
语音识别算法阅读之SpeechTransformer(large mandarin)
论文:
THE SPEECHTRANSFORMER FOR LARGE-SCALE MANDARIN CHINESE SPEECH RECOGNITION
思想:
在speechTransformer基础上进行三点改进,
1)降低帧率,缩短声学特征的时序长度,在大规模语音数据训练时提升计算效率;
2)decoder输入采样策略,如果训练时,decoder部分输入全部采用label,而预测时decoder部分为前一时刻预测输出,这样训练和预测之间会存在一定的偏差,为缓解该问题,在训练decoder时,以一定的采样概率决定该时刻decoder输入是否采用前一时刻的预测输出;
3)Focal Loss,因为模型是以字符为建模单元的,在训练语料中很难保证每个字符的出现频率基本相近,相反字符之间可能存在较大的频次差异,这就会导致类别之间的不均衡问题,为缓解该问题,在计算loss时,对于分类概率大的样本进行降权,对分类概率小的样本进行升权,这样会使得模型更加关注被误分类的hard样本;
模型:
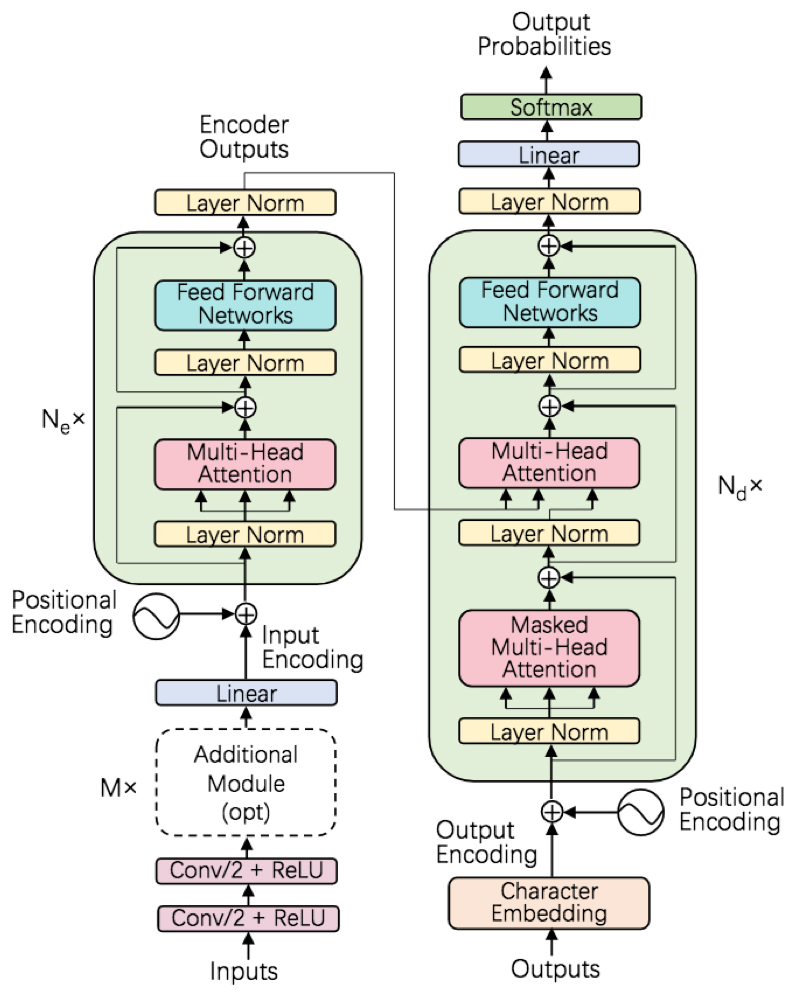
模型整体框架采用的即是transformer的encoder-decoder形式,主要包含几个模块
- multi-head attention模块,该模块是一种非循环的attention机制,思想有些类似于模型融合,即先将输入声学特征转换到多个不同的attention子空间分别学习特征表达,然后再将各个子空间的输出进行拼接,得到具有较高特征表达能力的encoder
- feed-forward network,前馈网络由一到两层全连接组成,全连接激活函数ReLU
- resnet connection,在每个multi-head attention模块和feed-forward network的输出位置条件添加resnet connection,保证浅层信息传播和训练稳定性
- Layer norm,在每个multi-head attention模块和feed-forward network的输入之间添加Layer norm,归一化输入的分布,保证训练稳定性
- 位置编码,对encoder和decoder的输入进行位置编码add操作,引入绝对位置和相对位置信息,缓解attention对于时间顺序和位置信息的不敏感性
tricks:
- 低帧率,对特征提取后的frames进行降采样,原始帧率为100hz,每帧10ms,降采用后的帧率为16.7hz,每帧60ms,在大规模语音识别,尤其对于长时语音输入,降低帧率到合适的大小,在几乎不影响精度的同时,可加快计算效率
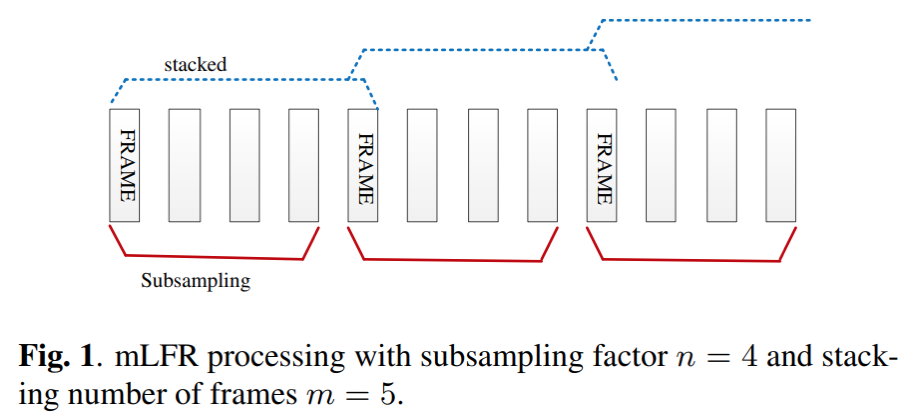
上图,对应采样因子为4,那么采样后的帧率为100/n=25hz,每帧1000/25=40ms
- deocder输入采样,如果decoder在训练时输入完全采用label对应编码作为输入,而预测时deocder输入为上一时刻预测输出,这样造成训练和预测之间会存在一定的偏差,为缓解该问题,可以以一定的概率决定在该时刻是否采用上一时刻的预测输出作为deocder输入;此外,因为模型在训练初始阶段,预测能力较差,所以预测不够准确,以此做为decoder输入可能影响模型训练稳定性,所以,在训练初始阶段采用较小的采样概率,而在训练中后期时采用较大的采样概率;概率的变化趋势有如下三种选择:
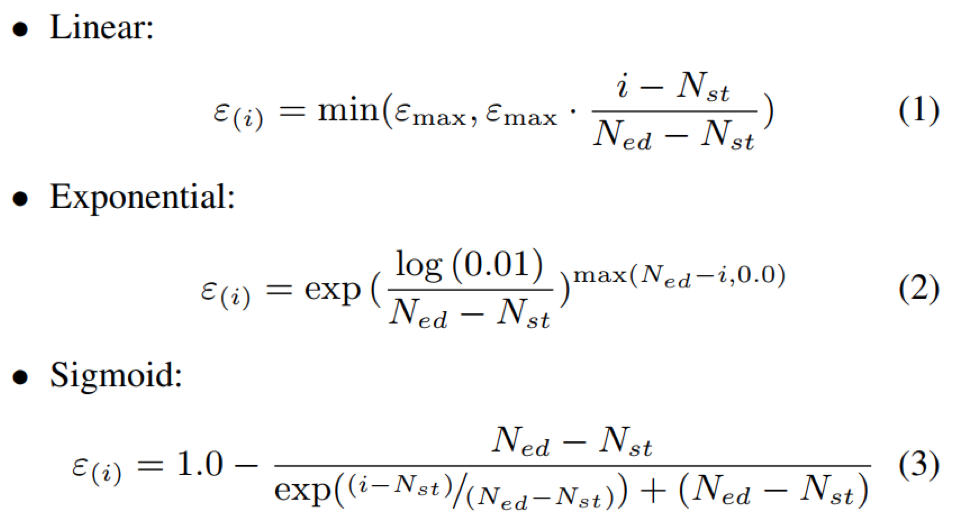
其中, 0 < εmax ≤ 1,Nst为采样开始的step,Ned为采样概率达到max的εstep,i为当前step,ε(i)为当前的采样概率
- Focal Loss,模型是以字符为建模单元时,训练语料中很难保证每个字符的出现频率可能相差很大,导致类别之间的不均衡问题,为缓解该问题,在计算loss时,对于分类概率大的样本进行降权,对分类概率小的样本进行升权,这样会使得模型更加关注被误分类的hard样本;

上式中,γ 属于 [0, 5],对于pt较大的类别,其在损失中的权重项越小,比如当pt=0.9时,γ=2,那么其权重缩小了(1-0.9)^2=1/100,反之,预测概率越小,其权重越大;该策略使得模型训练更关注被误分类的样本
训练:
- 训练数据集:8000小时中文普通话数据
- 验证集:aishell-1 dev 14326utts
- 测试集:aishell-1 test 7176utts;LiveShow:5766utts;voiceComment:5998utts
- baseline:TDNN-LSTM,7*TDNN(1024)+3*LSTMP(1024-512)+4-gram LM
- 输入特征:40 MFCCs,global CMVN,batch_size=512
- 输出单元:5998中文字符+<UNK>+<PAD>+<S>+<\S>=6002
- speechTransformer模型参数:6*encoder+4*decoder,dmodel=512,head=16
- 优化方法:Adam,β1 = 0.9, β2 = 0.98, ε = 10−9
- 学习率:n是迭代次数,k为可学习缩放因子,学习率在前warmup_n迭代步数线性上升,在n-0.5迭代次数时停止下降
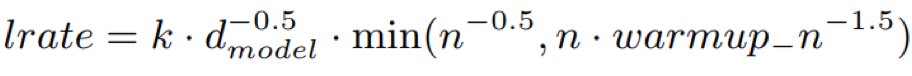
- 标签平滑策略[1]:降低正确分类样本的置信度,提升模型的自适应能力,ε=0.2
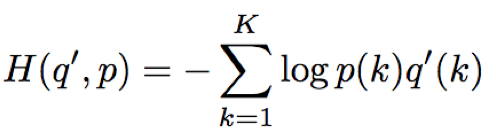
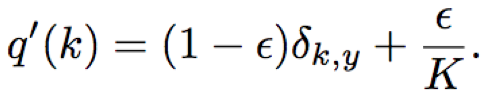
其中,H为cross-entropy,ε为平滑参数,K为输出类别数,δk,y=1 for k=y and 0 otherwise
- 模型训练后,以最后15个保存的模型的平均参数,做为最终模型
- 验证时,beam search的beam width=3,字符长度惩罚α = 0.6
实验结果:
- speechTransformer与TDNN-LTSTM混合系统在几个测试集上性能相近;具体地,在aishell-1 test/dev和voiceCom上略差于混合系统;在liveshow上略优于混合系统;
- 降低帧率时,识别效果呈现先上升后下降的趋势,当帧率=17.6hz,即60ms每帧时,在提升计算效率的同时,得到最佳的识别效果

- 三种decoder输入采用中,线性采样的效果最好,并且采样概率在训练初始阶段稍小,而在训练后期阶段稍大

- Focal Loss的应用可以对识别效果带来进一步的提升

结论:
在speechTransformer基础上进行一系列的改进,1)低帧率,提升计算效率;2)decoder输入采样减少训练和预测偏差,以一定概率决定是否采样前一时刻预测输出作为输入;3)Focal Loss,缓解字符类别之间的数据不均衡问题;实验结果表明,三者均可以对模型效果带来提升,相比于speechTransformer提升幅度在10.8%~26.1%;相比于TDNN-LSTM混合系统提升12.2%~19.1%
环境:python3/pytorch>=0.4.1/kaldi
模型参数:
- 特征维度80,帧率100/3=33.3hz
- 6*encoder+6*decoder;
- dmodel=512;
- head nums=8;
- feed-forward network hidden size=2048;
- decoder embedding=512;
训练参数:
- 数据集:aishell train/dev/test
- epoch=30
- batch size=32
- 学习率:可调缩放因子k=1,学习率线性上升迭代次数warmup_steps=4000
- 优化方法:adam,β1 = 0.9, β2 = 0.98, ε = 10−9
- beam search解码:beam width=1
实验效果:aishell1 test cer:12.8%
Reference:

