

语音识别算法阅读之transformer-transducer(google)
论文:
TRANSFORMER TRANSDUCER: A STREAMABLE SPEECH RECOGNITION MODELWITH TRANSFORMER ENCODERS AND RNN-T LOSS
思想:
论文作者借助RNN-T的整体架构,利用transformer替换RNN结构;因为transformer是一种非循环的attention机制,所以可以并行化计算,提升计算效率;此外,作者还对attention的上下文时序信息宽度做了限制,即仅利用有限宽度的上下文时序信息,在损失较小精度的条件下,可以满足流式语音识别的要求;还有一点是,作者表明当transformer采用非限制的attention结构时,在librispeech数据集上能够取得state-of-the-art的识别效果
说明:该轮文思路跟facebook的论文[1]基本一致,都是采用transformer替换RNN-T中的RNN结构,且均从限制attention上下文时序信息的宽度角度考虑,降低计算和延迟;但二者在细节方面略有不同,比如输入特征维度、数据增强、模型大小、结点参数、位置编码产生方式等均有所不同;此外,该轮文在解码时采样了语言模型融合的策略,提升识别效果;
模型:
模型以RNN-T为整体框架,包含transformer encoder网络、transformer预测网络和feed-forward联合网络;损失采用的RNN-T的损失,即最大化标签序列对应所有对齐的概率和;
- transformer encoder:由多个block堆叠而成,每个block包含layer norm、multi-head attention、feed-forward network和resnet connection;

- 每个block的输入都会先进行layer norm进行归一化,使得训练稳定,收敛更快
- multi-head attention有多个self-attention(Q=K=V)并连而成,输入特征被转换到多个子空间进行特征建模,最后再将各个子空间的输出进行合并,得到高层次的特征编码;需要说明的是,为提升计算效率,可以对attention所关注的上下文时序信息宽度进行控制;
- feed-forward network由多层全连接串联而成,激活函数为ReLU;并且训练时采用dropout防止过度拟合
- resnet connection的采样一方面能够为上层提供更多的特征信息,另一方面也使得训练时反向传播更加稳定
- transformer 预测网络:具有跟encoder类似的结构,只不过预测网络的attention不能利用未来信息,所以网络的attention仅限定在历史的状态;此外,作者还通过限定attention的历史状态个数来降低计算复杂度,O(T2)->O(T)
- feed-forward联合网络:encoder的输出和预测网络的输出进行线性组合之后,输入到联合网络进行任务化学习;网络由多层全连接层组成,最后一层为softmax;网络的输出为后验概率分布

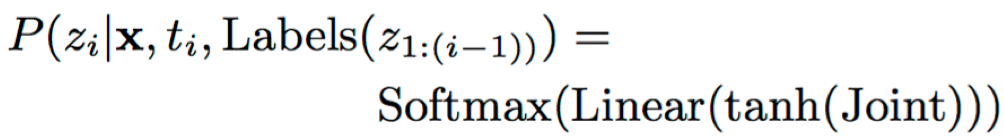
其中,AudioEncoder、LabelEncoder分别为encoder网络和预测网络输出;P为联合网络输出的后验概率;ti为时间序号;Label(z1:i-1)表示预测网络的历史non-blank输出序列
Loss:网络的目标是最大化标签序列对应的所有对齐的概率和,取负号是可转化成最小化;
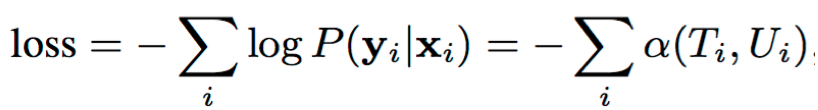
其中,P(yi|xi)代表第i个样本的标签序列对应的所有可能对齐的概率和;α(Ti,Ui)是采用前向算法计算得到的对齐路径的概率和,前向算法在每个时间步上对路径进行合并并更新累计概率变量α(t, u),实现高效的概率计算过程,α(t, u)表示为在时间t,经过状态u的所有路径的概率和;
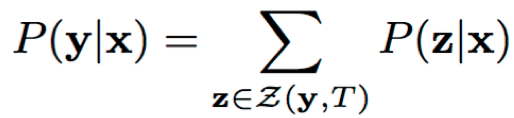
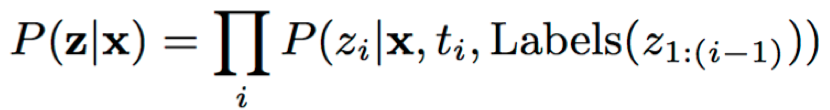
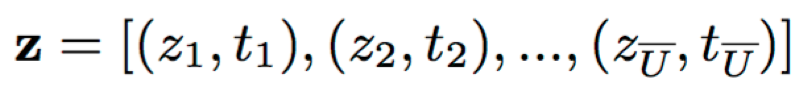
其中,(zi,ti)表示输出与ti时刻编码特征的对齐
训练:
- 数据集:语音数据集:LibriSpeech 970hours;文本数据集:LibriSpeech对应10M文本+额外800M本文
- 输入特征:128log fbanks;下采样帧率33.3hz;
- 特征增强specaugment[2]:通过[2]进行增强,仅采样时间掩蔽和频率掩蔽,且frequency masking(F = 50,mF = 2)andtimemasking(T = 30,mT = 10)
- 模型参数:
- transformer encoder网络:18*block(feed-forward(layer-norm(x)+attentionlayer(layer-norm(x)))

- 预测网络:2*block(feed-forward(layer-norm(x)+attentionlayer(layer-norm(x)))
- 联合网络:一层全连接(激活tanh)+一层softmax
- 学习率策略:ramp-up阶段(0~4k steps):从0线性ramp-up到2.5e−4;hold阶段(4k~30k steps):保持2.5e−4;指数衰减阶段(30k~200k steps):衰减到2.5e−6为止
- 高斯噪声(10k steps~):训练时模型的权重参数引入高斯噪声,提升鲁棒性,高斯参数(μ = 0, σ = 0.01)
实验结果:
- 当T-T的encoder采样full时间序列attention时,效果优于BiLSTM的encoder结构;此外当T-T采用transformer结构的语言模型融合时能够取得可比state-of-the-art的结果

- 对于encoder网络,缩短attention利用的左右上下文时间序列宽度均会造成识别错误率的上升;对于预测网络,其attention结构不利用未来的时间状态信息,但缩短其利用的历史状态个数也会造成识别错误率的轻微上升;不过,当合理控制上下文状态的个数,可以使得对识别结果的影响比较轻微
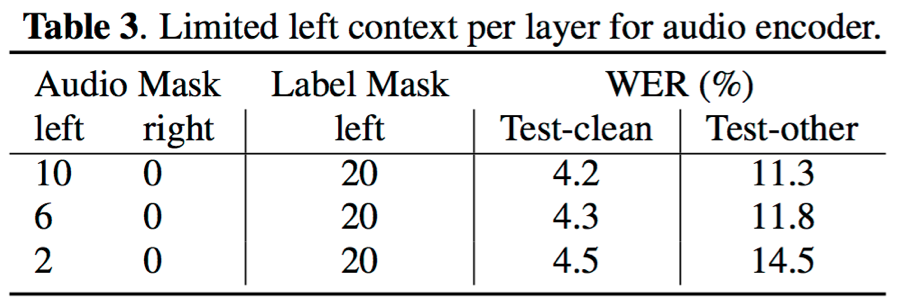

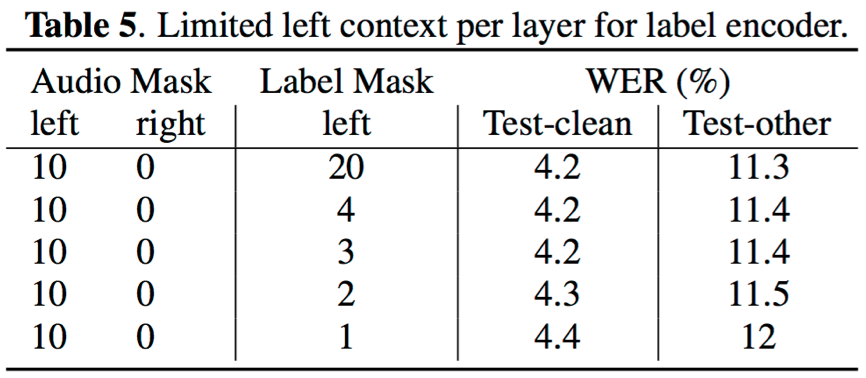
- 对于一个n层的transformer网络,当right context=1时,当前步的输出需要的延迟时间为(n-1)*30ms;如下图,当n=3、帧率为33.3hz时,预测y7时的延迟为90ms

- 训练速度:在参数量相似的条件下,T-T相对于基于LSTM的RNN-T训练速度提升3.5倍(1 day:3.5 days)
结论:
- 提出了一种基于transformer的端到端的RNN-T结构,称之为Transformer Transducer;该模型,一方面借助transformer的非循环结构,网络可并行化计算,显著提升训练效率;另一方面,在LibriSpeech数据集上取得了新的state-of-the-art的效果
- Transformer Transducer还允许控制attention利用的上下文状态个数,从而有效降低延迟和计算,在精度轻微损失的条件下,满足流式语音识别的要求
Reference:

