学习笔记5
关于知识点
知识点归纳
第十一章 EXT2文件系统
- 11.1 EXT2文件系统
EXT2(第二扩展文件系统)是一种用于Linux中的文件系统。
- 文件系统结构:EXT2文件系统使用了多级的索引结构来组织文件和目录。它包括了超级块、inode、数据块、组描述符等数据结构。
- 文件系统特性:EXT2文件系统支持文件与目录的创建、删除、读取和写入。它可以处理文件的权限和属性。文件系统还支持链接、磁盘配额、日志记录等功能。
- 空间管理:EXT2文件系统使用了位图来管理数据块的分配与回收。它还采用了文件预分配的技术来提高文件的连续性和性能。
- 数据恢复:EXT2文件系统使用了写前日志(WAL)的方法来保证数据的一致性和完整性。它可以在系统崩溃后进行文件系统的恢复和修复。
- 文件系统的优化:EXT2文件系统可以进行碎片整理、磁盘空间的回收和整理,以提高文件系统的性能和效率。
- 文件系统的扩展性:EXT2文件系统支持最大2TB的分区大小和最大32768个子目录。它还可以进行在线调整和动态扩展。
- 兼容性:EXT2文件系统可以被多个操作系统支持,包括Linux、FreeBSD、NetBSD等。
总的来说,EXT2文件系统是一种成熟、稳定且可靠的文件系统,适用于Linux操作系统中的存储管理和数据访问。它提供了高性能的数据存储和高度可靠的数据保护机制。
- 11.2 EXT2文件系统数据结构
- 11.2.1 通过mkfs创建虚拟磁盘
通过mkfs命令可以在操作系统中创建一个虚拟磁盘文件,并为其格式化成指定的文件系统类型(如EXT2)。mkfs命令会在虚拟磁盘上创建文件系统所需的数据结构,以便存储文件和目录。 - 11.2.2 虚拟磁盘布局
虚拟磁盘是由一系列的数据块组成的,并按照特定的布局组织数据。一个虚拟磁盘通常由超级块、块组描述符、块位图、索引节点位图、索引节点表和数据块组成。 - 11.2.3 超级块
超级块是文件系统的关键部分,它包含了文件系统的重要信息,如文件系统的版本、大小、块大小等。超级块存储在虚拟磁盘的固定位置,并用于标识和管理整个文件系统。 - 11.2.4 块组描述符
文件系统通常被分割成多个块组,每个块组包含一定数量的数据块和索引节点。块组描述符存储了每个块组的信息,如空闲数据块的数量、空闲索引节点的数量等。它们分布在文件系统的特定位置,被用于管理块组的使用情况。 - 11.2.5 块和索引节点位图
块位图和索引节点位图分别用于记录块和索引节点的使用情况。它们是一些位数组,其中的每个位代表相应的块或索引节点是否被使用。位图可以帮助文件系统管理和维护空闲块和索引节点的分配。 - 11.2.6 索引节点
索引节点是文件系统中文件和目录的元数据集合,它记录了文件和目录的属性(如大小、权限、时间戳等)以及其在磁盘上的位置信息。索引节点使用一个唯一的编号来标识,并通过索引节点表来组织和访问。 - 11.2.7 数据块
数据块是文件系统中存储文件和目录实际内容的地方。它们被划分成固定大小的块,并按需分配给文件和目录。数据块的大小可以根据文件系统的设置进行调整。 - 11.2.8 目录条目
目录条目是用于组织和管理文件和目录的数据结构。每个目录都包含多个目录条目,每个目录条目包含了一个文件或目录的名称和其对应的索引节点编号。目录条目的组织方式由文件系统决定,通常采用链表或索引方式。
- 11.2.1 通过mkfs创建虚拟磁盘
- 11.3 邮差算法
