

语音识别模型阅读之CLDNN
论文:
CLDNN: CONVOLUTIONAL, LONG SHORT-TERM MEMORY,FULLY CONNECTED DEEP NEURAL NETWORKS,Google
思想: CNN、LSTM和DNN进行整合,发挥各个部分的建模能力;
1)CNN:学习频域不变形能力;
2)LSTM:时序建模能力;
3)DNN:将特征转化到易于分离的空间,即类别区分能力;
模型:
- 输入: [xt−l, . . . , xt+r],对每一帧xt,采用l+cur+r的窗形式作为当前帧输入,xt采用40维logfbank
- CNNs:频域建模;2层conv;
- 第一层conv采用9*9大小kernel size对频域*时域进行卷积;输出通道256
- max pooling,pooling时不重叠,pooling size=3;
- 第二层conv采用4*3大小kernel size;输出通道256
- linear layer:输出维度256,CNNs输出维度进行展平操作(freq*time*channels)维度较大,利用该层进行降维,节约计算且不损失精度
- LSTMs:时序建模;2层LSTMP;
- LSTM结点数均为832,映射层维度512
- 为保证实时性,LSTM延迟为5frames
- DNN:2层左右;输出维度1024
- CE准则作为目标函数
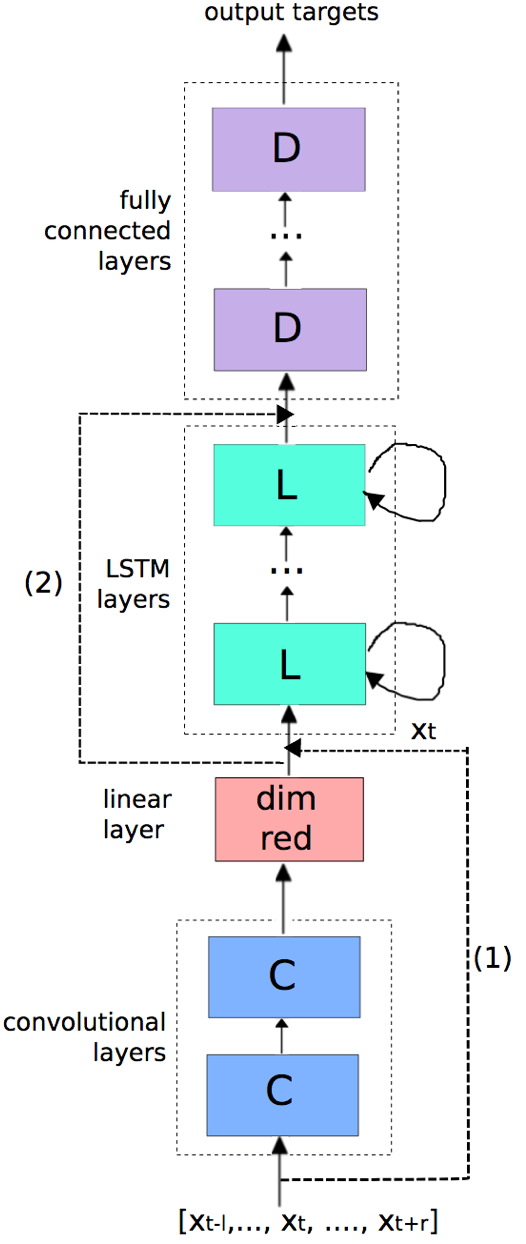
细节:
- 数据集:2000小时clean和2000小时noise(data augmentation);20小时clean text和20小时noise test
- 40维log fbank
- ASGD优化准则
- CNN、RNN初始化策略Glorot-Bengio;LSTM高斯随机初始化一个较小值
- 短时和长时特征混合输入到LSTM,xt跨越CNNs与CNNs输出连接输入到LSTMs,上图(1)
- CNNs输出跨越LSTMs输入到DNNs,上图(2)
实验结果:
- CLDNN在大数据集上取得了clean 13.1% noise 17.4结果
- 相比于纯LSTMs结构效果提升了4~6%
- xt bypass输入到LSTM,带来额外的1%提升
- CNNs输出跨越LSTMs输入到DNNs,无提升
- 序列级训练相比于CE,带来1%提升
reference:

