

声纹识别算法阅读之TE2E
论文:
ATTENTION-BASED MODELS FOR TEXT-DEPENDENT SPEAKER VERIFICATION
思想:
可以看作是在Google15年提出的d-vector算法的改进,
1)采用可学习的带权重和偏置的cosine得分;
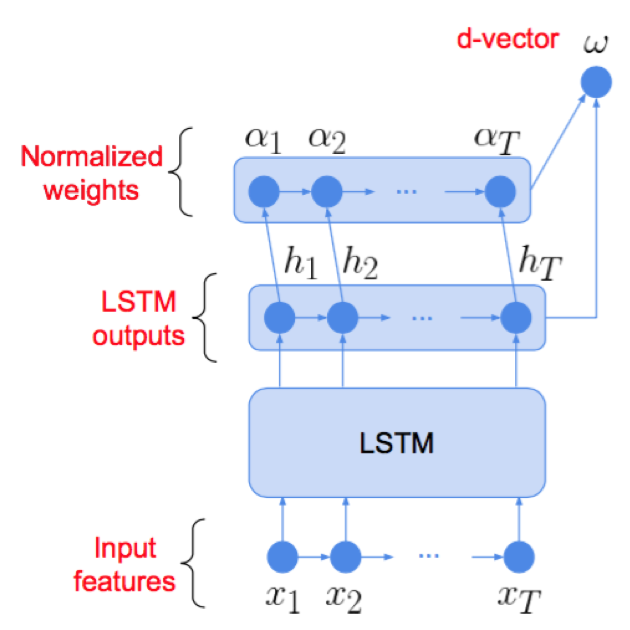
2)为减少语句中的噪声和静音干扰,对LSTM的输出引入attention机制,自动学习时序依赖的重要性;此外,还对输出进行了最大池化操作以提升模型时序变化鲁棒性。
模型:
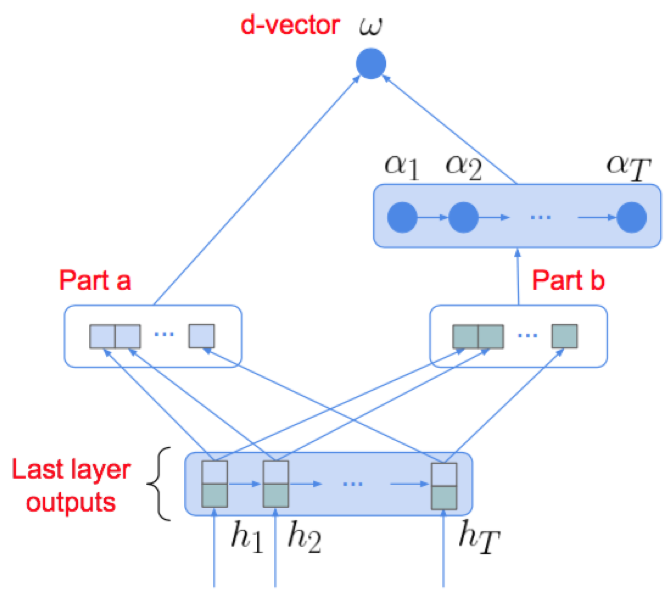
本文采用多层LSTMP结构,为减少噪声和静音影响,在LSTM结构后接attention结构;此外,对attention权重进行最大池化操作来提升模型对时序变化的鲁棒性;损失采用逻辑思特回归损失函数;注册时,代表说话人的N个文本相关语句输入到网络中得到特征表达后取平均,以此作为说话人特征表达;test语句同样输入到网络中提取特征表达;test表达和说话人表达计算带权重的cosine得分;
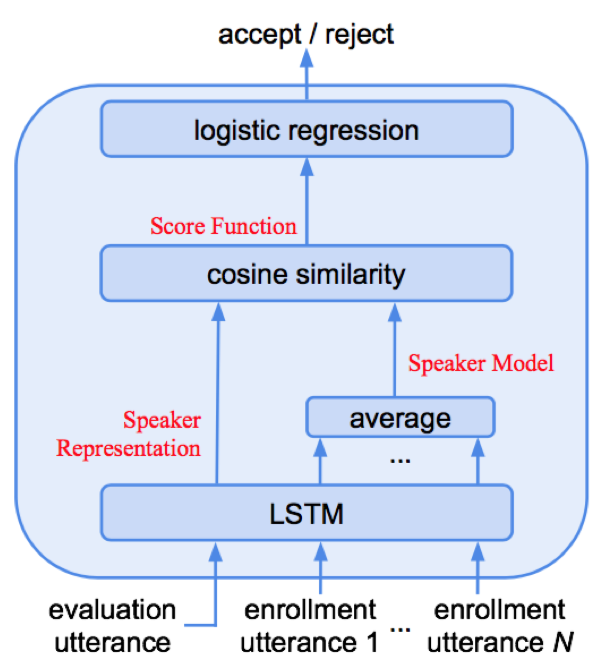
- 相似度计算:ck为N个文本相关语句的均值特征,w~为attention输出,w、b为cosine权重和偏置
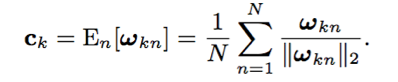
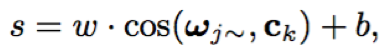
- LSTMP:LSTM结构通过三个门控单元对流入流出信息进行筛选过滤,在时序依赖建模方面具有一定的优势;在LSTM后接一层低维的线性映射来减少模型参数;
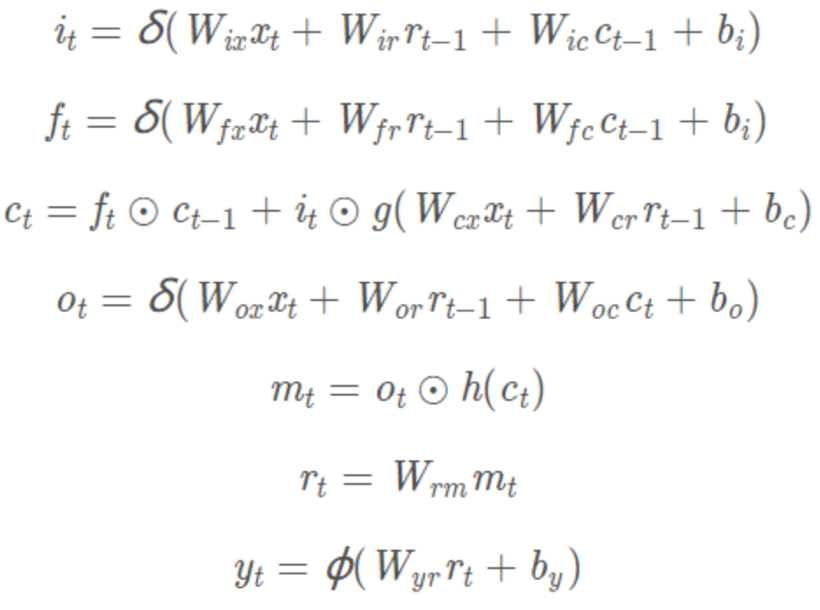
- attention: attention结构能够对时序依赖的重要性进行建模,降低噪声、静音等造成的影响;attention的核心在于权重因子αt的学习,αt决定了时序的上下文信息中重要性;一般αt的计算通过多层感知机结构实现
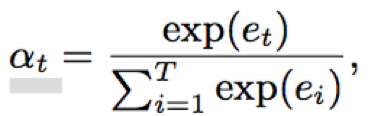
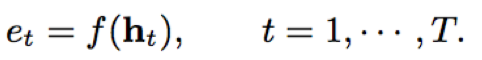
- 本文对于et的映射函数f进行了讨论,主要包括常量因子、线性函数、权重共享线性函数、非线性函数、权重共享非线性函数
1)常量因子
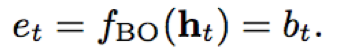
2)线性函数
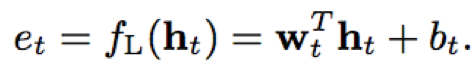
3)权重共享线性函数

4)非线性函数
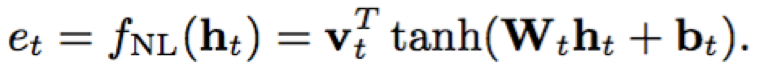
5)权重共享非线性函数
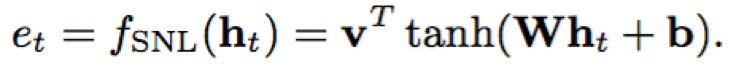
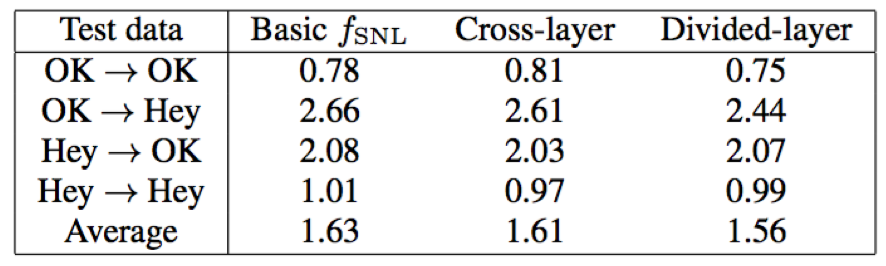
- 本文对于αt的输入也进行了讨论,分为跨层输入和分层输入
1)跨层输入:采用倒数第二层的LSTM输出作为attention输入
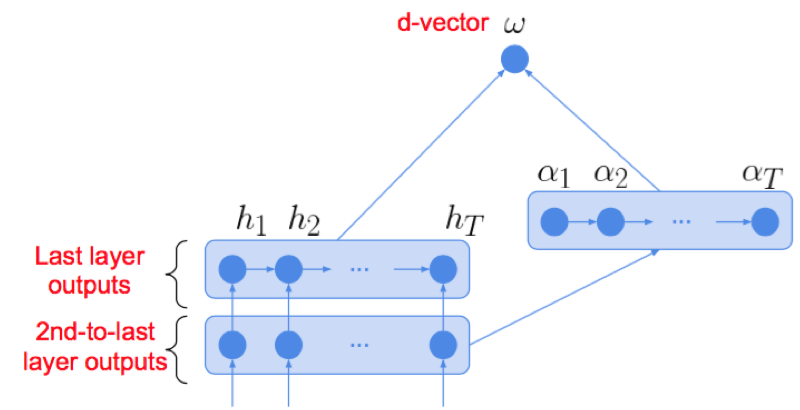
2)分层输入:采样最后一层LSTM输入作为attention输入
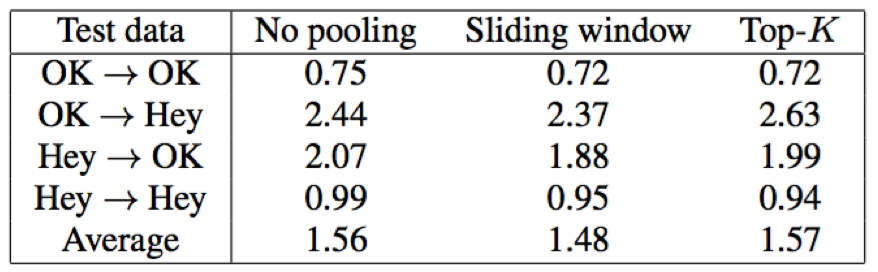
- 最大池化:本文采用了两种最大池化策略,对attention权重α进行最大池化操作,提升模型对时序变化的鲁棒性
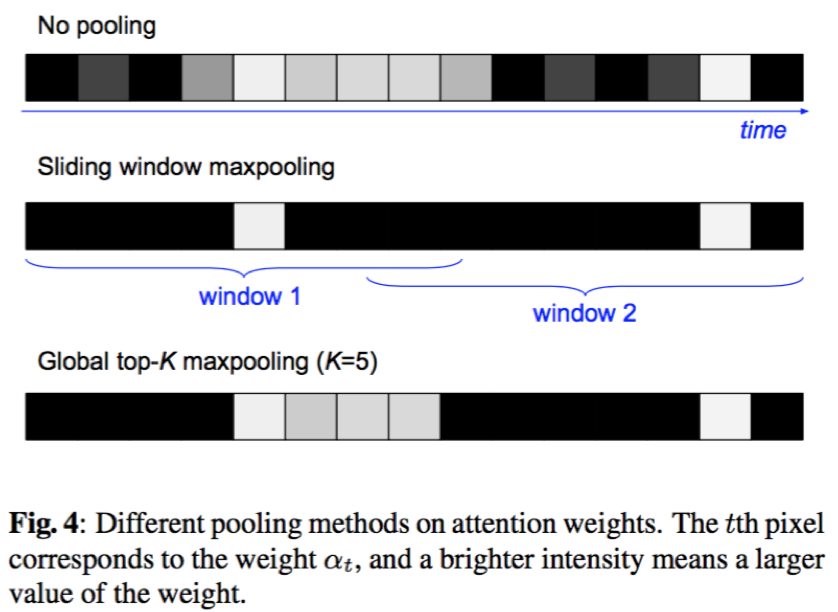
- 滑窗最大池化:采用固定大小窗口沿着权重α的维度进行滑动,每个窗口取保留最大值,其余置为0
- 全局最大池化:对α进行全局最大池化,仅保留最大的K个维度值,其余置为0
- 损失函数:逻辑斯特回归二分类函数,输入为cosine得分;当test语句的说话人j与说话人k相同时,δ为1,否则为0,σ即为sigmoid函数
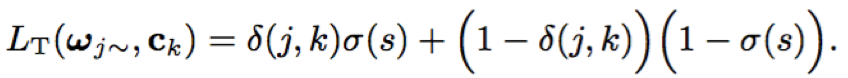
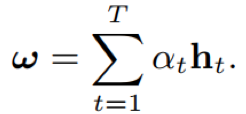
训练:
- 数据集:
- 训练集:“OK Google” 和“Hey Google”的混合语料630k speakers 150M utts;
- 测试集:人工收集的“OK Google” 和“Hey Google”共计665 speakers;分为两个注册集和两个验证集,分别对应“OK Google” 和“Hey Google”;
- 关键词检测系统KWS[1]:提取800ms(80帧)语句长度
- 输入特征:40维log-fbank
- 模型结构:3*LSTMP(128,64)
- 最大池化层:
- 滑窗最大池化的窗口为10帧,步长为5帧
- 全局最大池化的k值为5
- 错误率指标:等错率EER(错误接受率FAR,错误拒绝率FRR)
实验效果:
- 从文本相关说话人确认效果来看,attention结构确实能够在一定程度上提升识别效果;此外,对于不同attention函数,权重共享非线性函数效果最好,然后分别是非线性函数、权重共享线性函数、线性函数、常量因子
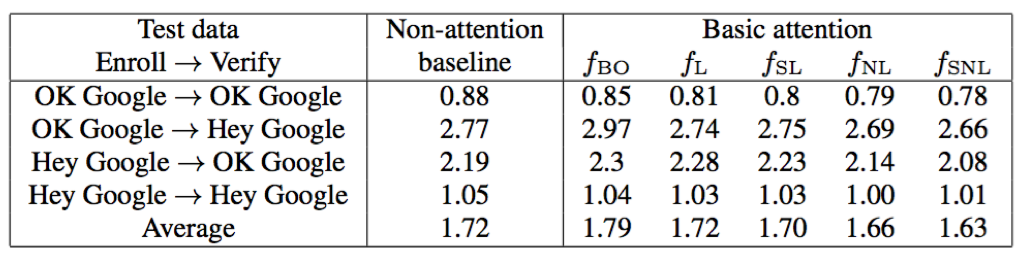
- attention结构的输入,选择最后一层LSTM的输出,相比于倒数第二层显然效果更好一点
- 从实验结果看,对attention权重进行最化池化操作在一定程度上确实能够提升了模型对时序变化的鲁棒性;滑窗最大池化操作相比全局最大池化操作又具有一定的优势

结论:
本文提出了一种基于关键词提取的文本相关说话人确认系统,并通过实验验证了该系统的有效性;通过系统性实验比较,得到的最佳实践为:1)采用了一种权重共享的非线性attention函数;2)采用最后一层的LSTM输出作为attention函数输入;3)对attention权重向量应用滑窗最大池化操作;通过以上优化,本文相比于基于LSTM的d-vector将EER降低了14%;
Reference:

