

声纹识别算法阅读之CN-Celeb
论文:
CN-Celeb: A CHALLENGING CHINESE SPEAKER RECOGNITION DATASET
思想:
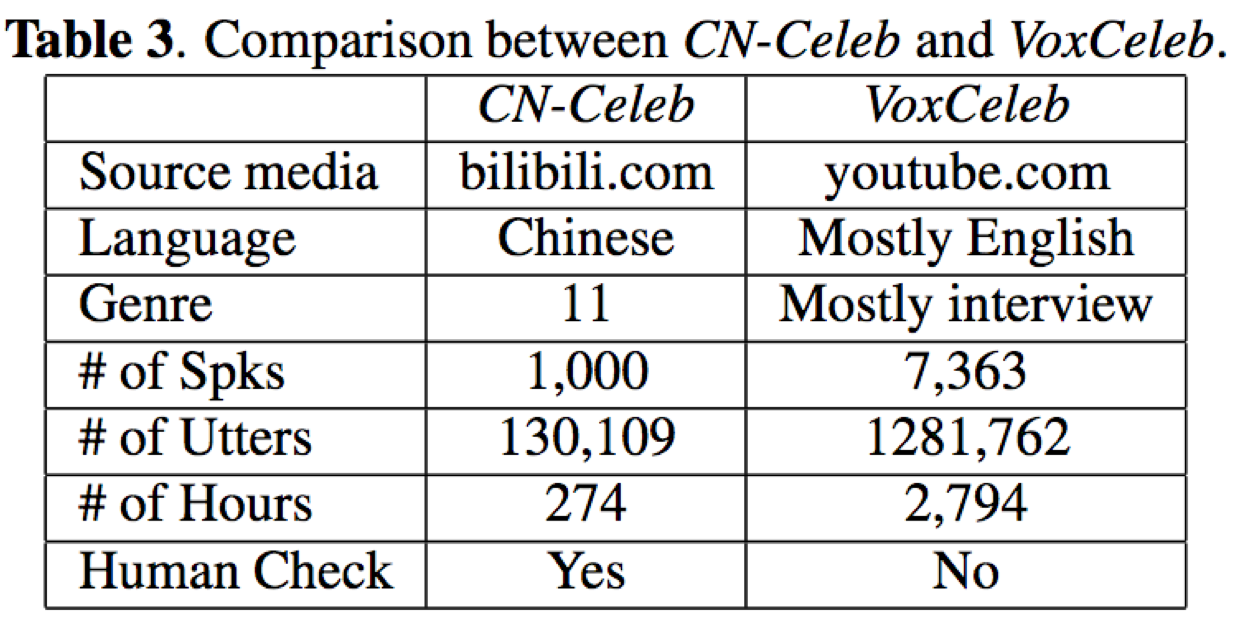
论文的贡献在于提供了一个非约束条件下的大规模中文说话人识别数据集,该数据集包含环境、通道与情感的变化。这是与现目前大多数开源说话人识别数据集(约束条件,很小的噪声和通道变化)的最大区别。该数据集包含1000个说话人,共计约13万个句子,总时长274小时,涵盖了11种真实场景下的不同类型。作者在两个比较流行的说话人识别算法i-vector和x-vector上做了实验,并与英文说话人识别自然场景数据集voxceleb进行对比,从实验结果看,一方面能够表明CN-Celeb的更具挑战性,另一方面也可看出非约束条件下的说话人识别的真实效果还有待提高。
CN-Celeb:
- 数据分布:CN-Celeb数据集跨越11种真实的场景,每一个说话人至少包含5种不同的场景录音。
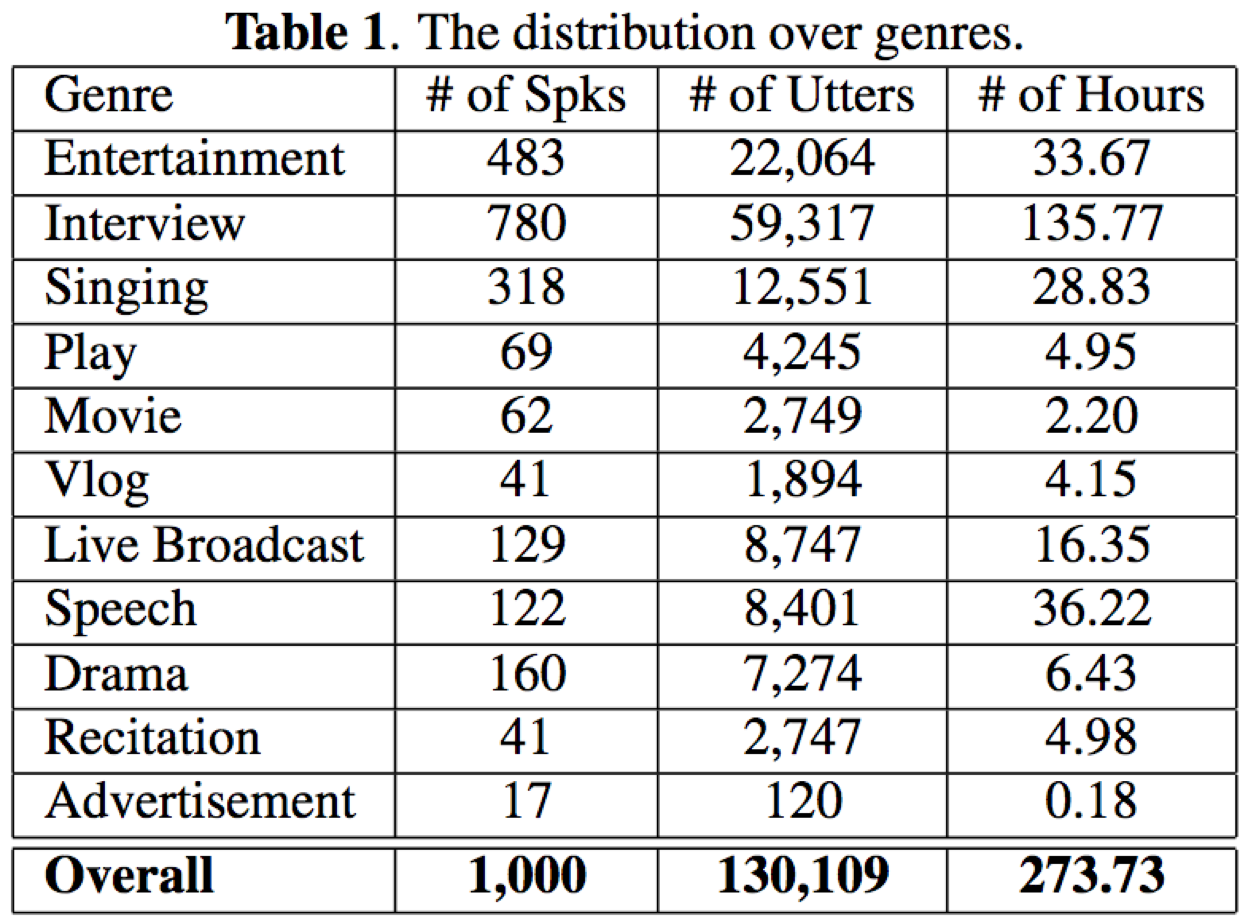
- 挑战性:
- 录音包含真实噪声,比如背景babble、music、cheer、laugh等
- 录音包含背景说话人重叠
- 录音包含不同的场景,娱乐、电影、采访等
- 同一说话人录音来源不同的时间,通过不同的设备进行采集得到
- 录音包含短句
训练:
- 训练集:
- voxceleb:7185 speakers 1,236,567 utts
- CN-Celeb:800 speakers 111260 utts
- 验证集:
- SITW: 299 speakers 6445 utts
- CN-Celeb:200 speakers 18849
- 模型:
- voxceleb:
i-vector+PLDA:https://github.com/kaldi-asr/kaldi/tree/master/egs/voxceleb/v1,GMMs(2048)、i-vector(400)
x-vector+PLDA:https://github.com/kaldi-asr/kaldi/tree/master/egs/voxceleb/v2
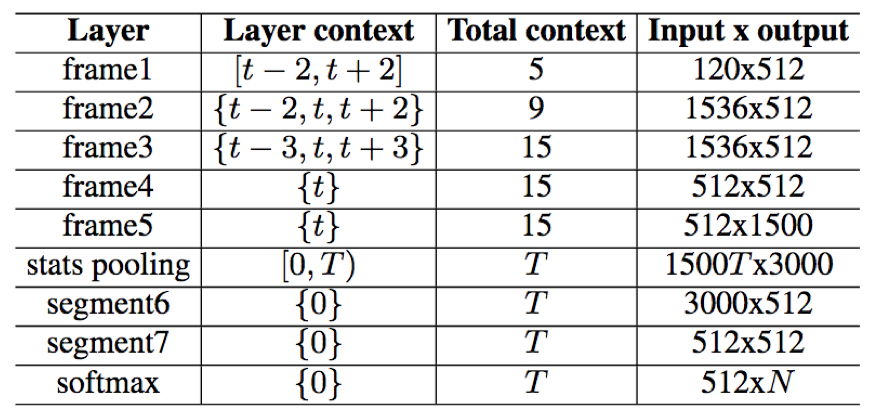
- CN-Celeb:i-vector+PLDA:https://github.com/kaldi-asr/kaldi/tree/master/egs/cnceleb/v1
x-vector+PLDA:https://github.com/kaldi-asr/kaldi/tree/master/egs/voxceleb/v2 ,TDNN节点由voxceleb中的512减少到256
实验:
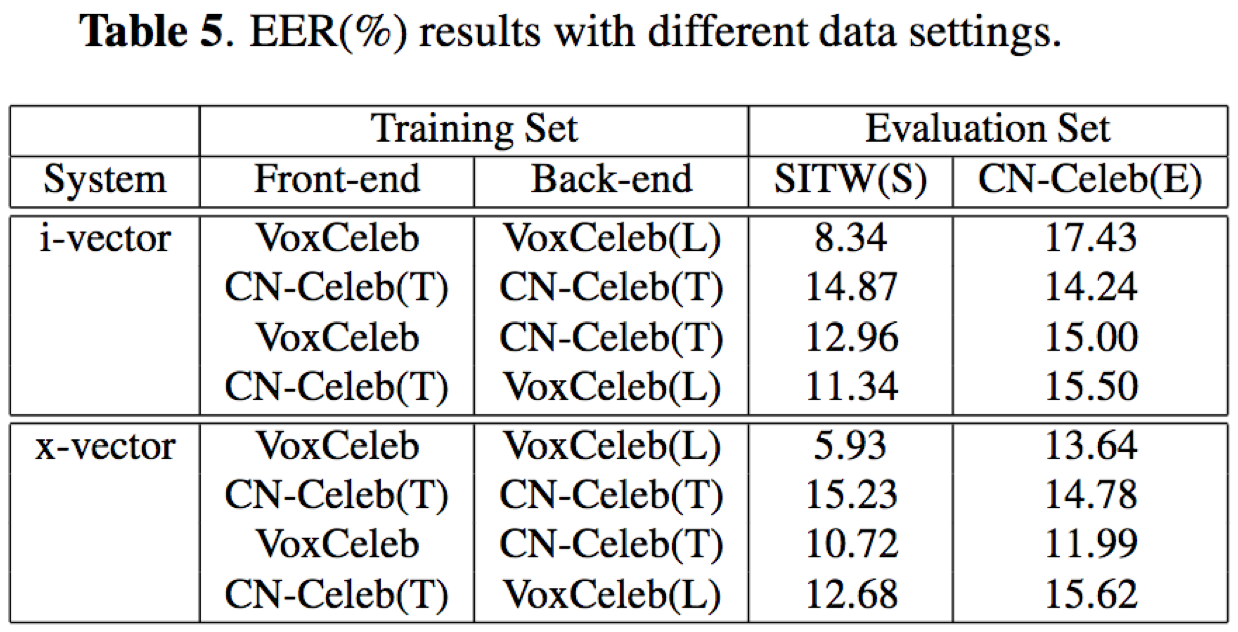
- 前端(i-vector、x-vector)和后端(PLDA)全部采用voxceleb训练条件下:在SITW上最好结果为EER=3.75%,在CN-Celeb上最好为15.52%
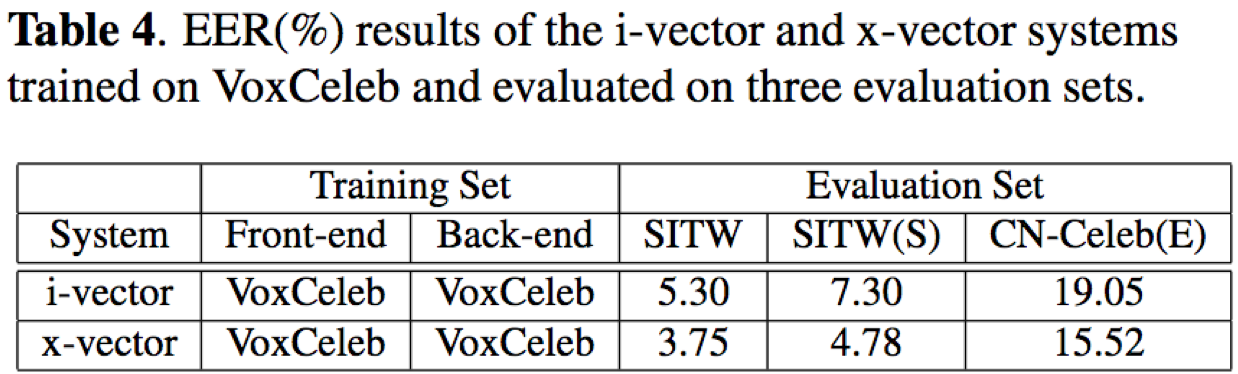
- 前端和后端采用不同训练集搭配时,在CN-Celeb可以取得不错的结果,比如x-vector(voxceleb)+PLDA(CN-Celeb)的训练模式,在CN-Celeb验证集上能够取得最好的实验结果11.99%
结论:
论文的贡献在于提供了一个非约束条件下的大规模中文说话人识别数据集,该数据集包含1000个说话人,共计约13万个句子,总时长274小时。数据集包含环境、通道与情感的变化,涵盖了11种真实场景下的不同类型。此外,论文还通过实验表明了,结合voxceleb训练x-vector+CN-Celeb训练PLDA的搭配训练模式能够在CN-Celeb验证集上取得最好的实验效果
实战:结合voxceleb v2(https://github.com/kaldi-asr/kaldi/tree/master/egs/voxceleb/v2)、CN-Celeb v1(https://github.com/kaldi-asr/kaldi/tree/master/egs/cnceleb/v1),实现的基于kaldi的CN-Celeb v2 x-vector+PLDA训练脚本,详见github:https://github.com/zhaoyi2/xvector-cnceleb
效果:
- x-vector(cn-celeb) + PLDA(cn-celeb)
CN-Celeb Eval Core:
EER: 16.71%
minDCF(p-target=0.01): 0.7657
minDCF(p-target=0.001): 0.8823
- x-vector(voxceleb) + PLDA(cn-celeb)
CN-Celeb Eval Core:
EER: 12.43%
minDCF(p-target=0.01): 0.6064
minDCF(p-target=0.001): 0.7381
注:没有去精细调参数或者添加一些前置优化项,如果你愿意去做这些的话,也许能够达到与论文中可比的效果
Reference:
[2] voxceleb:http://openslr.org/49/
[3] 开源voxceleb模型:https://kaldi-asr.org/models/m7
[4] CN-Celeb:http://openslr.org/82/

