

语音识别算法阅读之speechTransformer
论文:
SPEECH-TRANSFORMER: A NO-RECURRENCE SEQUENCE-TO-SEQUENCE MODELFOR SPEECH RECOGNITION
思路:
1)整体采用seq2seq的encoder和decoder架构;
2)借助transformer对文本位置信息进行学习;
3)相对于RNN,transformer可并行化训练,加速了训练过程;
4)论文提出了2D-attention结构,能够对时域和频域两个维度进行建模,使得attention结构能更好的捕获时域和空间域信息
模型:
speech-transformer 整体采用encoder和decoder结构,其中encoder和decoder的主要模块都是multi-head attention和feed-forward network;此外,encoder为更好的对时域和空域不变性建模,还额外添加了conv结构和2D-attention
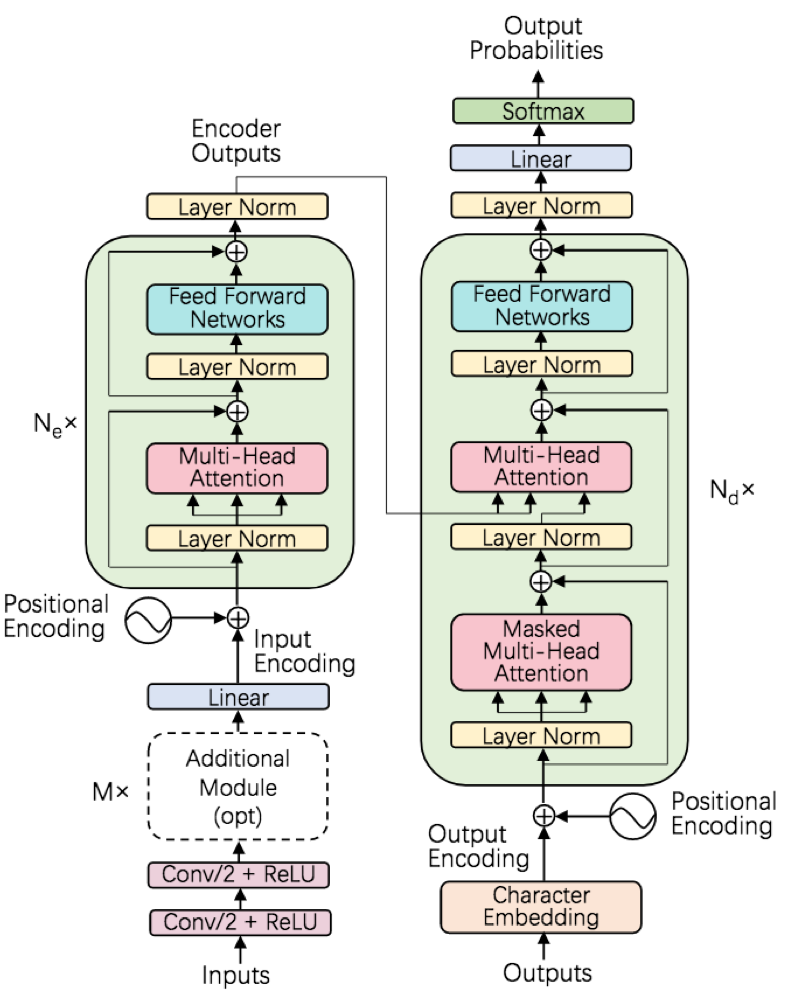
- conv:encoder采用了两层3*3,stride=2的conv,对时域和频域进行卷积,一方面提升模型学习时域信息能力;另一方面缩减时间片维度至跟目标输出长度相近,节约计算和缓解特征序列和目标序列长度长度不匹配问题;conv的激活为ReLU
- multi-head attention: encoder和decoder都采用了多层multi-head attention来获取区分性更强的隐层表达(不同的head采用的变换不同,最后将不同变换后输出进行拼接,思想有点类似于模型融合);multi-head attention结构由多个并行的scaled dot-product attention组成,在训练时可并行计算
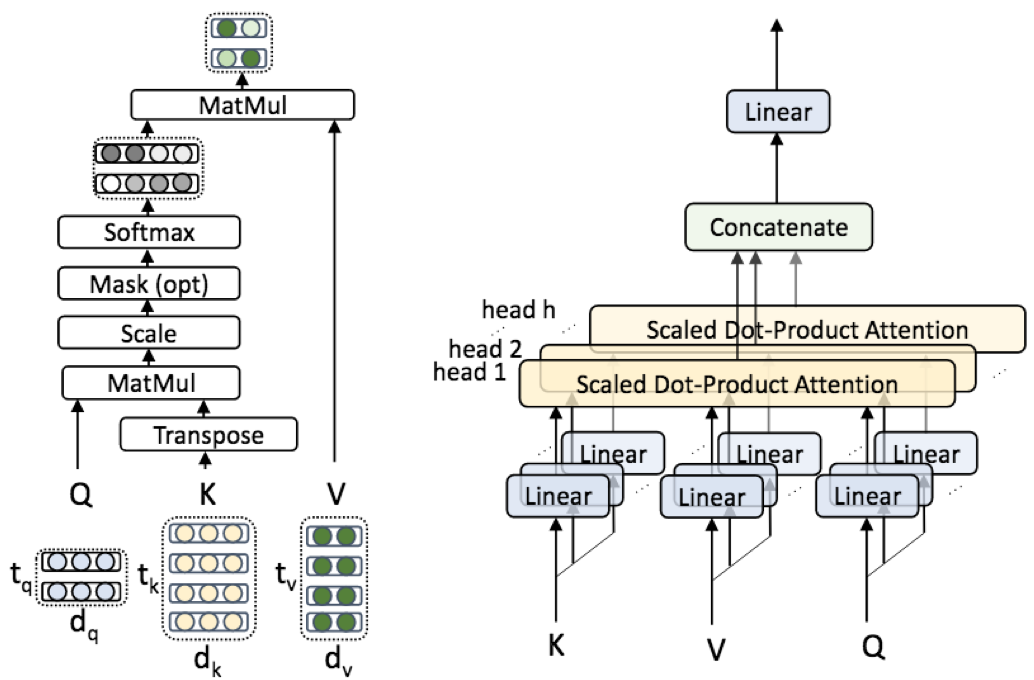
- scaled dot-product attention:结构有三个输入Q1(tq*dq),K1(tk*dk),V1(tv*dv);输出维度为tq*dv;基本思想类似于attention的注意力机制,Q跟K的运算softmax(QKT)可以看作是计算相应的权重因子,用来衡量V中各个维度特征的重要性;缩放因子√dk的作用在论文中提到是为了缓解当dk过大时带来的softmax剃度过小问题;mask分为padding mask和掩蔽mask,前者主要是用于解决padding后的序列中0造成的影响,后者主要是解码阶段不能看到未来的文本信息
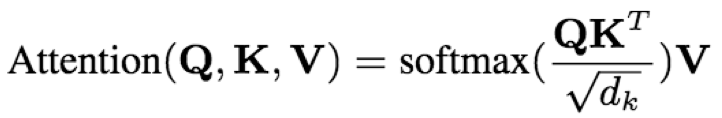
√dk的解释在[1]中为:

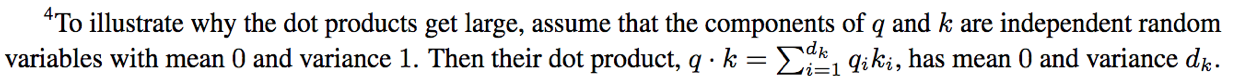
- multi-head attention:结构有三个输入Q0(tq*dmodel)、K0(tk*dmodel)、V0(tv*dmodel),分别经过h次不同的线性变换(WQi(dmodel*dq)、WKi(dmodel*dk)、WVi(dmodel*dv),i=1,2,3...,h),输入到h个分支scaled dot-product attention,各个分支的输出维度为tq*dv(dv=dmodel/h),这样经过concat后维度变成tq*hdv,再经过最后的线性层WO(hdv*dmodel)之后就得到了最终的tq*dmodel

注意这里的Q、K、V与scaled dot-product attention不等价,所以我这里用Q0、K0、V0以作区分
- feed-forward network:前馈网络包含一个全连接层和一个线性层,全连接层激活为ReLU

其中W1(dmodel*dff),W2(dff*dmodel),b1(dff),b2(dmodel)
- Positional Encoding:因为transformer中不包含RNN和conv,所以其对序列的位置信息相对不敏感,于是在输入时引入与输入编码相同维度的位置编码,增强序列的相对位置和绝对位置信息。
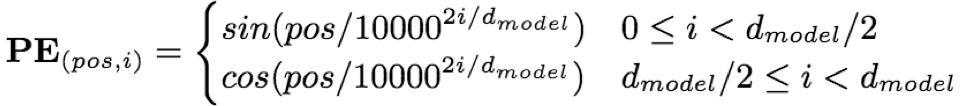
其中,pos代表序列位置,i表示特征的第i个维度,PE(pos,i)一方面可以衡量位置pos的绝对位置信息,另一方面因为 sin(a+b)=sina*cosb+cosa*sinb、cos(a+b)=sina*cosb+cosa*sinb,所以对于位置p的相对位置k,PE(pos+k)可以表示PEpos的线性变换;这样同时引入了序列的绝对和相对位置信息。
- resnet-block:论文中引入了resnet中的跳跃连接,将底层的输入不经过网络直接传递到上层,减缓信息的流失和提升训练稳定性
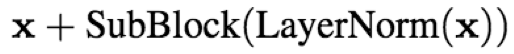
- Layer Norm:论文采用LN,对每一层的神经元输入进行归一化,加速训练
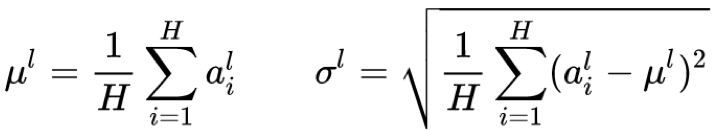
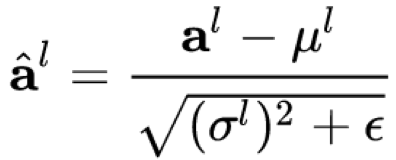


其中,l为网络的第l层,H为第l层的神经元节点数,g,b分别为学习参数,使得特征变换成归一化前的特性,f为激活函数,h为输出。
- 2D-attention:transformer中的attention结构仅仅针对时域的位置相关性进行建模,但是人类在预测发音时同时依赖时域和频域变化,所以作者在此基础上提出了2D-attention结构,即对时域和频域的位置相关性均进行建模,有利于增强模型对时域和频域的不变性。
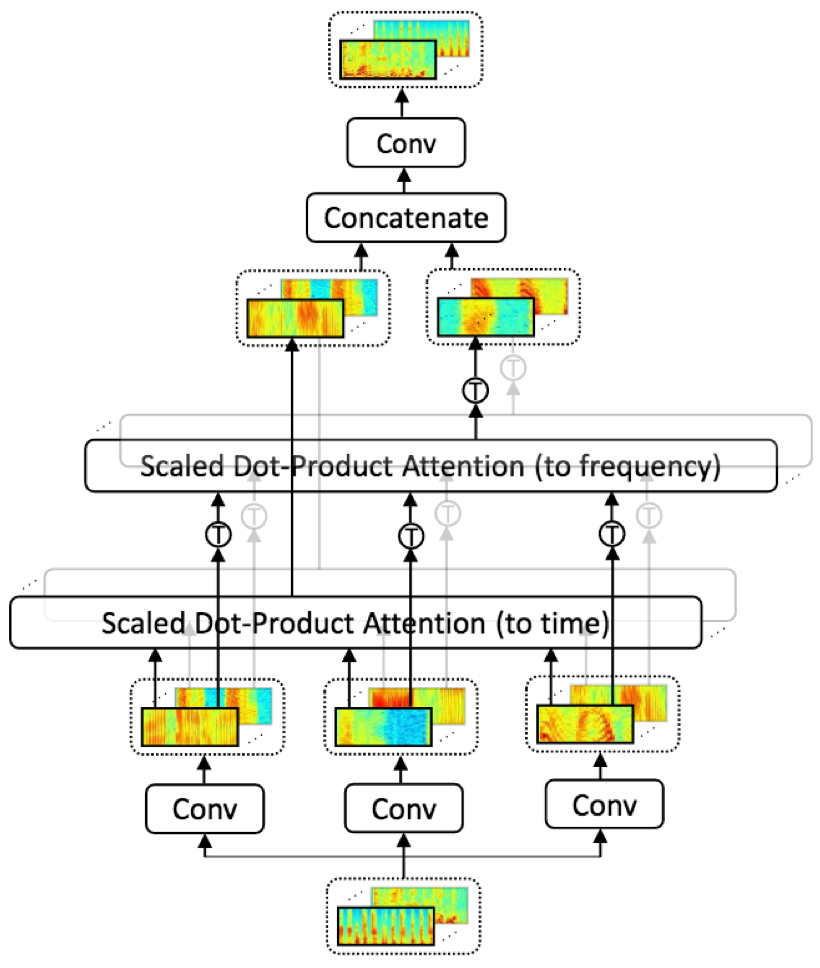
- 输入:c通道的输入I
- 卷积层:三个卷积层分别作用域I,获得相应的Q、K、V,滤波器分别为WQi、WKi、WVi(i=1,2,3...,c)
- 两个multi-head scaled dot-product attention分别对时域和频域进行建模,获取相应的时间和频域依赖,head数为c
- 对时域和频域的attention输出进行concat,得到2c通道的输出,并输入到卷积中得到n通道的输出

其中Wo为最后一层卷积,t为时间轴,f为频率轴
训练:
- 数据集:WSJ(Wall Street Journal),train si284/dev dev93/ test dev92
- 输入特征:80维fbank
- 输出单元:输出单元数为31,包含26个小写字母以及撇号,句点,空格,噪声和序列结束标记
- GPU型号:NVIDIA K80 GPU 100steps
- 优化方法和学习率:Adam
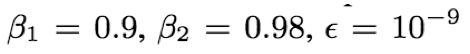
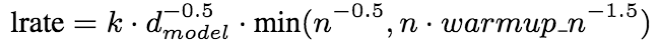
其中,n为steps数,k为缩放因子,warmupn= 25000,k= 10
- 训练时,在每一个resnet-block和attention中添加dropout(丢弃率为0.1);其中,resnet-block的dropout在残差添加之前;attention的dropout在每个softmax激活之前
- 所有用到的conv的输出通道数固定为64,且添加BN加速训练过程
- 训练之后,对最后得到的10个模型进行平均,得到最终模型
- 解码时采用beam width=10 beam search,此外length归一化的权重因子为1
实验:
在实验中dmodel固定为256,head数固定为4
- encoder的深度相比于decoder深度更有利于模型效果

- 论文提出的2D-attention相比于ResCNN, ResCNNLSTM效果更好;表现2D-attention可以更好的对时域和频域相关性进行建模
- encoder使用较多层数的resnet-block时(比如12),额外添加2D-attention对识别效果没有提升,分析原因是当encoder达到足够深度后,对声学信息的提取和表达能力以及足够,更多是无益
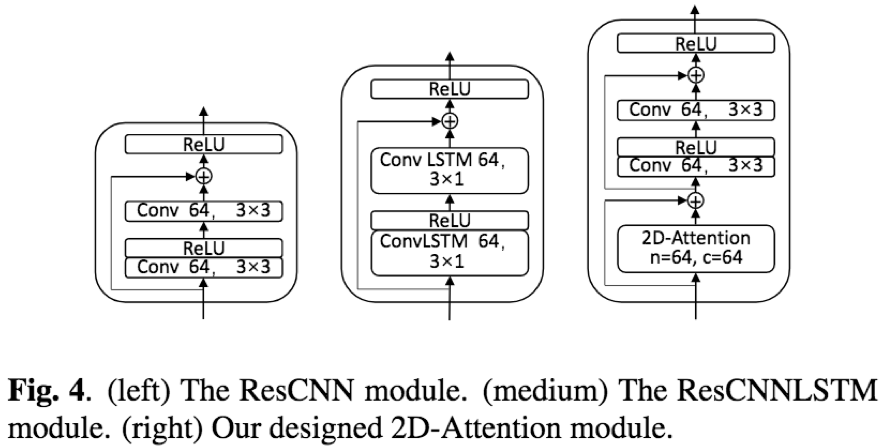
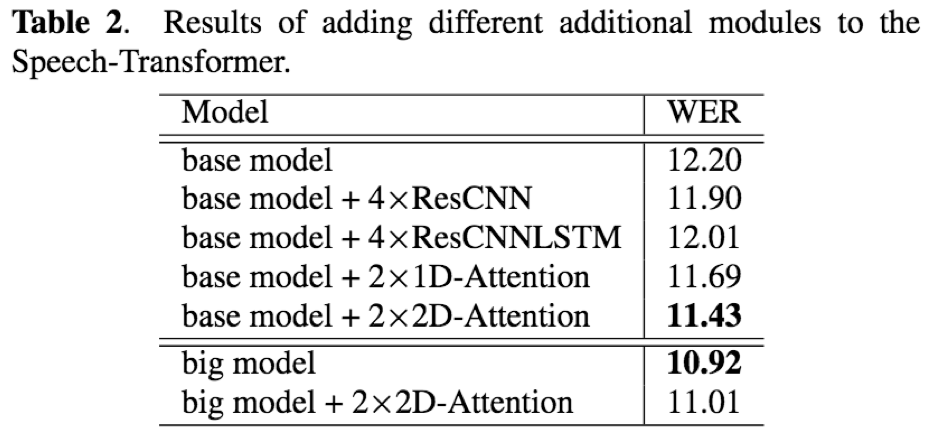
- 训练时间上,相比于seq2seq结构,在取得相似的识别效果的同时,训练速度提升4.25倍

- 环境:pytorch>=1.20;Torchaudio >= 0.3.0
- 输入特征:40fbank,CMVN=False
- spec-augment[3]:频率掩蔽+时间掩蔽,忽略时间扭曲(复杂度大,提升不明显)
- 模型结构:
- encoder:2*conv(3*2)->1*linear+pos embedding->6*(multi-head attention(head=4, d_model=320)+ffn(1280))
- decoder:6*(multi-head attention(head=4, d_model=320)+ffn(1280))
- 语言模型:4*(multi-head attention(head=4, d_model=320)+ffn(1280))
- 训练:
- 优化算法:adam
- 学习率策略:stepwise=12000,学习率在前warmup_n迭代步数线性上升,在n_step^(-0.5)迭代次数时停止下降
- clip_grad=5
- label smoothing[4]:平滑参数0.1
- batch=16
- epoch=80
- 解码:beam search(beam width=5)+长度惩罚(权重因子=0.6)
- 实验效果:aishell test cer:6.7%
Reference:
[1] Attention Is All You Need https://arxiv.org/pdf/1706.03762.pdf
[2] SPEECH-TRANSFORMER: A NO-RECURRENCE SEQUENCE-TO-SEQUENCE MODEL FOR SPEECH RECOGNITION http://150.162.46.34:8080/icassp2018/ICASSP18_USB/pdfs/0005884.pdf

