图改进中间代码,以便生成更好的目标代码。
以下是个简单的例子

优化为

第八章我们将详细讨论。
1.2.6 代码生成
生成类汇编语言的目标语言,

在第八章中详细讨论
上面代码忽略了对源程序中的标示符进行存储分配的重要问题。
我们将在第七章看到,编译器在中间代码生成或代码生成阶段对有关存储器分配的决定,和运行时刻的存储组织方式依赖于被编译的语言。
1.2.7 符号表管理
符号表管理记录源程序变量过程的各种信息
- 属性的存储分配,类型,作用域等信息
- 过程的参数数量,类型,每个参数的传递方式以及返回类型等。
符号表的数据结构
类似与平衡树红黑树之类的数据结构,便于查询。
1.2.8 将多个步骤组合为趟
(其实就是所谓的前后端分离的意思)
前端步骤可以当做一趟,根据中间代码生成目标代码的后端也可以看做一趟。
前端趟和后端趟根据目标自由搭配。
1.2.9 编译器构造工具。
- 语法分析器的生成器:根据程序语言的语法描述生成语法分析器
- 扫描器的生成器:可以根据一个语言的语法单元的正则表达式描述生成词法分析器。
- 语法制导的翻译程序:可以生成一组用于遍历分析树并生成中间代码的例程。
- 代码生成器的生成器:依据一组关于如何把中间语言的每个运算翻译为目标机上的机器语言规则,生成一个代码生成器。
- 数据流分析引擎: 可以帮助收集数据流信息,即程序中的值如果从程序的一个部分传递到另一个部分。数据流分析是代码优化的一个重要部分。
- 编译器构造工具集:
提供了可用于构造编译器的不同阶段的例程的完整集合。
1.3 程序设计语言的发展历史
1.3.1 走向高级程序设计语言
按时代分类
- 第一代语言:机器语言
- 第二代语言:汇编语言
- 第三代语言:高级程序设计语言
- 第四代语言:特定应用设计语言:生成报告的
NOMAD,用于数据库查询的SQL - 第五代语言:基于逻辑与约束语言:
Prolog和OPS5
按如何完成一个计算任务
- 强制式语言:
- 声明式语言:
函数式语言,约束逻辑式语言属于此类。
其他分类
- 过程式语言(冯诺伊曼语言)
- 面向对象语言
- 脚本语言
1.3.2 对编译器的影响
复杂多变的程序设计语言,对编译器及编译器设计人员也提出了极大的考验。
本书将会告诉我们编译器设计的根本思想和方法论。
1.4 构建一个编译器的相关科学
接收一个问题,抓住问题的关键特性的数学抽象表示,并用数学方法解决他。
1.4.1 编译器设计和实现中的建模
基本的几个模型
- 有穷状态自动机 *第三章
- 正则表达式 *第三章
- 上下文无关法 *第四章
- 树形结构 *第五章
1.4.2 代码优化的科学
- 优化是必须正确的
- 优化必须能改善程序的性能
- 优化需要的时间在合理范围内
- 所需要的工程方面的工作是需要可管理的
1.5 编译技术的应用
1.5.1 高级程序设计语言的实现
1.5.2 针对计算机体系的优化
并行和内存层次结构
- 并行性友好和缓存友好的代码。
1.5.3 新计算机体系结构的设计
RISC
- RISC 是未来的趋势,更加有利于编译器的优化,和处理器的优化。
- 对于CISC的X86 使用其精简指令是最高效的方法。
专用体系架构
- 百花齐放,需要更加好的编译技术为架构语言设计编译器。
1.5.4 程序翻译
二进制翻译
编译器技术可以用于把一个机器的二进制代码翻译成另一个机器的二进制代码,使得可以在一个机器上运行原本为另一个指令集编译的程序。
- 增加可用软件
- 提供向后兼容性
硬件合成
不仅仅大部分软件是用高级语言描述。大部分硬件设计也是使用高级硬件描述语言描述的。这些语言有Verilog和VHDL. 硬件设计通常通常是在寄存器传输层(Register Transfer Level,RTL)描述.
数据查询解释器
编译然后模拟
1.5.5 软件生产效率工具
- 数据流分析技术静态的定位错误
- 错误探测器可以是不健全的.
类型检查
- 运算被作用在错误类型的对象上.
- 传递给一个过程的参数和该过程的范型不匹配
- 通过分析数据流,还能发现空指针被释放.
- 用来捕捉安全漏洞
边界检查
- 一般在较低级语言更容易犯
内存管理工具
1.6 程序设计语言基础
1.6.1 静态和动态的区别
- 静态策略:如果一个语言使用的策略支持编译器决定某个问题.
- 动态策略:只允许在运行程序的时候做出决定的策略.
1.6.2 环境与状态
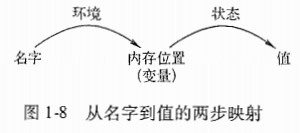
1.6.3 静态作用域和块结构
- begin end
1.6.4 显示访问控制
public,private,protecte
1.6.5 动态作用域
- x.m();
1.6.6 参数传递机制
- 值调用
- 引用调用
- 名调用:
Algol 60使用


