


声纹识别算法阅读之deep-speaker
论文:
Deep Speaker: an End-to-End Neural Speaker Embedding System
思想:
Deep Speaker是百度提出的一种端到端的说话人编码方法。该方法采样ResCNN或GRU进行帧级别的特征提取,然后时间平均层将输入序列帧级别的特征转化为句子级别的特征表达,彷射变换层将编码映射到指定维度,长度归一化层输出便于cosine相似度计算;模型预训练损失为CE,重训练损失为triplet loss
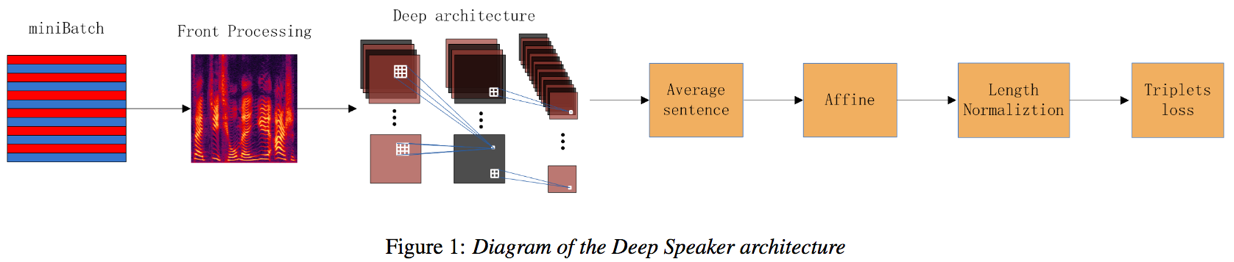
模型:
网络架构包含ResCNN或GRU、时间平均层、彷射变换层、长度归一化层,损失为triplet_loss
- ResCNN: ResCNN是一种比较流行的深度神经网络,其由多个resblock组成,每个block包含两个分支,一个分支经过若干卷积,其中最后一个卷积无激活;另一个分支不经过任何卷积;两个分支的输出进行加和操作,然后经过一个ReLU激活输出

- GRU:GRU是LSTM结构的一种优化版本,GRU相比LSTM少一个门控单元,拥有更少的参数,实验表明,在小数据集上,当GRU与LSTM参数量类似时,能够取得相近的识别结果,但是训练速度比LSTM更快。
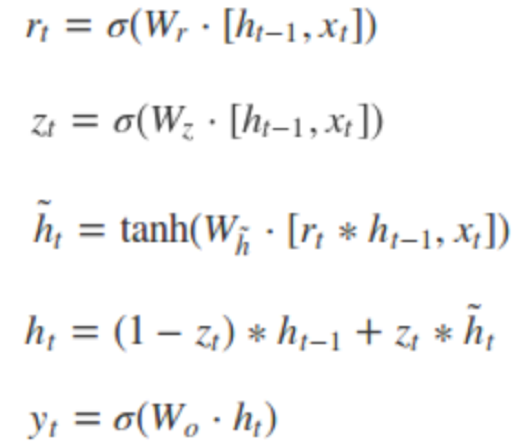
- 时间平均池化层:输入序列逐帧输入到网络中提取编码,然后对该输入序列的所有帧取平均值,得到句子级别的特征编码
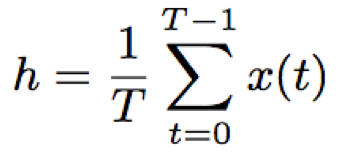
- 仿射变换层:对句子级别的特征编码进行降维
- 长度归一化:L2归一化,便于后续cosine相似度计算
- cosine相似度计算:因为已进行长度归一化,节省了cosine的分子计算
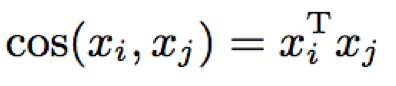
- triplet loss:三元组损失,使得正样本对之间的相似度得分逐渐增大,负样本对之间的相似度得分逐渐减小,且相比正样本对至少小α


其中,a为anchor sample,p为positive sample,n为negative sample,a为中心句子,p为与a同一说话人的另外一个句子,ap组成正样本对,n为其它说话人中选择的句子,an组成负样本对
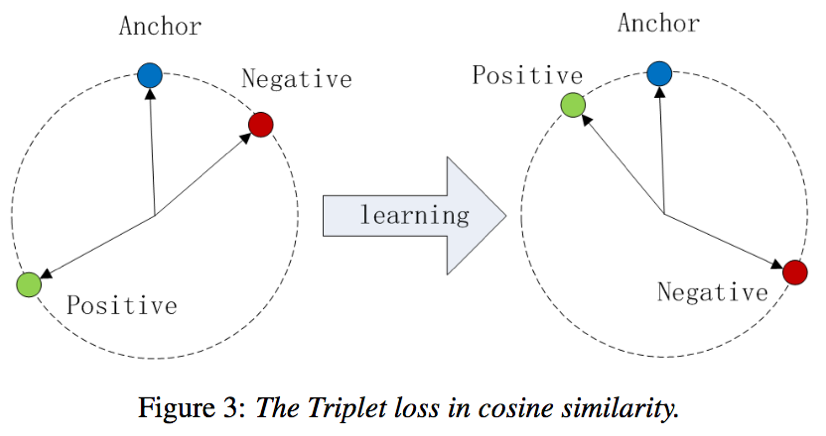
训练:
- 数据集
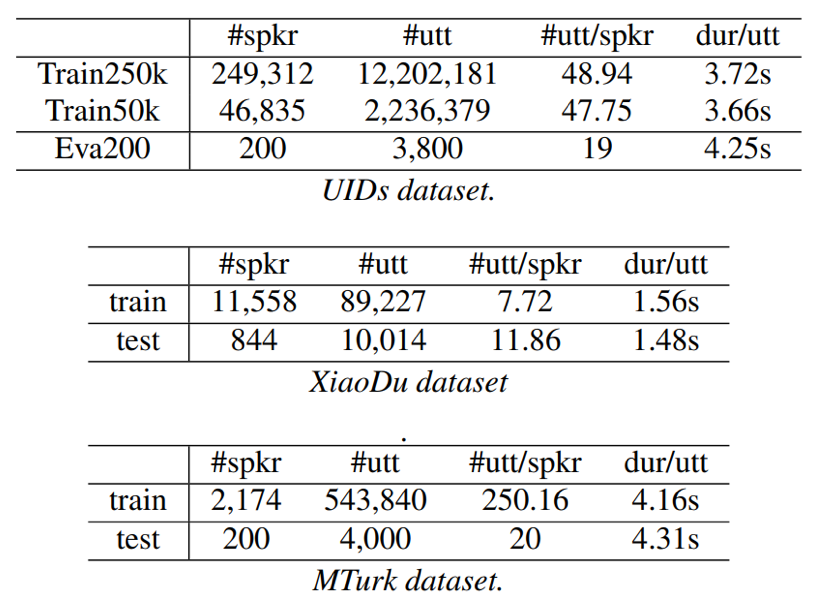
- UID
Train250k:249312 speakers 12202181 utts
Train50k:46835 speakers 2236379 utts
Eva200: 200 speakers 380000 trials
- XiaoDu:训练集:11558 speakers 89227 utts; 验证集:844 speakers 1001400 trials
- MTurk:训练集:2174 speakers 543840 utts;验证集:200 speakers 400000 trials
- trials选择:每个anchor选择一个positive样本,99个negative样本;negative样本选择策略:训练初始阶段在每个minibatch中选择,训练末段在整个batch中选择,因为随着训练的进行,hard-negative的选择越来越难
- 前置处理:VAD
- 输入特征:64fbanks,方差均值归一化CMVN
- 模型参数:
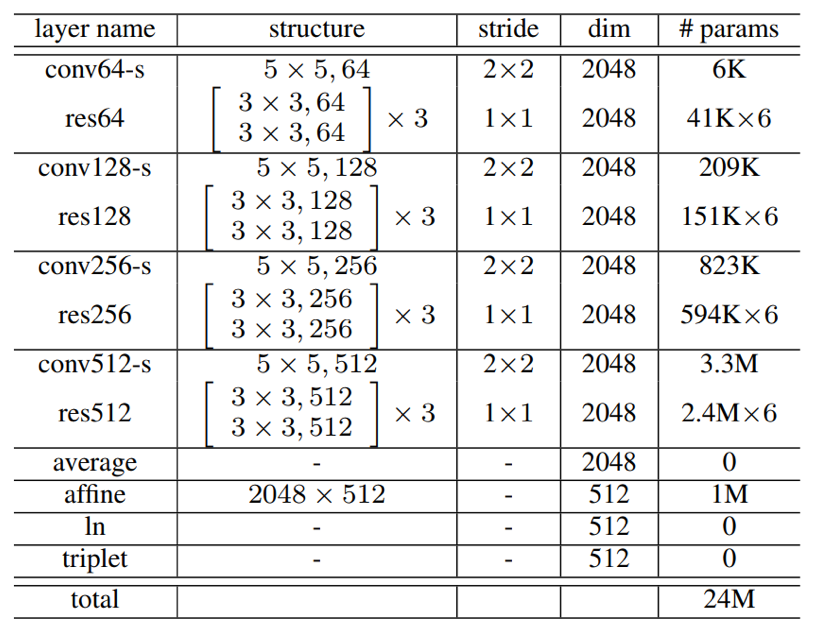
ResCNN
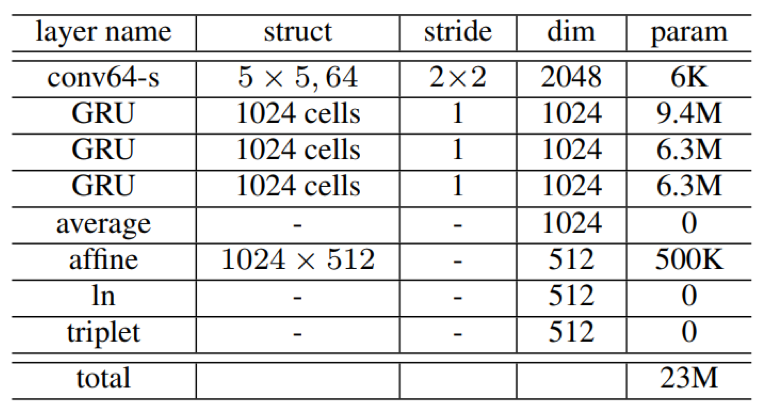
GRU
- 优化算法:SGD,momentum=0.99;lr=0.05线性下降到0.005
- 损失函数:前10 epochs CE交叉熵预训练,softmax损失相比triplet损失训练更快更稳定,因其不受样本对的变化影响;后15 epochs采用triplet loss训练
实验:
- 相近参数量情况下,ResCNN的效果比GRU要好;此外,softmax预训练+triplet重训练相比单一的训练模式效果要更好
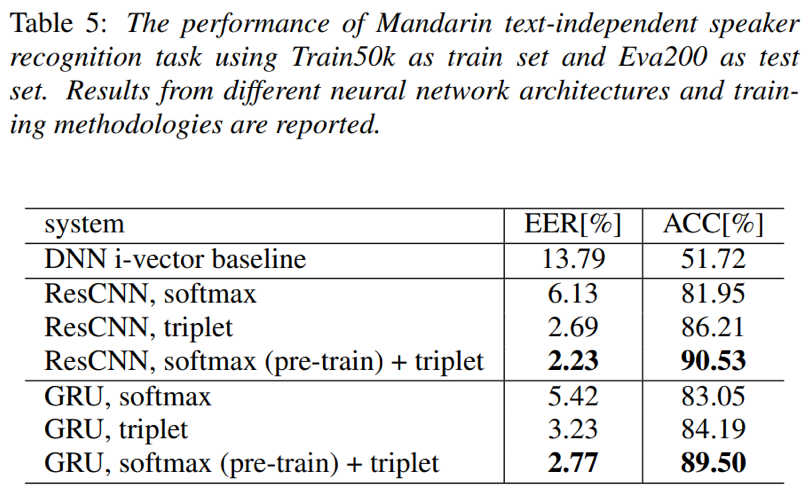
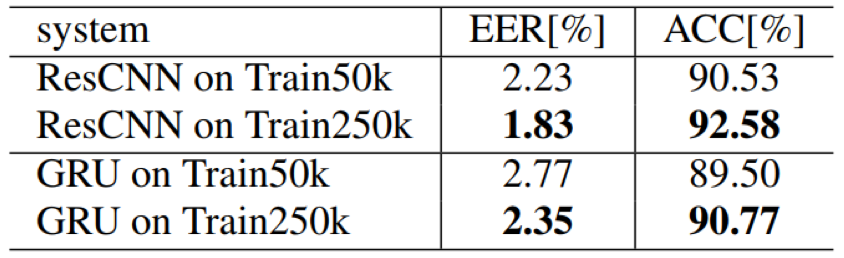
- 在文本无关的说话人验证任务上,训练数据集越大,模型的训练越充分,效果越好
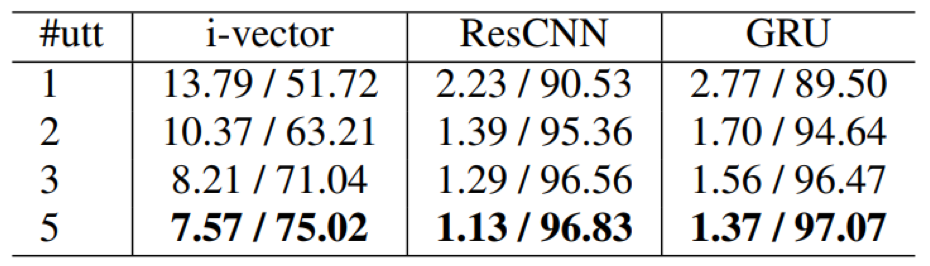
- 在说话人验证任务中,注册句子的个数会对结果产生一定的影响,因为句子个数越多,包含说话人信息越多,说话人的特征表达就越充分;当然,经过一些论文实验验证,说话人注册句子个数并非越多越好,当达到一定的数量后继续增加没有带来额外的提升
- 模型finetune有助于提升模型的泛化能力,因为一个好的初始化模型会让模型避免陷入局部最优;此外,从实验结果来看,GRU的finetune效果相比Resnet效果要好
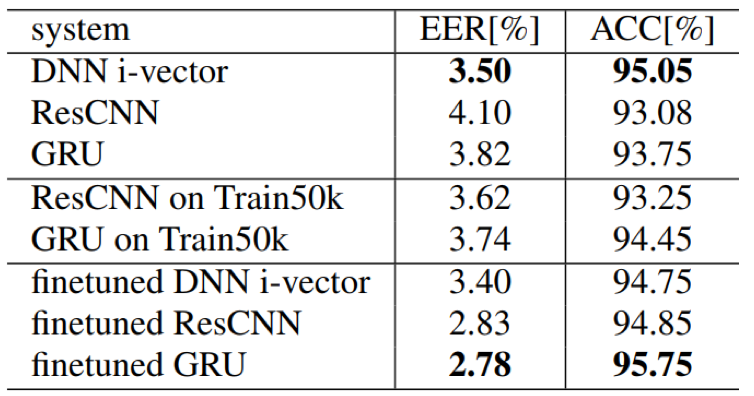
Train50k pre-train XiaoDu fintune
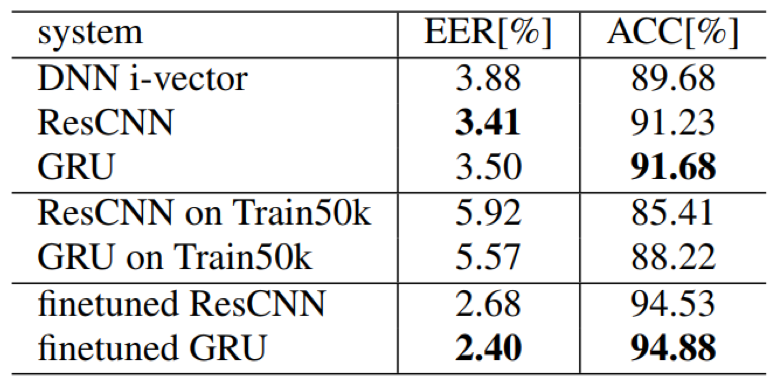
Train50k pre-train MTurk fintune
- 模型融合策略有助于提升说话人验证效果;从效果来看,cosine得分的融合相比编码层面的融合效果稍好一些
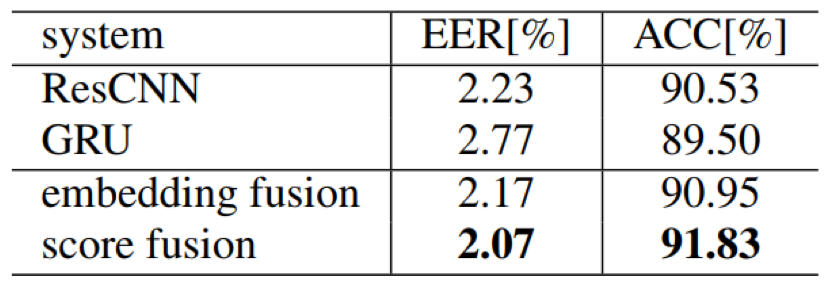
- 时间跨度鲁棒性:注册句子和test句子的时间跨度越长,模型的效果会逐渐下降,但ResCNN依然取得了最好的效果

结论:
本文提出了一种端到端的说话人编码方法,该方法采样ResCNN或GRU进行帧级别的特征提取,然后采用时间平均层将输入序列帧级别的特征转化为句子级别的特征编码,通过softmax pretrain+triplet重训练、以及模型融合或fintune等tricks,使得算法效果取得了远超基于DNN i-vector+PLDA的说话人识别方法
代码实现可参见:
(1) https://github.com/philipperemy/deep-speaker,是deep-speaker的基于keras的非官方复现;该代码采用数据集为librispeech,模型架构为ResCNN;训练的模型可供下载用作预训练模型使用
(2) https://github.com/Walleclipse/Deep_Speaker-speaker_recognition_system,该复现包含ResCNN和GRU两种结构实现,在Librispeech上EER为~5%左右,该方法经过本人实践有效
Reference:

