HBase 笔记1
cap理论: 一致性 可用性 可靠性
任何分布式系统只能最多满足上面2点,无法全部满足
NOSQL = Not Only SQL = 不只是SQL
HBase速度并不快,知识当数据量很大时它慢的不明显
HBase缺点:
数据分析是弱项,对于整个NOSQL生态圈,基本都不支持表关联
需求如下时不支持使用HBase:
主要需求是数据分析,比如做报表
单表数据量不超过千万
需求如下时使用HBase:
单表数据量超过千万,并发还挺高
数据分析需求弱,或不需要那么灵活/实时
宏观上看
HBase部署架构上分为: Master服务器 RegionServer服务器
一般情况下:一个集群=1*Master服务器+N*RegionServer服务器
Master服务器维护表结构信息
Region Server服务器负责存储实际数据,保存的表数据直接存储在HDFS上; RegionServer依赖Zookeeper服务,Zookeeper扮演着管家的角色,管理所有Region Server信息,包括具体的数据段存放在哪个Region Server
客户端每次与HBase连接,都是先和Zookeeper通信,查询出需要连接哪个Region Server,然后再连接Region Server
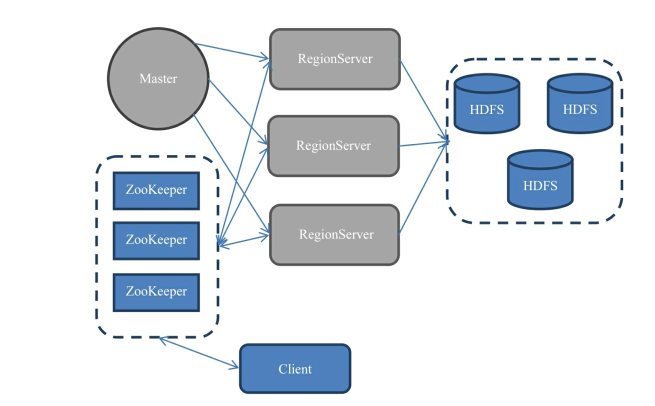
HBase特殊一点:客户端获取数据由客户端直接连接RegionServer, Master挂掉依然可以查询数据,存储/删除数据,但是不能新建表
微观上看
Region: 是一段数据的集合(多个行的集合), HBase中的表可以分成1个或多个Region
一个Region Server上存在1个或多个Region
数据量大时,HBase会拆分Region
Hbase负载均衡时,Region可能会从一个Region Server上移到另一个RegionServer上
Region是基于HDFS实现的
RegionServer 是存放Region的容器,直观上就是服务器上的一个服务
Master 角色像是打杂的,只负责各种协调工作,如建表,删除表等,他们的共性就是需要跨Region Server
存储架构
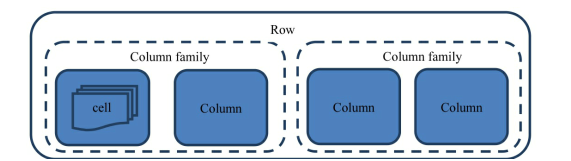
HBase最基本的存储单位是列 一列或多列形成一行row
HBase不是严格的行列对齐,这一行可能有3列,下一行有4列,行与行的列可以完全不一样
每个行都有唯一的行键row key来标定这个行的唯一特性,每个列有多个版本,多个版本的值存在单元格cell(单元格是数据存储的最小单位)中
行键row key: 由用户指定的一串不可重复的字符串,HBase是根据行键来进行排序(字典排序)进而确定存储位置
若干列组成一个列族
列族需要在建表时就确定,此外表的很多属性(过期时间,数据块缓存等)都定义在列族上,不同的列族有完全不同的属性配置,相同列族内的列具有相同的属性
列必须依赖列族存在,单独的列无意义
HBase中列的名称前面总是带着所属的列族,如b:age
唯一确定一个值: 行键:列族:列:版本号(rowkey:column family:column:version),版本号不写则默认最新的版本
HBase中,每个存储语句必须精确定义的写出数据要存储到哪个单元格,而单元格由 表:列族:行:列定义