- 11.3.1 C语言中的Test-Set-Clear位
在C语言中,Test-Set-Clear位(TSC位)是一种位操作技术,通常用于对一个位进行测试、设置或清除。
- 11.3.1 C语言中的Test-Set-Clear位
- Test位:Test位操作用于测试给定位的状态,即判断一个位是置位(1)还是清零(0)。通常使用与运算符(&)和位掩码(例如1 << n)来判断某一位是否被置位。
- Set位:Set位操作将指定位置位,即将某一位设置为1。通常使用或运算符(|)和位掩码(例如1 << n)来将某一位设置为1,保持其他位不变。
- Clear位:Clear位操作将指定位置零,即将某一位设置为0。通常使用与运算符(&)和位掩码的取反(~)来将某一位设置为0,保持其他位不变。
TSC位操作通常在需要对某个位进行操作时使用,例如:
#define FLAG_MASK 0x01 // 位掩码,用于操作某一位
unsigned char flags = 0x00; // 创建一个字节变量
// Test位操作
if (flags & FLAG_MASK) {
printf("Flag is set
");
} else {
printf("Flag is not set
");
}
// Set位操作
flags |= FLAG_MASK; // 将指定位设置为1
// Clear位操作
flags &= ~FLAG_MASK; // 将指定位设置为0
TSC位操作可以用于位字段的操作,例如在数据结构中使用一个字节表示多个开关的状态,或者在嵌入式系统中对寄存器的位进行操作。这种位操作技术可以提高代码的效率和可读性。
- 11.3.2 将索引节点号转换为磁盘上的索引节点
- 11.5 遍历EXT2文件系统树
- 11.5.1 遍历算法
对于EXT2文件系统树的遍历,通常可以使用深度优先搜索(DFS)算法或广度优先搜索(BFS)算法。
- 11.5.1 遍历算法
- 深度优先搜索(DFS):DFS算法首先从根节点(通常为根目录)开始遍历,然后沿着每个子目录递归地遍历,直到遍历到叶子节点(即文件)。在遍历过程中,可以通过递归调用来实现深度遍历。DFS算法会首先遍历一个分支,然后再遍历其他分支。
- 广度优先搜索(BFS):BFS算法从根节点(通常为根目录)开始遍历,然后遍历每一层的节点,直到遍历到叶子节点。在遍历过程中,可以使用队列来存储待遍历的节点。BFS算法会首先遍历距离根节点最近的节点,然后再遍历距离根节点稍远的节点。
下面是对于EXT2文件系统树的遍历算法的步骤: - 获取根节点(根目录)的信息,包括inode和数据块的位置。
- 判断根节点是否为目录。如果是目录,则进入下一步;如果是文件,则处理该文件并结束遍历。
- 根据目录的inode信息读取目录的数据块,获取目录中的文件和子目录的inode号。
- 根据inode号获取文件或子目录的inode信息,包括文件类型、权限、文件大小等。
- 如果该节点为目录,则保存该目录的路径,并将子目录的inode号存入队列(BFS算法)或进行递归调用(DFS算法)。
- 重复步骤3至5,直到遍历到所有文件和目录。
在遍历过程中,可以根据需要对每个文件和目录进行相应的操作,如打印路径、读取文件内容等。需要我们注意的是,EXT2文件系统中存在硬链接和符号链接等特殊文件类型,对这些文件的处理可能需要特殊的考虑。- 11.5.2 将路径名转换为索引节点
- 11.5.3 显示索引节点磁盘块
- 11.6 EXT2文件系统的实现
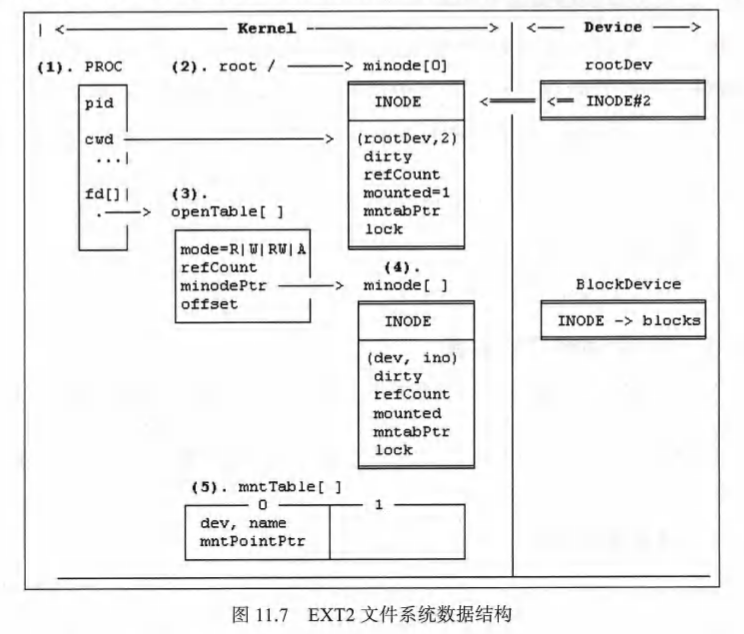
- 11.6.1 文件系统的结构
- 超级块(Superblock):超级块是文件系统的关键部分,包含了文件系统的元信息,如文件系统版本、总块数、块大小、inode(索引节点)数量等。超级块设置在文件系统的固定位置,用于标识和管理整个文件系统。
- 块组描述符(Block Group Descriptor):文件系统通常被分割成多个块组,每个块组包含一定数量的数据块和索引节点。块组描述符存储了每个块组的信息,如空闲数据块数量、空闲索引节点数量等。它们分布在文件系统的特定位置,用于管理块组的使用情况。
- 块位图(Block Bitmap):块位图记录了每个数据块的分配情况,即标记每个块是否被使用。块位图是一种位数组,其中的每个位对应一个数据块,1表示被使用,0表示空闲。块位图用于查找空闲块和分配新块。
- 索引节点位图(Inode Bitmap):索引节点位图记录了每个索引节点的分配情况,即标记每个索引节点是否被使用。索引节点位图也是一种位数组,其中的每个位对应一个索引节点,1表示被使用,0表示空闲。索引节点位图用于查找空闲的索引节点和分配新的索引节点。
- 索引节点表(Inode Table):索引节点表保存了文件和目录的元数据,如文件大小、权限、时间戳等。每个索引节点由一个唯一的索引节点号标识,并存储在文件系统的索引节点表中。索引节点表根据文件系统的设置和需求,具有固定大小或动态大小。
- 数据块(Data Block):数据块是文件系统中存储文件和目录实际内容的地方。数据块的大小可以根据文件系统的设置进行调整。文件和目录的内容分布在一个或多个数据块中,根据需要动态分配和管理。
- 目录项(Directory Entry):目录项是用于组织和管理文件和目录的数据结构。每个目录包含多个目录项,每个目录项包含了一个文件或子目录的名称和对应的索引节点号。目录项可以通过索引节点表中的指针进行查找和遍历。
- 11.6.2 文件系统的级别
第1级别实现了基本文件系统树。
第2级别实现了文件内容读/写函数。
第3级别实现了文件系统的挂载、卸载和文件保护。
- 11.6.2 文件系统的级别
- 11.7 基本文件系统
- 11.7.1 type.h文件
type.h文件是C语言标准库中的一个标头文件(header file),它包含了一些基本的类型定义。
- 11.7.1 type.h文件
- 基本数据类型定义:type.h文件定义了一些基本的数据类型,如大小写字符类型(char、signed char、unsigned char)、整数类型(short、int、long、long long)、浮点类型(float、double)、布尔类型(bool)等。这些类型的宽度和范围在不同的平台和编译器中可能有所不同。
- 其他类型定义:type.h文件还包含了一些其他类型的定义,如指针类型(void)、空类型(void)、文件指针类型(FILE)等。这些类型在程序中使用较为常见,可以用于处理不同类型的数据和操作。
- 标准符号定义:type.h文件中还包含了一些预定义的符号常量,如NULL、true和false,它们通常与指针、布尔类型和条件判断有关。NULL表示一个空指针,true和false分别表示真和假的布尔值。
- 类型大小定义:type.h文件还可以通过宏定义来获取各种数据类型的字节大小。比如,可以使用sizeof宏来确定某个类型的大小。例如,sizeof(int)返回整型的字节大小。
type.h文件在C语言程序中广泛使用,它定义了一些基本的数据类型和符号常量,使得程序编写更加方便和可移植。通过包含type.h文件,程序员可以使用定义好的类型来声明变量、定义函数参数、返回值等,从而提高了代码的可读性和可维护性。- 11.7.2 global.c文件
global.c文件是一个源代码文件,通常用来定义全局变量和全局函数。
- 11.7.2 global.c文件
- 全局变量定义:在global.c文件中,可以定义一些全局变量,这些变量在整个程序中可见。全局变量通常在程序的多个函数中进行读取或修改。在global.c文件中定义的全局变量可以在其他源代码文件中通过extern关键字进行声明和访问。
- 全局函数定义:除了定义全局变量,global.c文件还可以定义一些全局函数。全局函数可以在程序的任何地方被调用,它们可以访问全局变量和其他全局函数。全局函数的定义和声明应该位于头文件中,以便在其他源代码文件中进行函数调用。
- 程序配置:在global.c文件中,还可以定义一些与程序配置有关的全局变量。例如,可以定义一个全局变量来表示程序的版本号或启用某些功能的标志。这些配置变量可以在程序中根据需要进行读取,从而实现程序的不同配置和行为。
- 全局变量和函数的作用域:在global.c文件中定义的全局变量和函数的作用域为整个程序。这意味着它们在整个程序的任何地方都可以被访问和使用。全局变量和函数的定义应该遵循良好的命名规范,以保持代码的可读性和可维护性。
需要注意的是,全局变量和函数的使用应该谨慎,因为它们可能带来代码的耦合性和可变性。在设计程序时,应该合理使用全局变量和函数,避免过多依赖全局状态和副作用,以免造成代码难以理解和调试的问题。- 11.7.3 实用程序函数
- 11.7.4 mount-root
- 11.7.5 基本文件系统的实现
- 11.8 1级文件系统函数
- 11.8.1 creat算法
- 11.8.3 mkdir-creat的实现
- 11.8.4 rmdir算法
- 11.8.5 rmdir的实现
- 11.8.6 link算法
- 11.8.7 unlink算法
- 11.8.8 symlink算法
- 11.8.9 readlink算法
- 1.8.10 其他1级函数
- 11.9 2级文件系统函数
- 11.9.1 open算法
- 11.9.2 lseek
- 11.9.3 close算法
- 11.9.4 读取普通文件
- 11.9.5 写普通文件
- 11.9.6 opendir-readdir
- 11.10 3级文件系统
- 11.10.1 挂载算法
- 11.10.2 卸载算法
- 11.10.3 交叉挂载点
- 11.10.4 文件保护
- 11.10.5 实际uid和有效uid
- 11.10.6 文件锁定
- 11.11文件系统项目的扩展
苏格拉底挑战
问题1:基本文件系统

问题2:3级文件系统

遇到问题以及实践过程截图
实践截图
man who
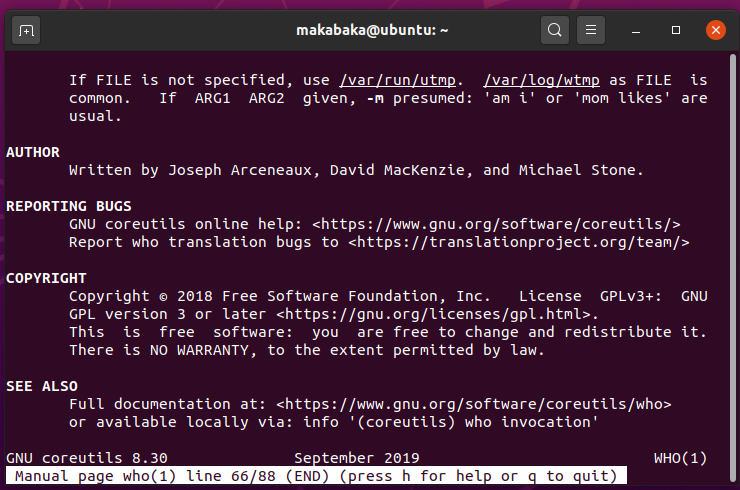
man -k utmp
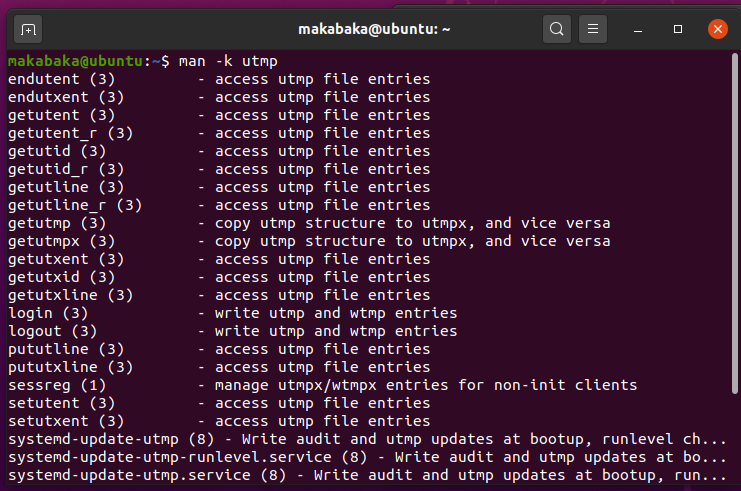
man 2 open
man 2 read

显示其中有几个进程是同时进行的

问题1: