

语音识别算法阅读之LAS
LAS:
listen, attented and spell,Google
思想:
sequence to sequence的思想,模型分为encoder和decoder两部分,首先将任意长的输入序列通过encoder转化为定长的特征表达,然后输入到decoder再转化为任意长的输出序列;相比于传统sequence to sequence在decoder部分引入attention机制,让模型自学习特征相关性,有助于提升识别效果,对静音和噪声具有较好鲁棒性

其中,输入序列x=(x1,x2,x3,....xT),每个时间片声学特征为40维logfbank; 隐层状态h=(h1,h2,h3,....,hU),U<T; 输出序列y=(<sos>,y1,y2,y3,....,yS,<eos>),<sos>和<eos>分别代表起始和结束符号
模型:
- encoder采用1 BLSTM(512)+3 pBLSTM(512)的金字塔状结构,能够将原始时间片减少到1/8,从而剔除冗余信息,加速decoder部分训练;

其中, i为第i个时间片,j为第j个隐层;
- decoder采用两层的单向LSTM(521)结构,且引入attention机制


其中,Φ和ψ表示MLP网络

- 目标函数:最大化每个时间片的log概率
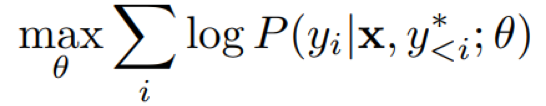

- 解码:beam width=32的beam search+n-gram Rescore

其中,|y|c为字符长度,实验中λ=0.008
细节:
- pBLSTM结构能够有效解决模型收敛缓慢和识别效果较差的问题,这种金字塔结构可以减少上层隐层的输出时间片个数,从而剔除冗余信息,加速deocder训练
- LSTM结构相比传统RNN,能够有效缓解梯度弥散,网络采用均匀分布进行初始化u(-0.1~0.1)
- attention机制能够自学习特征相关性,一定程度上屏蔽干扰信息,比如静音、噪声等
- decoder部分在训练时,如果采用当前时间片的输入为上一时刻的标签这种模式;那么在测试时,模型因为无法利用groundtruch信息而影响识别结果;论文在训练中采用10%的概率采用上一时刻的预测输出作为当前时刻的输入,从而缓解训练和测试的差异性
- 解码时采用beam search+LM Rescore形式,能够带来5%的提升效果
- 解码时,每一时刻的输出概率进行归一化处理,缓解模型偏向较短的路径
- 论文还证明了,相比于CTC结构,网络结构具有学习隐式语言模型的能力,比如“triple a”和“aaa”
- 数据部分采用2000小时的Google voice search utterances,抽取10小时dev set和16小时test set;此外,采用混响和噪声增强使的数据量扩大了20倍
效果:
- 模型在最优的情况下取得了clean 10.3%和noise 12.0%的WER
- LM Rescore带来了5%的效果提升
- decoder训练时采用sample方式将上一时刻预测输出作为当前时刻输入,带来了2%的提升

- google state-of-the-art模型CLDNN clean 8.0%和noise 8.9%;论文分析原因在于CLDNN中采用了CNN的前置结构,CNN作为浅层特征提取器,能够增强频域不变形,为LSTM提供更强大的特征表达
- 作者对LAS进行了基于pytorch的代码实现,并使用kaldi做数据准备、特征提取和cmvn;并在aishell1上进行了训练
- 实现中,模型的输入是240维fbank特征
- 模型的encoder部分采用3层BLSTM结构,结点数为256,采用droput=0.2
- deocder采用1层LSTM,结点数512
- attention结构中,MLP网络采用两层线性层,第一层线性层输出维度512,激活函数tanh,第二层线性层输出维度为字典个数4203,MLP输出后接softmax
- 解码部分采用beam width=30的beam search算法得到最终的最优解码,未使用额外的LM
- 优化函数adam
- aishell1 test cer: 13.2%

Reference:
[1] https://arxiv.org/pdf/1508.01211.pdf

