

HBase笔记4(调优)
Master/Region Server调优
JVM调优
默认的RegionServer内存是1G,而Memstore默认占40%,即400M,实在是太小了,可以通过HBASE_HEAPSIZE参数修改(CDH界面也可以修改)
1)通用调整,同时调整MASTER Region Server
vim $HBASE_HOME/conf/hbase-env.sh
export HBASE_HEAPSIZE=8G ===> 会生效HBASE的所有实例,MASTER和Region Server
2)Permsize调整
hbase-env.sh中含有配置如下:

意思为配置MAster Region Server的永久对象区(Permanent Generation,这个区域在非堆内存里面)占用128M的内存,这个配置在JDK7下运行,JDK8无需设置,设置也无用
3)设置JVM使用的最大内存
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -Xms4g -Xmx4g" 设置MASTER的JVM内存为4G 可以设置为其他大小
export HBASE_REGIONSERVER_OPTS="$HBASE_MASTER_OPTS -Xms8g -Xmx8g" 设置Region server内存为8G
注:系统需要至少10%内存进行必要操作
如何根据机器内存大小设置合适的Master或Region Server内存大小
官方参考:16G内存机器。同时包含MR ,Region Server ,DataNode服务
建议配置: 2G 系统
8G MR(1G=6*map+2*reduce)
4G HBase RegionServer
1G TaskTracker
1G DataNode
若同时运行MR任务,Region Server将是除MR以外使用内存最大的服务,若无MR,Region Server可以调到大概一半的服务器内存
4)Full GC问题
JVM越大,Full GC时间越长,Full GC时,JVM会停止响应任何请求,所以这种暂停叫Stop-The-World(STW),这会导致Region Server不响应Zookeeper的心跳,让Zookeeper误认自己宕机
,为防止脑裂,Region Server会叫停自己(自杀)
GC回收策略优化
JVM提供4种GC回收器:串行回收器 并行回收器(针对年轻代优化,JDK8默认) 并发回收器(CMS,针对年老带) G1GC回收器(针对大内存32G上优化)
组合方案1:并行GC+CMS
年轻代使用并行回收器 年老代使用CMS
$HBASE_HOME/conf/hbase-env.sh 中 HBASE_REGIONSERVER_OPTS内加入 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
-XX:+UseParNewGC 并行GC回收器
-XX:+UseConcMarkSweepGC CMS并发回收器
组合方案2:G1GC
内存小于4G,直接使用方案1
内存大于32G且JDK版本大于1.7,可考虑G1GC方案
引入原因:如下2中情况还是会触发Full GC
A. CMS工作时,一些对象从年轻代移动到年老代,但是年老代空间不足,此时只能触发Full Gc
B. 当回收掉的内存空间太碎太细小,导致新加入年老代的对象放不进去,只能触发Full GC来整理空间
G1GC策略通过把堆内存划分为多个Region,然后对各个Region单独进行GC,这样整体的Full GC可以被最大限度避免,该策略可以指定MaxGCPauseMillis参数来控制一旦发生
Full GC时的最大暂停时间,避免长时间暂停造成Region Server自杀,设置方式为 HBASE_REGIONSERVER_OPTS中添加参数 -XX:MaxGCPauseMillis=100
调试时加上调试参数: -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy
参考参数: 32G heap时 -XX:G1NewSizePercent=3
64G heap时 -XX:G1NewSizePercent=2
100G+ -XX:G1NewSizePercent=1
其他参数:
-XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:+parallelRefProcEnabled -XX:-ResizePLAB -XX:ParallelGCThreads=8+(40-8)(5/8)=28 -XX:G1NewSizePercent=1
5)memstore专属JVM策略MSLAB
100G内存使用CMS策略还发生Full GC原因
A. 同步模式失败
新生代过快的转化为老生代对象时发现老生代可用空间不够,此时会停止并发收集过程,转为单线程的STW(stop the world)暂停,这回到Full GC过程
可以设置 -XX:CMSInitiating0ccupancyFraction=N ,N代表当JVM启动来及回收时堆内存的占用百分比,设置越小,JVM越早启动垃圾回收,一般设置为70
B. 碎片化造成失败
memstore 定期刷写成一个HFile,memstore 占用的内存空间就会被回收,但memstore 占用的空间不是连续的且可能很小,就会出现碎片化
JVM提出了一个TLAB解决方案:当使用TLAB时,每个线程都会分配一个固定大小的内存空间,这样就不会出现特别小的碎片空间,但是会导致内存空间利用率低
HBASE实现了一个MSLAB方案,继承了TLAB,引入如下概念:
chunk: 一块内存,大小2M
RegionServer维护一个全局的MemStoreChunkPool实例,是一个chunk池
每个Memstore实例里又一个MemStoreLAB实例
当MemStore接收到keyvalue数据时,先从chunk pool中申请一个chunk,然后放到这个chunk里
如果这个chunk满了,再申请一个
memstore因为刷写而释放内存,则按chunk来清空内存
设置参数: hbase.hregion.memstore.mslab.enabled=true 打开MSLAB,默认为true
hbase.hregion.memstore.mslab.chunksize=2M 设置每个chunk大小,默认2M
hbase.hregion.memstore.mslab.max.allocation=256K 能放入chunk的最大单元格大小,默认256K
hbase.hregion.memstore.chunkpool.maxsize=0.0 在整个memstore可以占用的堆内存中,chunkpool可以占用的比例(0.0~1.0),默认0.0
hbase.hregion.memstore.chunkpool.initialsize=0.0. regionserver启动时可以预分配一些空的chunk出来到chunk pool里面待使用,该值代表了预分配chunk占总chunkpoll的比例
Region性能优化
Region的自动拆分
1)按照固定大小拆分
0.94版本的HBase只有一种拆分策略,按照固定大小拆分,参数 hbase.hregion.max.filesize.region=10G ,当region超过10G则HBase拆分成2个Region
2)限制不断增长的文件尺寸策略
文件的尺寸限制是动态的,依赖以下公式计算: Math.min(tableRegionsCount^3*initialSize,defaultRegionMaxFileSize)
tableRegionCount : 表在region server上拥有的region数量总和
initialize: 若定义了 hbase.increasing.policy.initial.size,则使用这个数值,否是就用memstore 刷写的2倍,即hbase.hregion.memstore.flush.size*2
defaultRegionMaxFileSize: region得最大大小,即hbase.hregion.max.filesize
math.min 取这2个数值得最小值
3)自定义拆分点(依据行键前缀)
保证拥有相同前缀得rowkey不会被拆分到2个不同得region里面 ,涉及参数keyPrefixRegionSplitPolicy.prefix_length 前缀得长度
该策略会依据前缀长度参数截取rowkey最为分组依据,同一个组得数据不会被划分到不同region上
4)依据行键得分隔符(也是根据行键前缀进行切分)
这个策略需要表定义以下属性:DelimitedKeyPrefixRegionSplitPolicy.delimiter 前缀分隔符
例: 定义分隔符 _, host1_001得前缀为host1
5)访问频率拆分(热点拆分)
涉及参数: hbase.busy.policy.blockRequests:请求阻塞率,即请求被阻塞得严重程度,取值0.0~1.0,默认0.2,20%请求被阻塞
hbase.busy.policy.minAge:拆分得最小年龄,防止在判断是否拆分时出现短时间得访问频率波峰,结果没必要拆分Region被拆
hbase.busy.policy.aggWindow 计算是否繁忙得时间窗口,单位毫秒,默认5min,用以控制计算频率
计算Region是否繁忙得计算方法:
当前时间-上次检测时间=>hbase.busy.policy.aggWindow,则进行如下计算:这段时间被阻塞得请求/这段时间得总请求 = 请求得被阻塞率,如果请求得被阻塞率 > hbase.busy.policy.blockRequests ,则该Region为繁忙
6)永不拆分策略
Region的手动拆分
手动拆分有2种情况,预拆分和强制拆分
Region的预拆分
建表时定义拆分点的算法,叫预拆分,使用org.apache.hadoop.hbase.util.RegionSplitter类创建表,并传入拆分点算法就可以在建表同时定义拆分点算法
ex:hbase org.apache.hadoop.hbase.util.RegionSplitter my_split_table HexStringSplit -c 10 -f mycf
新建表my_split_table,并根据HexStringSplit拆分点算法预拆分为10个Region,同时建立一个列族mycf
拆分点算法:
HexStringSplit 算法参数 n:要拆分的region数量
把数据从00000000到FFFFFFFF之间的数据长度按照n等分之后,算出每一段的起始rowkey和结束rowkey,以此作为拆分点
UniformSplit
起始rowkey是ArrayUtils.EMPTY_BYTE_ARRAY
结束rowkey是new byte[] {xFF,xFF,xFF,xFF,xFF,xFF,xFF,xFF}
最后调用Bytes.split把起始行键和结束行键之间长度n等分,然后取每一段的起始和结束作为拆分点
手动指定拆分点:建表时指定SPLITS参数
create 'table1','mycf2',SPLITS=>['aaa','bbb']
Region强制拆分
ex: split 't1,c,14764.96dd8‘,’999' 把t1,c,14764.96dd8这个region从新的拆分点999处进行拆分
split方法的调用方式:
split ‘表名’
split ‘namespace:tablename’
split 'regionName' #format: 'tableName,startKey,id'
split 'tableName','splitKey'
split 'regionName','splitKey'
推荐方案:
预拆分导入初始数据。然后使用自动拆分让HBase管理Region
Region的合并
通过merge进行合并(冷合并)
通过使用org.apache.hadoop.hbase.util.Merge类实现
ex: hbase org.apache.hadoop.hbase.util.Merge tablename regionname1 regionname2 (需要先停止Hmaster,Hregionserver)
热合并
hbase shell提供了online_merge 来实现热合并,参数是region的hash值
ex: merge_region region1hash值 region2hash值 ====》2个region都需要上线


WAL优化
WAL文件的数量当增长到一定程度时会出现滚动,清除旧日志
WAL优化参数:hbase.regionserver.maxlogs: Region种最大WAL文件数量,默认32
新版HBase会自动设置,公式

hbase.regionserver.hlog.blocksize: HDFS块大小,不设定则使用HDFS的设置值
hbase.regionserver.logroll.multiplier WAL 文件大小因子,默认0.95
每个WAL文件大小=HDFS块大小*WAL文件大小因子
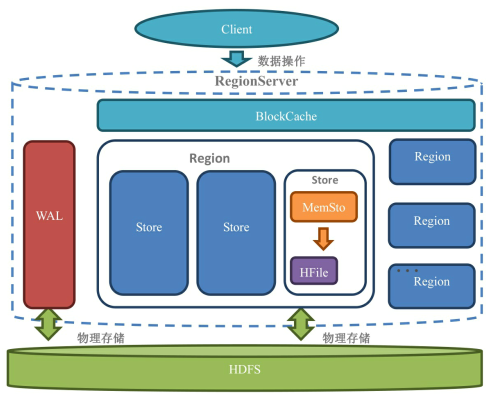
读请求到达HBase之后,先查询Block Cache,如果获取不到就去HFile和Memstore中获取,如果获取到了则在返回数据的同时把Block块缓存到Block Cache中
Block Cache默认开启,若要某个列族禁止使用Block Cache,执行alter 't1',CONFIGURATION=> {NAME=> 'cf',BLOCKCACHE=>'false'}
Block Cache实现方案:
1)LRUBlock Cache (基于JVM heap 近期最少使用算法缩写, 一级缓存)
LRUBlock Cache的3个区域
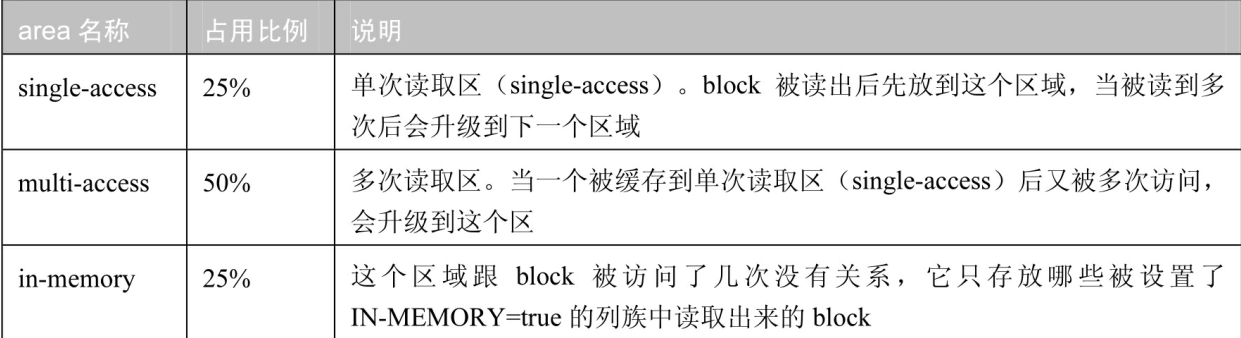
hfile.block.cache.size.LRUBlockCache 占用内存比例,默认0.4
设置hfile.block.cache.size时需要注意Memstore+BlockCache内存占用比例不能超过0.8,即80%
hfile.regionserver.global.memstore.size+hfile.block.cache.size <=0.8
2)SlabCache (堆外内存尝试方案)
调用nio的DirectByteBuffers,把堆外内存按照80%,20%比例划分为2个区域: 存放大小约1个blocksize默认值的Block;存放大小约2个blocksize默认值的block
该方案可用性不大,放弃
3)Bucket Cache (二级缓存)
BucketCache分配了14种区域,存放大小分别为4K,8K,16K,32K,40K,48K,56K,64K,96K,128K,192K,256K,384K,512K的Block
可以手动配置 hbase.bucketcache.bucket.sizes属性来定义
Bucket Cache存储可以通过hbase.bucketcache.ioengine进行设置,为堆heap,堆外offheap,文件file
每个Bucket的大小上限为最大尺寸的Block*4,每种类型的Bucket至少要一个Bucket
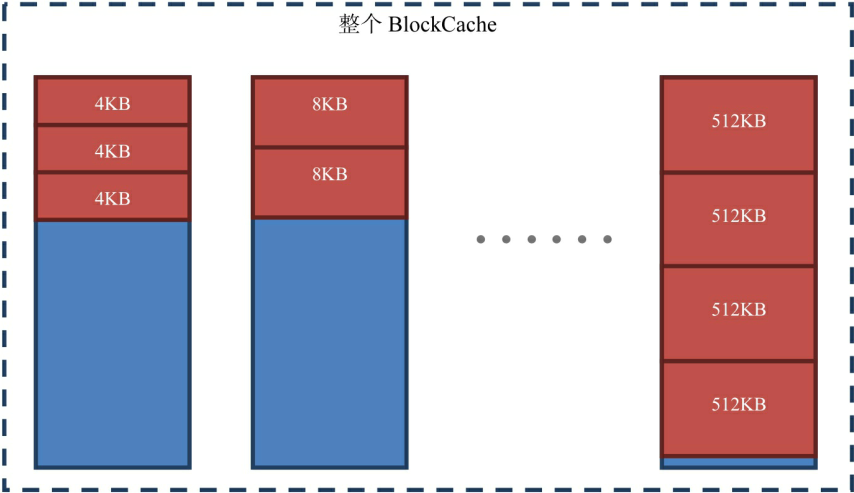
BucketCache可以自己划分内存空间,自己管理内存空间,所以内存碎片少
配置项:默认开启
列族关闭BucketCache:
alter 'table',CONFIGURATION => {CACHE_DATA_IN_L1=>'true'}
hbase.bucketcache.ioengine:使用的存储介质 ,可选heap,offheap(默认),file
hbase.bucketcache.combinedcache.enabled 是否打开组合模式,默认true
hbase.bucketcache.size bucketcache所占大小 ,0关闭 0.0~1.0 代表占堆内存百分比 ,大于1,代表实际的大小,单位MB
hbase.bucketcache.bucket.sizes 定义所有block种类,默认14种
-XX:MaxDirectMemorySize JVM启动参数,定义JVM可获取堆外内存的上限,必须比hbase.bucketcache.size大
4)组合模式
具体来说:把不同类型的Block分别存放到LRUCache BucketCache中
合理介质:一级缓存->二级缓存->硬盘 数据从小到大 存储介质由快到慢
LRUCache使用内存-> BucketCache 使用SSD-> HFile使用机械硬盘
查看缓存命中率: hbase.regionserver.blockCacheHitRatio 取值范围0.0~1.0
MemStore优化
读写中的memstore
memstore实现的目的是维持数据结构
开启Block Cache,读取数据先查询Block Cache,Block Cache查询失败后,则查询memstore+HFile数据,由于有些数据还未刷写HFile,
所以memstore+HFile才是所有数据集合
memstore的刷写
memstore的优化核心在于理解memstore的刷写flush,大部分性能问题是写操作被block,无法写入Hbase
memstore触发刷写机制:
1. 大小达到刷写阈值 hbase.hregion.memstore.flush.size
由于刷写是定期检查的,所以无法及时触发阈值刷写,若数据增长太快,提前超出阈值,会触发阻塞机制,此时数据无法写入memstore
阻塞机制的阈值=hbase.hregion.memstore.flush.size*hbase.hregion.memstore.block.multiplier
=刷写阈值(默认128M)*倍数
数据到达阻塞阈值,直接触发刷写并阻塞所有写入该store的写请求
2. 整个Region Server的memstore总和达到阈值
触发刷写阈值=globalMemstoreLimitLowMarkPercent*globalMemStoreSize
=全局memstore刷写下限 (百分比0.0~1.0) * 全局memstore容量
全局memstore容量=hbase_heapsize(RegionServer占用堆内存大小)*hbase.regionserver.global.memstore.size(默认0.4)
触发阻塞阈值= globalMemStoreSize
4. memstore达到刷写时间间隔
hbase.regionserver.optionalcacheflushinterval memstore刷写时间间隔,默认1个小时,设置为0,则关闭自动定时刷写
5. 手动触发flush
flush 'table_name' 刷写单个表
flush ‘region_name’ 刷写单个region
memstore性能优化主要是防止触发阻塞,避免对业务造成灾难性性后果
HFile性能优化(合并) compaction
Hfile文件过多,读取数据寻址就多了,为了防止过多的寻址动作,适当减少碎片文件,需进行合并操作
合并分为2种操作:
Minor Compaction: 将多个HFile合并为一个HFile.在这个过程中达到TTL的数据会被移除,但是手动删除的数据不会被移除,触发频率高
Major Compaction:合并一个store所有的HFile为1个,手动删除的数据会被移除,同时删除单元格内版本超过maxversion版本数据,触发频率低,7天一次,但是消耗的性能较大
0.96版本后提出一个合并算法 ExploringCompactionPolicy算法
该算法修改合并文件挑选条件: 该文件 < (所有文件大小总和 - 该文件大小) * 比例因子
若果该文件的大小小于最小合并大小(minCompactionSize),则直接进入待合并列表
最小合并大小: hbase.hstore.compaction.min.size 若没有设置则使用hbase.hregion.memstore.flush.size
以组合作为计算单元: 被挑选的文件必须通过筛选条件,并且组合内含有文件数必须大于hbase.hstore.compaction.min
小于hbase.hstore.compaction.max (就是选择一个组合内几个文件进行合并)
FIFOCompactionPolicy
本质是一种删除策略,最终效果是 : 过期的块被整个删除,没过期的块完全没有操作
不能应用的环境: 1)表没有设置TTL,或TTL=forever
2) 表设置了MIN_VERSION,并且MIN_VERSION > 0
DateTiredCompactionPolicy
配置项:hbase.hstore.compaction.date.tiered.base.window.millis 基本的时间窗口时长,默认6小时,即从现在开始的6个小时内HFile都在同一个时间窗口里面
hbase.hstore.compaction.data.tiered.window.per.tier 层次的增长倍数,分层时越老的时间窗口越宽
同一个窗口里面的文件如果达到最小合并数量(hbase.hstore.compaction.min)就会进行合并,根据hbase.hstore.compaction.date.tiered.window.policy.(所定义的合并规则来合并),默认ExploringCompactionPolicy
hbase.hstore.compaction.date.tiered.max.tier.age.millis 最老的层次时间,当文件老到超出定义的时间,就不进行合并
如果一个文件跨时间线的时候,该文件计入下一个时间窗口(更老更长的时间窗口)
StripeCompactionPolicy 适合读性能
每一层文件大概是上一层的10倍
合并时会把keyvalue从level 0(L0) 读取出来,然后插到level1 的FILE文件中,level1是根据键位范围(rowkey range)来划分
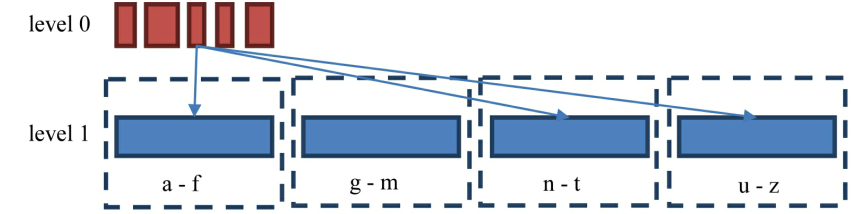
适用场景: Region很大,Row Key具有统一的格式
Compaction的吞吐量限制参数:
compaction机制会造成IO突然降低问题
相关可设置参数: hbase.regionserver.throughtput.controller 限制的类型对应类名,可选 PressureAwareCompactionThroughtController控制合并相关指标 和 PressureAwareFlushThroughtputController 控制刷写相关指标,默认为PressureAwareCompactionThroughtputController
hbase.hstore.blockingStoreFiles 当StoreFile数量达到该值,阻塞刷写动作,默认7
该参数设定不当可能造成memstore占用内存数量急剧上升,到达上限,集群就会挂掉,可设置20-50
hbase.hstore.compaction.throughtput.lower.bound 合并占用吞吐量下限
hbase.hstore.compaction.throughtput.higher.bound 合并占用吞吐量上限
合并/刷写吞吐量限制机制:
HBase 计算 合并/刷写 占用的吞吐量,当吞吐量过大时会适当休眠
hbase.offpeak.start.hour 每天的非高峰起始时间,取值0-23
hbase.offpeak.end.hour 每天非高峰结束时间,取值0-23
休眠吞吐量的阈值=lowerBound + (upperBound - lowerBound) * pressureRatio
lowerBound :
hbase.hstore.compaction.throughput.lower.bound 合并占用吞吐量下限 默认10MB/s
upperBound:
hbase.hstore.compaction.throughtput.higher.bound 合并占用的吞吐量下限 默认20MB/S
pressureRatio 压力比 限制合并时,该参数就是合并压力,显示刷写时,该参数就是刷写压力,取值0-1.0
压力比越大,HFile堆积的越多,或即将产生越多的HFile
压力比分为 : 合并压力 刷写压力
合并压力计算:=(storefilecount - minFilesToCompact)/(blockingFileCount - minFilesToCompact)
storefilecount 当前storeFile数量
minFilesToCompact:单次合并文件数量下限,即hbase.hstore.compaction.min
blockingFileCount = hbase.hstore.blockingStoreFiles
刷写压力计算:= globalMemstoreSize/memstoreLowerLimitSize
globalMemstoreSize 当前memstore大小
memstoreLowerLimitSize Memstore刷写下限,当全局memstore达到这个内存占用数量时开始刷写
HBase 合并文件流程:
1)获取需要合并的Hfile列表
获取列表时需要除掉带锁的HFile,锁分为读锁 写锁
以下操作会上锁: 用户scan查询,上Region锁 ;Region切分,region先关闭上写锁;Region关闭,写锁;Region导入,写锁
2)由列表创建StoreFileScanner
HRegion 会创建一个Scanner,读取本次要合并的所有StoreFile上的数据
3)把数据从HFile中读出,并放到tmp目录(临时文件夹)
HBase 会在临时目录创建新的HFile,并使用建立的Scanner从旧HFile上读取数据,放入新HFile
以下数据不会读取: 数据过期了 带墓碑标记的数据
4)用合并后的HFile来替换合并前的HFile
Major compaction:
hbase.hregion.majorcompaction majorcompaction发生的周期,默认7天 ,等于0则为关闭
hbase.hregion.majorcompaction.jitter 周期抖动参数 0-1.0,可以让major compaction发生时间更灵活,默认0.5
major compaction对系统的压力还是很大,建议关闭自动选择手动触发方式


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· .NET周刊【3月第1期 2025-03-02】
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器