语音识别算法阅读之pFSMN
论文:
A NOVEL PYRAMIDAL-FSMN ARCHITECTURE WITH LATTICE-FREE MMI FOR SPEECH RECOGNITION
思想:
本文在DFSMN的基础上做了如下改进:
1)DFSMN中的序列记忆模块之间是逐层连接的,即第l层的序列记忆模块需要作为第l+1层序列记忆模块的部分输入,但是这样在向上层模块传播时,低层相邻时刻之间会造成信息冗余;所以本文采用跨层skip-connection,即第l层的序列记忆模块与第l+m层序列记忆模块的连接,作为其部分输入,这样的好处是低层提取音素级的特征,而高层视野更宽,时序更长,能够提取到语义、语法层级的特征;
2)pFSMN结构之前引入CNN结构,CNN结构包含多层2D conv层和降采样层,并且采用residual结构来保证信息稳定传递;CNN结构一方面能够对频域特征进行建模,另外也可以降低特征序列长度,有助于节约计算;
3)本文网络结构采用LF-MMI+CE的联合训练模式,相比于FSMN、DFSMN帧级别训练模式,模型更加鲁棒,效果更好;
4)采用TDNN-LSTM LM rescore策略,能够带来额外的识别效果提升
模型:
声学模型训练采用的是CNN+pFSMN+Linear layer+(LF-MMI+𝛼CE)框架;语言模型采用TDNN+LSTM框架
- 声学模型
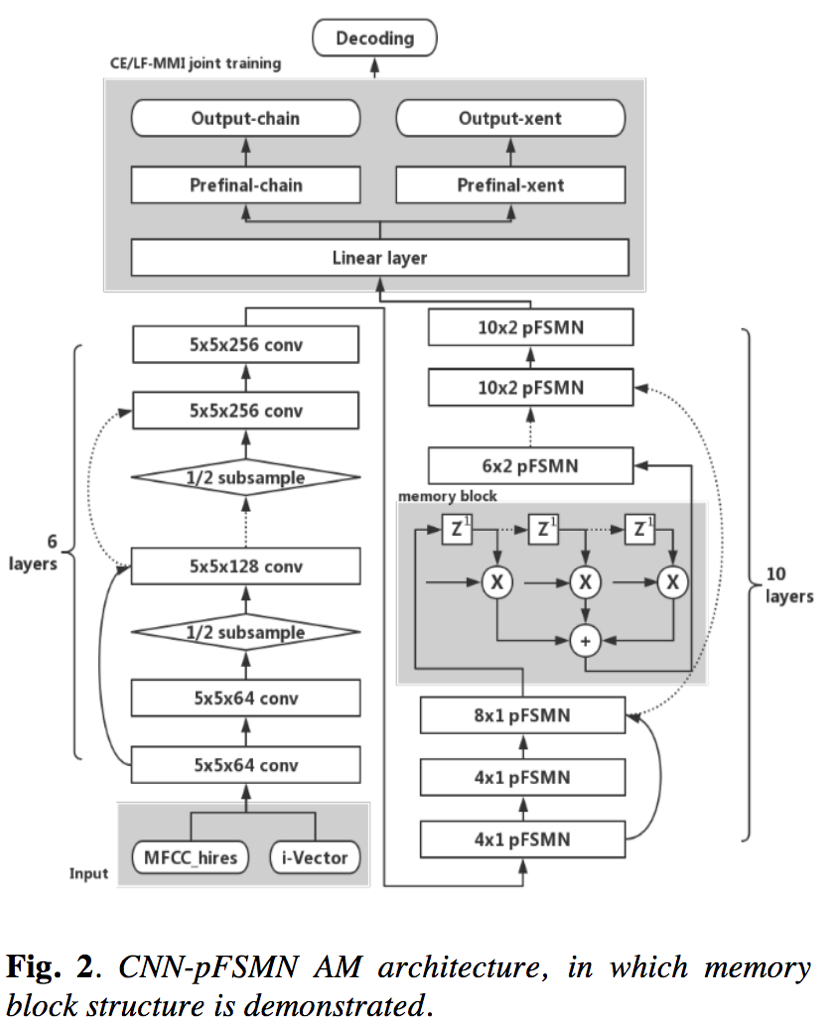
- CNN:声学模型的前端采用CNN结构,包含conv和下采样层(池化层),一方面可以对频域特征进行建模,另一方面也可以缩短特征序列长度,节约计算;
- pFSMN:pFSMN是对DFSMN结构的优化和改进,即相对于DFSMN,序列记忆模块之间采用跨层连接的模式,减少冗余信息的向上传播;这样,低层利用的时序信息较少,用于提取音素层级的特征,上层利用的时序信息更多,用于提取语义和语法层级别的特征;
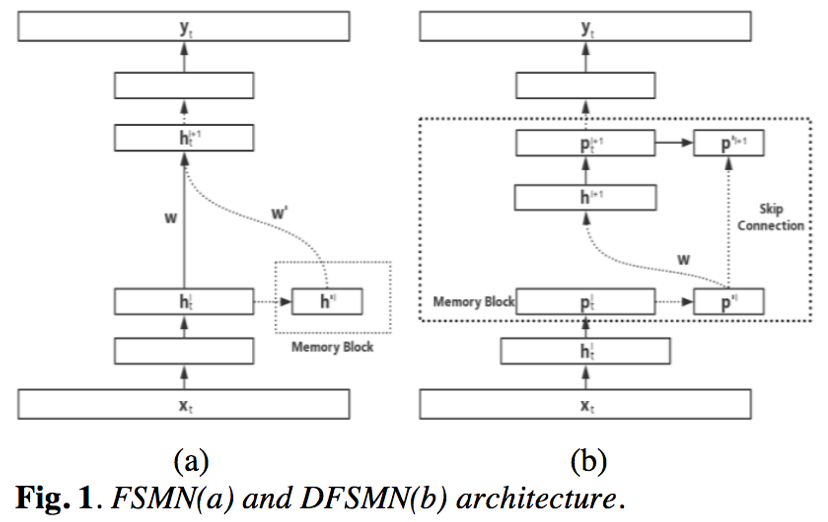
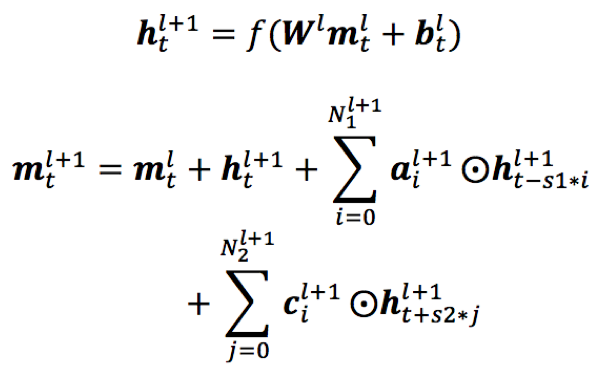
DFSMN
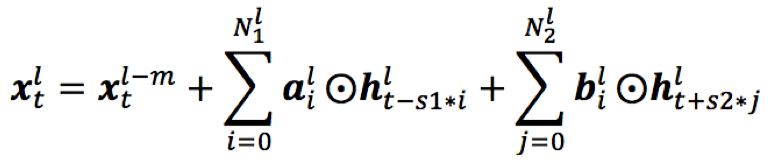
pFSMN(m为skip层数)
- LF-MMI+CE joint traing:
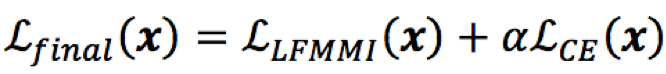
其中,𝛼为CE的权重因子
1)MMI:MMI是序列级目标函数最大互信息,该目标的终旨是最大化正确序列概率的同时最小化错误序列的概率;
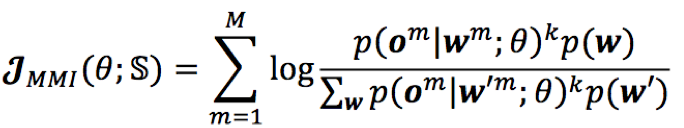
其中,om,wm分别为第m个样本对应的观测序列和文本序列
2)CE:帧级别的交叉熵目标函数可以发挥正则化的作用,提升模型鲁棒性;
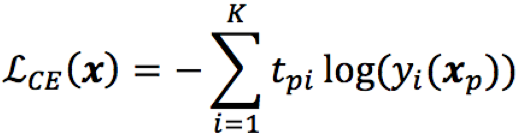
3)LF:lattice free,lattice用在代替MMI的分母部分全路径计算,因为分母中的路径绝大部分概率很小,几乎不会实现,所以可以采用交叉熵预训练的模型解码生成的lattice代替全路径,节省大量计算;但是lattice本身在区分性开始前完成,并且不随着区分性训练而更新,这使得声学模型跟lattice之间存在不同步的问题;lattice free模式采用基于phone的n-gram构建的CLG代替lattice,取得了与后者相当的效果,并且计算更快。
- 语言模型:语言模型采用TDNN-LSTM架构,TDNN层和LSTM层交替出现,每层TDNN层以当前帧和一些历史帧对应的特征进行concat作为LSTM层的输入;模型的输入为初始解码获得的N-best序列
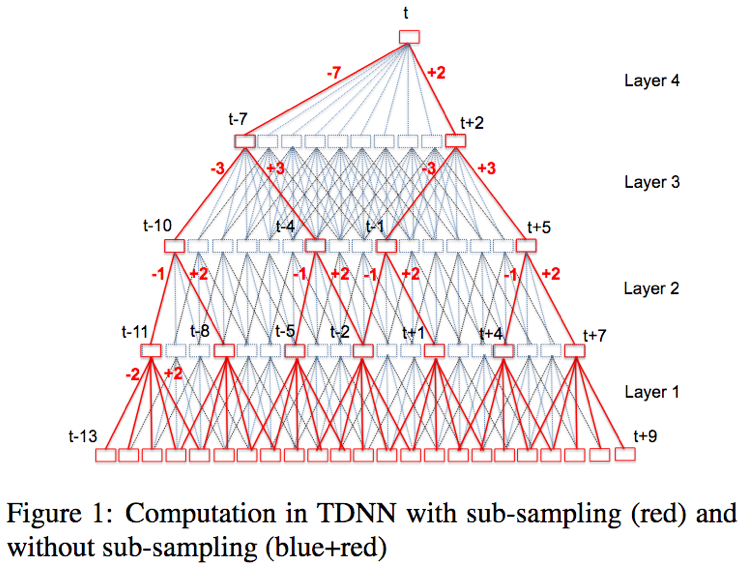
- TDNN[1]:TDNN是一种前馈网络结构,只不过其每层的输入由当前帧和若干历史和未来的帧组合而成;这种结构一方面可以利用历史和未来的时序信息,另一方面保持训练稳定性,且可并行化处理;
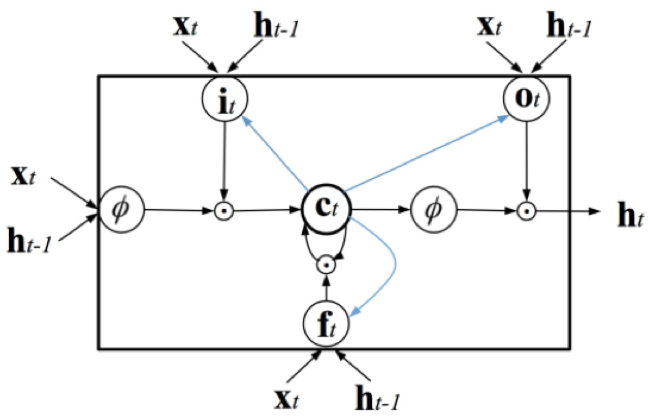
- LSTM:LSTM是一种循环结构,其内部由三个门函数来控制信息的流入和流出,能够在一定程度上缓解长时依赖的问题;
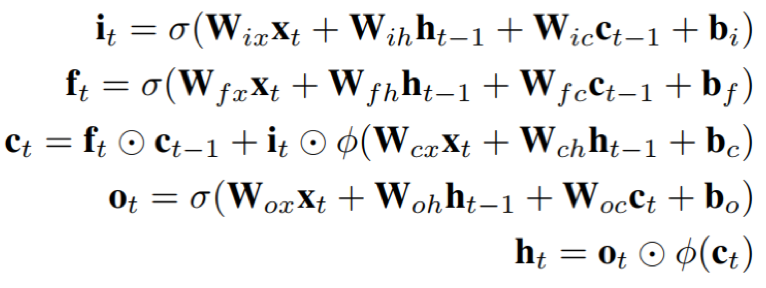
训练:
- 声学数据集:300小时 Switchboard corpus(SWBD-300)和 1000 小时 Librispeech corpus;测试集:test-clean, test-other, dev-clean,dev-otherand train-dev五个
- 数据增强:速度增强0.9x/1.0x/1.1x
- 语言模型数据集:14500 books texts for Librispeech task and with Fisher+Switchboard texts for SWBD-300task
- 输入特征:40mfccs+100i-vectors;
- 强制对齐:GMM-HMM
- 网络结构:
- 声学模型:CNN(6*conv(5*5)+2*subsample)+10pFSMN(hidden layer(1536)+linear layer(256)+sum layer(256),历史和未来时间片长度4~20,stride 1~2)
- 语言模型:5*TDNN-LSTM(TDNN(1024)+LSTM(1024))
实验:
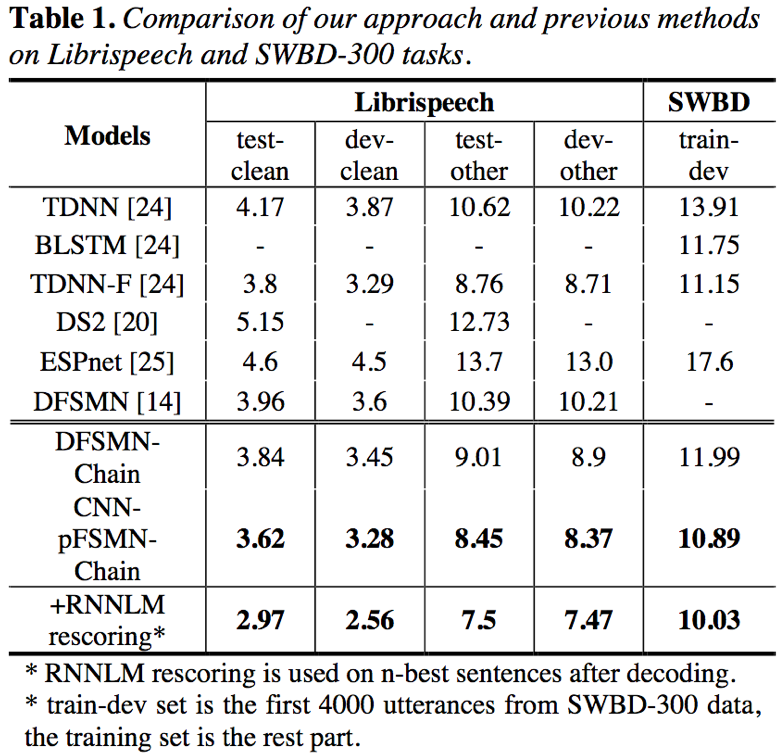
- pFSMN在两个数据集上均取得了比其他模型更好的识别结果;此外,通过TDNN-LSTM LM rescore还可以额外提升一定的效果,但是相应也会增加解码耗时
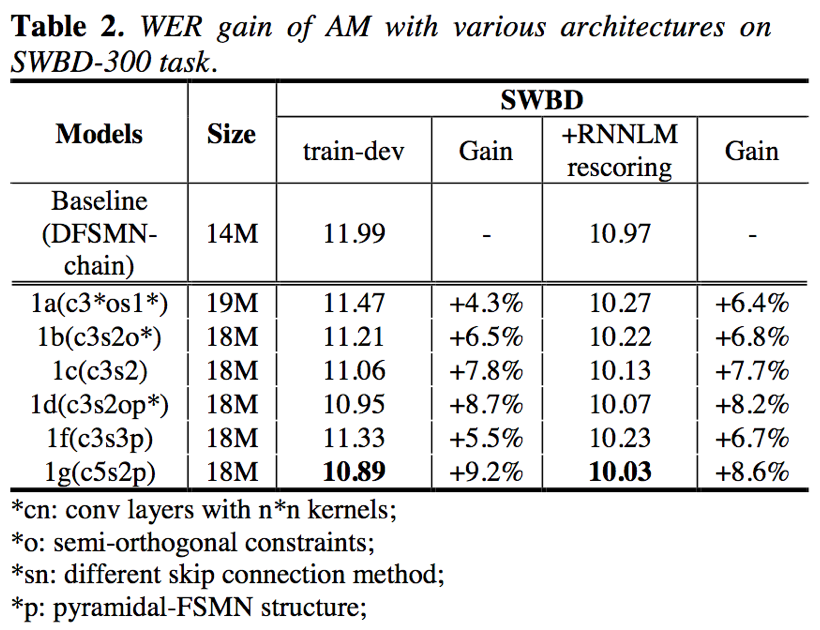
- 实验证明,CNN的结构中5*5的卷积效果要比3*3卷积好;此外,还证明了pFSMN结构的有效性;
结论:
本文提出了一种CNN-pFSMN结构;其中res-CNN对频域特征进行建模和缩短特征序列长度;pFSMN采样金字塔形的skip-connection使得低层利用相对较少的信息,提取音素级特征,深层利用更大视野的信息提取语义和语法特征;LF-MMI+CE中,MMI对模型进行区分性训练,CE对模型训练进行正则化;最后 TDNN-LSTM LM rescore对解码结果进一步提升;以上tricks使得模型在 Switchboard corpus(SWBD-300)和 Librispeech corpus两个数据集上取得了最好的识别结果
References:
