

语音识别算法阅读之transformer-transducer(facebook)
论文:
TRANSFORMER-TRANSDUCER:END-TO-END SPEECH RECOGNITION WITH SELF-ATTENTION
思想:
1)借助RNN-T在语音识别上的优势,通过tranformer替换RNN-T中的RNN结构,实现并行化运算,加快训练过程;
2)encoder部分前段引入包含因果卷积的VGGNet,一方面缩短声学特征的时序长度,节约计算,另一方面融合上下文信息(包含位置信息)到后续的attention模块;
3)采用截断的attention机制,控制左右上下文时间片的长度,降低延迟,attention计算复杂度由O(T2)降低为O(T),满足流式语音识别任务的需要
模型:
- RNN-T:包含encoder网络、语言模型预测网络和联合网络三个模块;

- encoder网络 :一般由多层Bi-LSTM组成,输入时序的声学特征,得到高层次的特征表达
- 语言模型预测网络:一般由多层uni-LSTM组成,输入标签对应的embedding,输出对应的预测编码
- 联合网络:一般由多层全连接层组成,输入为两个编码的线性组合,输入到由前馈神经网络中得到预测字符概率分布函数
- 目标函数:输出单元为{字符集Z+blank};目标为最大化标签序列对应所有对齐序列的概率和;
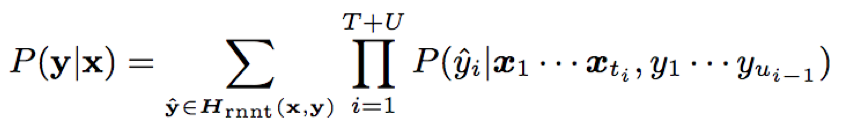
y^= (y1^,y2^,···yT+U^)∈Hrnnt(x,y)⊂{Z∪b}T+U,y^满足:去重复连续字符和去blank后为对应的标签序列y;
- RNN-T解决了CTC的条件独立性假设(当前预测输出与历史输出条件独立),即预测输出不仅取决的encoder,还取决于历史预测输出;CTC目标函数如下:

- RNN-T预测时:当预测输出yu为blank时,预测网络的输入不变,encoder网络输入更新为xt+1;当yu为non-blank时,预测网络输入更新为yu,encoder网络输入保持为xt;
- transformer:transformer是一种非循环的self-attention结构,由多个multi-head attention和feed-forward network组成的子墨块串联而成,能够得到高层次的特征表达
- multi-head attention:包含三个输入:Q、K、V,分别被转化到多个self-attention子空间学习时序依赖,最后再将各个子空间输出进行合并,得到高层次的特征表达

其中,H代表self-attention个数;ei代表第i个self-attention子空间,WO、WQ、WK、WV分别为线性层的权重项,ei计算公式如下
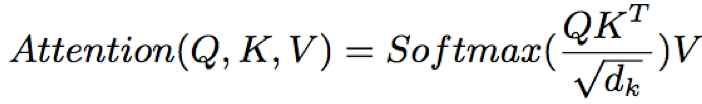
其中,√dk为缩放因子,防止dk较大时,QKT较大,导致训练不稳定
- feed-forward network:由多层全连接层组成,激活函数ReLU
- Layer norm:对multi-head attention和feed-forward network输入进行归一化,加速训练
- position embedding:引入位置信息,弥补attention对时间顺序和文本位置的不敏感性
- resnet connection:保证浅层信息的流入,并且使得训练更稳定
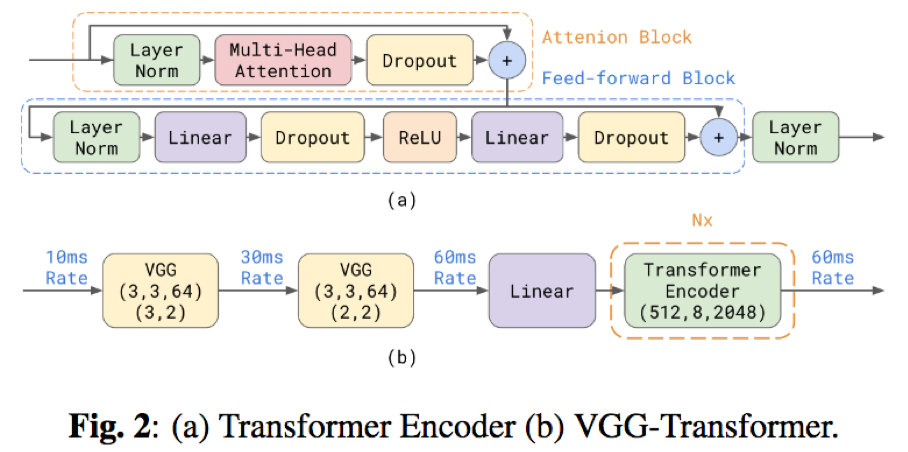
- VGG-transformer:由VGGNet和transformer串联而成,VGGNet一方面能够具有较强的上下文建模能力,另一方面可以缩短声学特征的时序长度,提升计算效率;transformer encoder一方面,能够并行化运算,加速训练过程;另一方面利用了attention在处理长时依赖方面的优势
- VGGNet采用causal convolution结构:时序的声学特征可以看做以时间为横轴,频率为纵轴的二维图像,这样可以利用二维卷积进行上下文建模和降低帧率
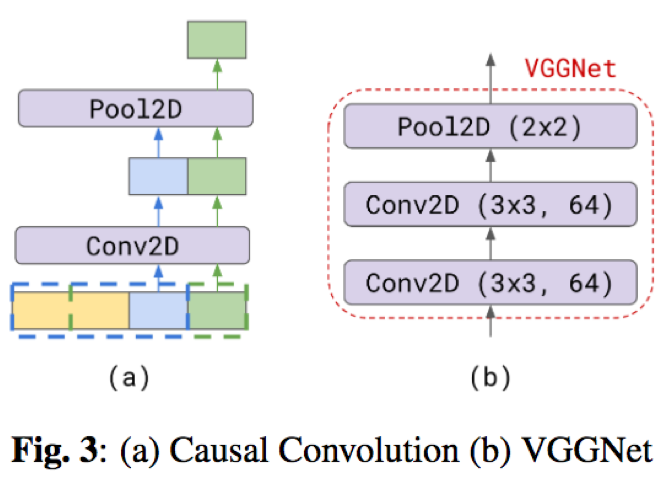
二维卷积conv,对于卷积核大小为N*K的卷积,其覆盖范围为:

causal conv结构相当于一种特殊的二维卷积,即在卷积计算时仅利用历史的上文信息,不利用未来的时序信息;这样覆盖范围为:

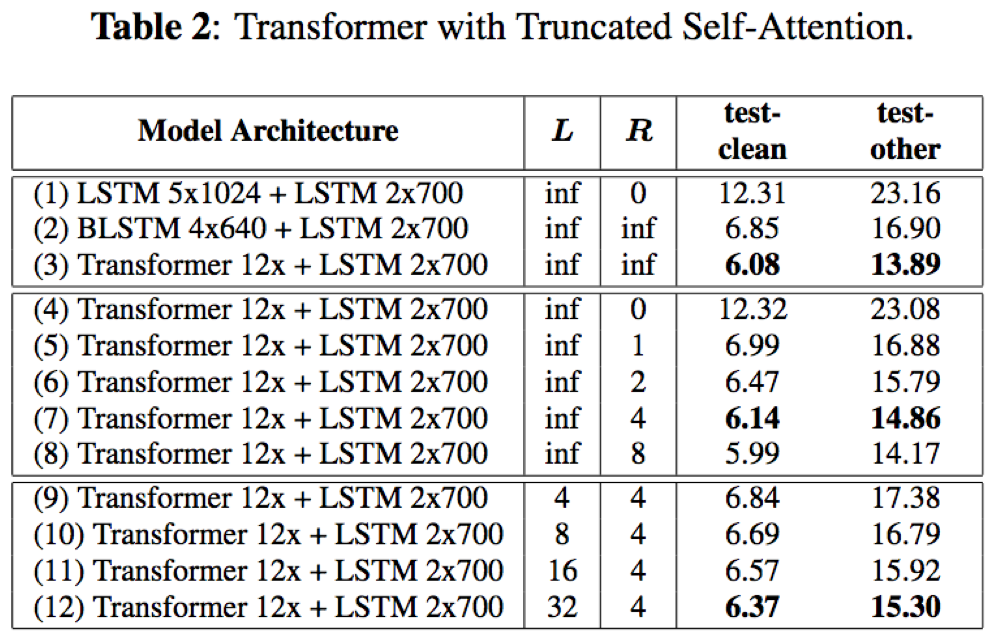
- transformer采用截断的attention,即仅利用有限长度的时序上下文信息,有效降低延迟和计算,以适应某些场景下的设备语音识别要求

其中,inf表示利用所有的时序信息;L=5,R=3表示利用历史和未来的声学特征帧数;通过此,可以将原始的复杂度O(T2)转化为O(T),但是会相应的损失一部分精度
训练:
- 数据集:LibriSpeech 960h,验证集和测试集{dev, test}-{clean,other}
- 输入特征:80维log fbank,global CMN(全局均值归一化),帧率=33.3hz
- 网络结构参数:
- encoder选项:1)BiLSTM 4*640;2)LSTM 5x1024;3)transformer 12x:2层VGGNets(3*3*64,max-pooling1=3,max-pooling2=2)+12层transformer(input=512,head nums=8,feed-forward inner-hidden-size=2048)
- 预测网络选项:1) LSTM 2x700;2)Transformer 6x: 一层VGGNets(3*3*64,no max-pooling)+6层6transformer(input=512,head nums=8,feed-forward inner-hidden-size=2048),且attention的attend下文时序信息R=0,即不利用未来的时序信息
- 联合网络:对encoder输出ht和预测输出pu进行线性组合,输出预测字符的概率分布
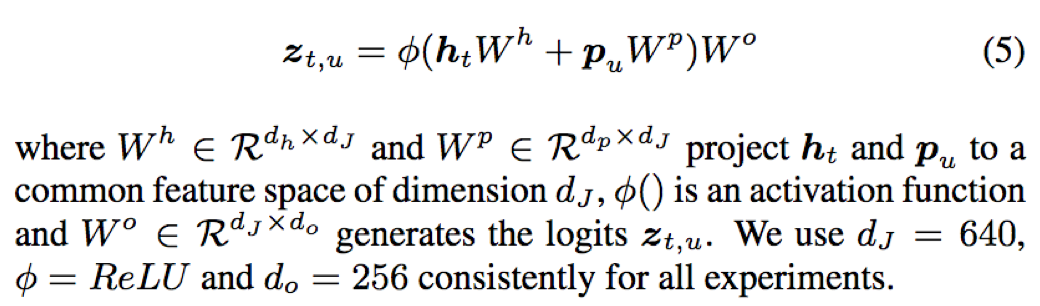
其中Wh、Wp、Wo分别为ht、pu、zt,u的权重项
实验结果:
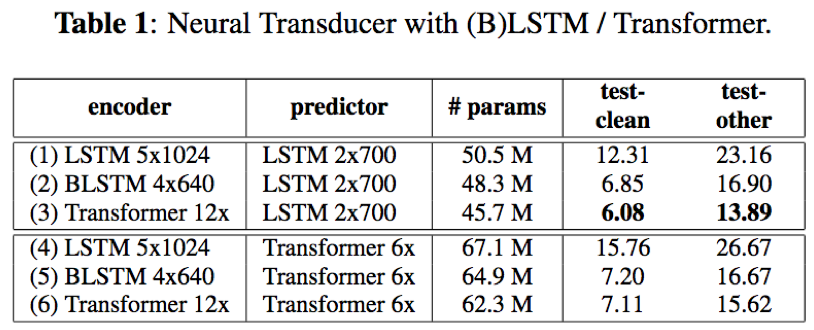
- encoder网络+预测网络:transformer 12x + LSTM 2*700结构取得了最好的结果,相比于其他LSTM、BLSTM、transformer之间的相互组合
- attention的上下文时序信息宽度L、R对识别结果均会造成一定的影响;缩短上下文时序信息宽度L、R的宽度均会造成一定的识别精度损失,但同时节约计算和降低延迟;采用有限宽度的上下文时序信息,可以将计算复杂度由O(T2)减小到O(T);实际可以根据场景对于精度和延迟、计算的要求进行权衡
结论:
- 利用transformer替换RNN-T中的RNN结构,一方面利用attention的长时序列建模优势,另一方面实现并行化计算,加速训练
- VGGNet的引入对上下文信息进行建模,同时缩短声学特征的时序长度节约计算
- transformer采用截断的self-attention,在损失可接受范围内的精度条件下,有效节省计算和降低延迟,以满足设备语音识别对于延迟和计算的要求
Reference:

