

语音识别算法阅读之sFSMN-vFSMN
论文:

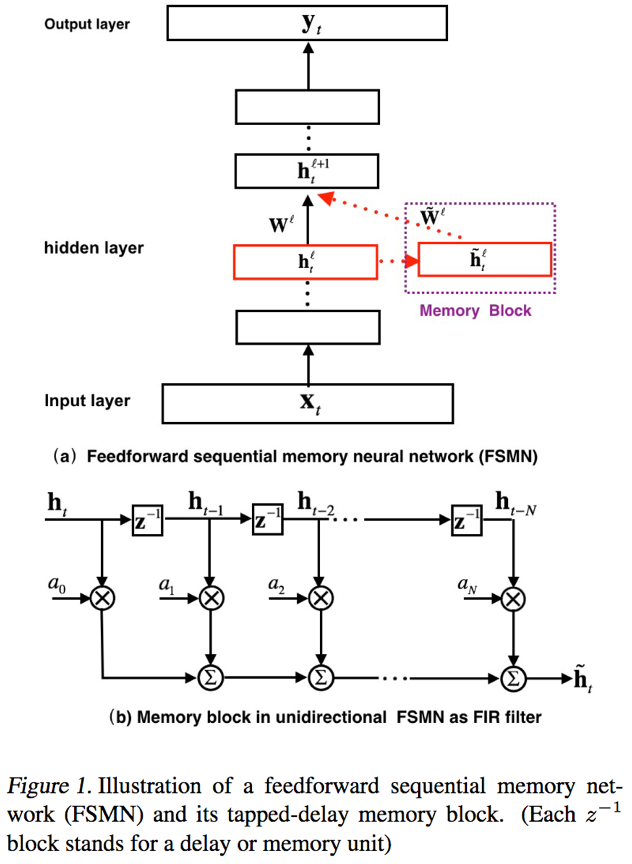
- sFSMN/vFSMN:sFSMN的编码系数为一个常数,也可以看做是一个与隐层编码等长且每个维度数值相同的常数向量;而vFSMN的编码系数采用向量化的系数,其每个维度数值不同,可以看做多个不同的维度滤波器组合而成,从而提升建模能力。假设t时刻l层的隐层输出为h(t,l),那么相应的sFSMN和vFSMN的计算公式分别为:
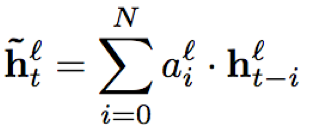
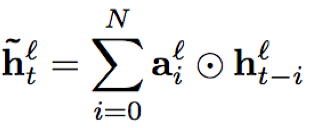
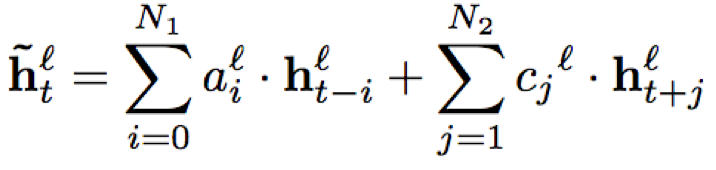
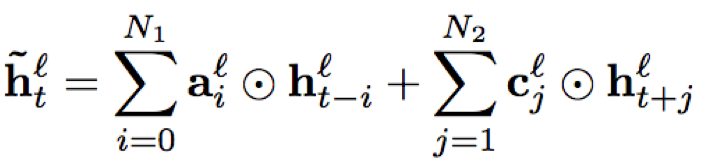
N1,N2分别表示历史和未来的时间片个数

- attention-based的FSMN:sFSMN和vFSMN都是与上下文时序信息无关的编码系数;因此,论文提出了一种与上下文相关的attention-based的FSMN结构,该结构可以自主学习当前时间片与每个上下文时间片的相关性程度,从而更好的对当前时刻进行建模和预测;不过从实际效果来看,attention-based的FSMN不如vFSMN结构
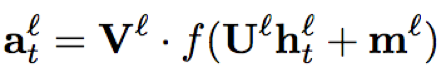
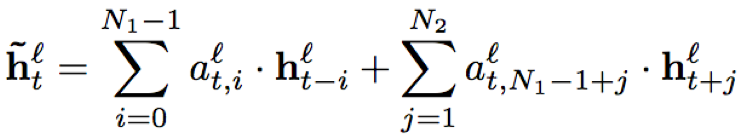
- GPU计算加速:因为FSMN采用前馈结构,其计算可以转化为矩阵乘法运算,通过GPU进行加速;对于上下文宽度为N的单向记忆模块和N1,N2的双向记忆模块,可以表示为T*T的矩阵:
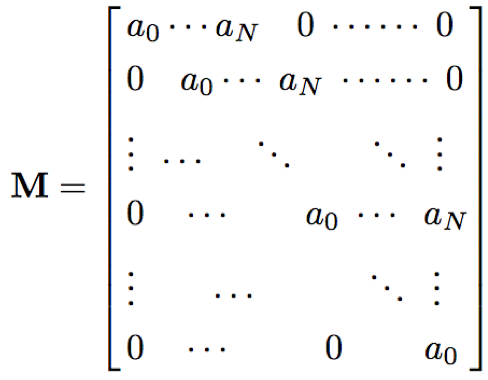

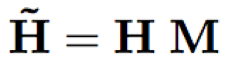
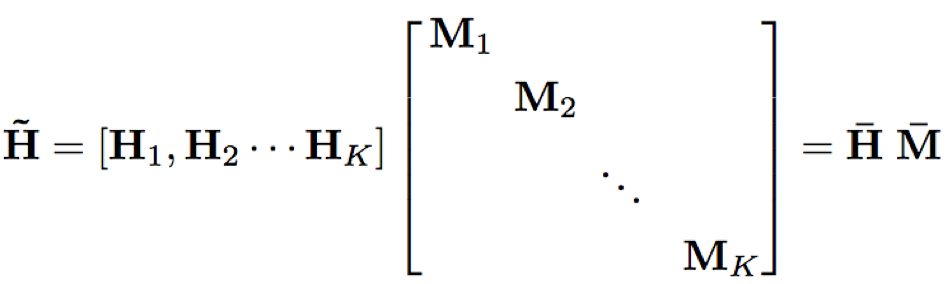
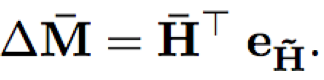

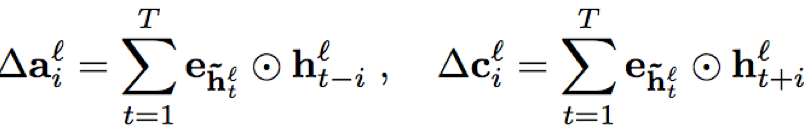
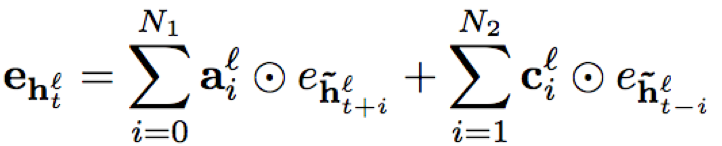
- 语音识别基线系统:
- 数据集:Switch-board (SWB),309小时Switchboard-I和20小时Call Home;99.5%train 0.5%dev;测试集:Hub5e00 1831utts
- GMM-HMMs
39维PLPs+CMVN
HMM包含8991个建模状态(三音素),每个状态40个高斯成分
训练:先MLE(最大似然估计)训练,然后MPE(最小音素错误)准则序列化训练
解码时采用3-gram LM
- DNN-HMMs[1]
123维log fbank,输入由上下文语音帧拼接而成(5+1+5)
6个隐层,每个隐层结点数2048,隐层激活函数为sigmoid或ReLU
训练由GMM-HMMs提供对齐,sigmoid DNN(DNN-1)采用RBM(玻尔兹曼机)预训练,ReLU DNN(DNN-2)采用随机初始化,然后统一采用交叉熵训练
- LSTMP-HMM[2]
123维fbank
3*LSTMP(2048-512)
训练策略采用截断的BPTT
- BLSTMP-HMM
123维fbank
3*BLSTMP(1024forward+1024backword,512)
训练策略采用截断的BPTT
- FSMN
sFSMN/vFSMN
123fbank,输入的上下文窗口为(1+1+1)
6*full_connected layer(2048,ReLU激活)
attention-based FSMN
39PLPs
6*full_connected layer(2048,ReLU激活)
历史和未来时间片长度均为40
- 语言模型基线系统:
- 数据集:PTB;English wiki9
- PTB:
词汇表大小为10k,其余词汇映射为<UNK>
LSTM-LM[3]:1*LSTM
LSTM-LM:2*LSTM
s/vFSMN:1* linear layer(200)+2*hidden layer(400)+ 第一个hidden layer连接单向记忆模块(历史时间片个数N=20)
训练策略:SGD;mini-batch 200;初始学习率0.4;当dev的困惑度p降低为1时,继续训练6个epoch,每一个epoch的学习率降为上一个epoch 的1/2;momentum (0.9) /weight decay (0.00004)
- wiki9
词汇表大小为80k,其余词汇映射为<UNK>
n-gram:3-gram/5-gram,modified Kneser-Ney smoothing
RNN-LMs,1*LSTM(600)
FNN-LM/FOFE-LM[4]:1*linear layer(200)+3*hidden layer(600,ReLU);FNN_LM输入为one-hot特征,FOFE-LM输入为FOFE code特征
FSMN-LM:1*linear layer(200)+3*hidden layer(600,ReLU);单向记忆模块历史时间片个数N=20
训练策略:SGD;mini-batch 500;初始学习率0.4;当dev的困惑度p降低为1时,继续训练6个epoch,每一个epoch的学习率降为上一个epoch 的1/2;无momentum/weight decay机制
- 语音识别任务中,vFSMN取得了最好的识别结果;BLSTM结构的效果要好于sFSMN结构;同时FSMN结构要比BLSTM结构训练速度快3倍以上;

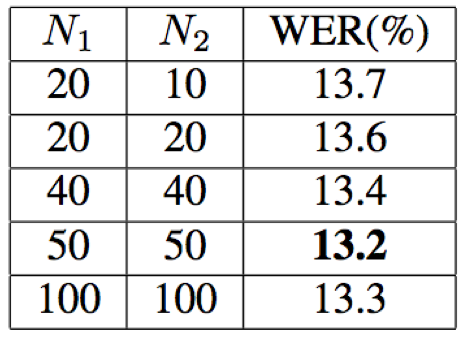
- 对于双向FSMN,当N1=50,N2=50时,取得了最好的识别结果;从结果来看,并不是N1,N2越大识别效果越好,这表明当前帧仅仅只与有限范围内的上下文时序信息相关,更远范围内的时序信息对识别无用;此外,当设置未来时间片长度N2=10时,WER并没有损失太多,利用这一点可以有效的节约计算和降低输出延迟
- 在本文实验中,attention-based FSMN相对于vFSMN而言,并没有带来识别效果的提升,反而有所下降(FACC,帧分类精度)

- 无论在PTB还是在wiki9数据集上,相比于n-gram、RNN-LM、LSTM-LM、FOFE-LM,sFSMN和vFSMN的语言模型困惑度均最小,这证明了FSMN在语言模型方面的有效性;
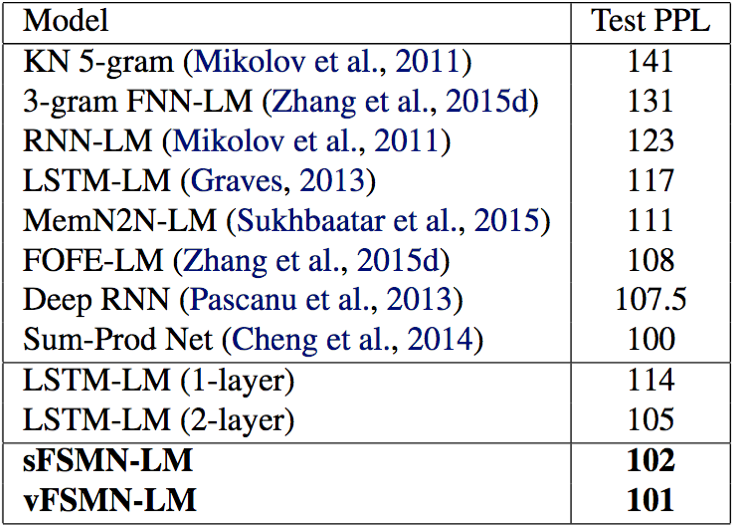
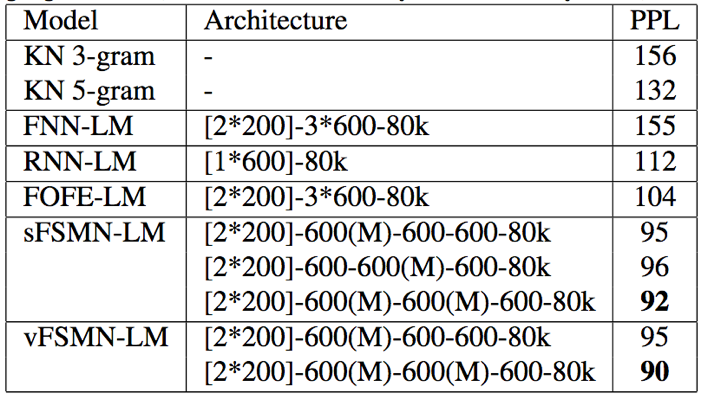
- 在语言模型方面,vFSMN跟sFSMN效果几乎相当,并没有语音识别领域那样的优势;论文作者通过可视化vFSMN的编码系数发现,其每个维度的系数大小非常相近,几乎等价于sFSMN;并且vFSMN和sFSMN的平均编码系数也非常相近,这间接证明了vFSMN跟sFSMN效果相当的原因

- 隐层包含序列记忆模块,该模块能够对上下文时序依赖信息进行建模;并且上下文时序宽度可以控制,从而节约计算和降低延迟;实验结果表明,FSMN相比于主流的BLSTM能够更好的对时序进行建模
- 此外,FSMN是一种纯粹的前馈网络结构,支持并行化的矩阵运算,相比于BLSTM结构能够明显降低训练时间

