

Python sys模块用法详解
sys 是一个和 Python 解释器关系密切的标准库,它和帮助我们访问和 Python 解释器联系紧密的变量和函数
| sys成员(变量和函数) | 功能描述 |
|---|---|
| sys.argv | 获取运行 Python 程序的命令行参数。其中 sys.argv[0] 通常就是指该 Python 程序,sys.argv[1] 代表为 Python 程序提供的第一个参数,sys.argv[2] 代表为 Python 程序提供的第二个参数……依此类推。 |
| sys.path | 是一个字符串列表,其中每个字符串都是一个目录名,在使用 import 语句导入模块时,解释器就会从这些目录中查找指定的模块。 |
| sys.exit() | 通过引发 SystemExit 异常来退出程序。将其放在 try 块中不能阻止 finally 块的执行。你可以提供一个整数作为参数(默认为 0 ,标识成功),用来标识程序是否成功运行,这是 UNIX 的一个惯例。 |
| sys.modules | 返回模块名和载入模块对应关系的字典。 |
| sys.platform | 此变量是一个字符串,标识解释器当前正在运行的平台名称,它可能是标识操作系统的名称,也可能是标识其他种类的平台,如果运行 Jython 的话,就是 Java 虚拟机。 |
| sys.stdin、sys.stdout、sys.stderr | 这三个模块变量是类文件流对象,分别表示标准输入、标准输出和标准错误。简单理解,Python 利用 sys.stdin 获得输入,利用 sys.stdout 输出。 |
| sys.flags | 该只读属性返回运行 Python 命令时指定的旗标。 |
| sys.getfilesystemencoding() | 返回在当前系统中保存文件所用的字符集。 |
| sys.getrefcount(object) | 返回指定对象的引用计数。前面介绍过,当 object 对象的引用计数为 0 时,系统会回收该对象。 |
| sys.getrecursionlimit() | 返回 Python 解释器当前支持的递归深度。该属性可通过 setrecursionlimit() 方法重新设置。 |
| sys.getswitchinterval() | 返回在当前 Python 解释器中线程切换的时间间隔。该属性可通过 setswitchinterval() 函数改变。 |
| sys.implementation | 返回当前 Python 解释器的实现。 |
| sys.maxsize | 返回 Python 整数支持的最大值。在 32 位平台上,该属性值为 2**31-1;在 64 位平台上,该属性值为 2**63-1。 |
| sys.executable | 该属性返回 Python 解释器在磁盘上的存储路径。 |
| sys.byteorder | 显示本地字节序的指示符。如果本地字节序是大端模式,则该属性返回 big;否则返回 little。 |
| sys.copyright | 该属性返回与 Python 解释器有关的版权信息。 |
| sys.version | 返回当前 Python 解释器的版本信息。 |
| sys.winver | 返回当前 Python 解释器的主版本号。 |
Python os模块及用法
os 模块代表了程序所在的操作系统,主要用于获取程序运行所在操作系统的相关信息。
在 Python 的交互式解释器中先导入 os 模块,然后输入 os.__all__ 命令(__all__ 变量代表了该模块开放的公开接口),即可看到该模块所包含的全部变量和函数。
开发者同样不需要完全记住这些变量和函数的含义,在需要用时可参考https://docs.python.org/3/library/os.html。
| os 成员(变量、函数和类) | 功能描述 |
|---|---|
| os.name | 返回导入依赖模块的操作系统名称,通常可返回 'posix'、'nt'、 'java' 等值其中之一。 |
| os.environ | 返回在当前系统上所有环境变量组成的字典。 |
| os.sep | 返回路径分隔符。 |
| os.fsencode(filename) | 该函数对类路径(path-like)的文件名进行编码。 |
| os.fsdecode(filename) | 该函数对类路径(path-like)的文件名进行解码。 |
| os.PathLike | 这是一个类,代表一个类路径(path-like)对象。 |
| os.getenv(key, default=None) | 获取指定环境变量的值。 |
| os.getlogin() | 返回当前系统的登录用户名。与该函数对应的还有 os.getuid()、os.getgroups()、os.getgid() 等函数,用于获取用户 ID、用户组、组 ID 等,这些函数通常只在 UNIX 系统上有效。 |
| os.getpid() | 获取当前进程 ID。 |
| os.getppid() | 获取当前进程的父进程 ID。 |
| os.putenv(key, value) | 该函数用于设置环境变量。 |
| os.cpu_count() | 返回当前系统的 CPU 数量。 |
| os.pathsep | 返回当前系统上多条路径之间的分隔符。一般在 Windows 系统上多条路径之间的分隔符是英文分号(;);在 UNIX 及类 UNIX 系统(如 Linux、Mac os X)上多条路径之间的分隔符是英文冒号(:)。 |
| os.linesep | 返回当前系统的换行符。一般在 Windows 系统上换行符是“\r\n”:在 UNIX 系统上换行符是“\n”;在 Mac os X 系统上换行符是“\r”。 |
| os.urandom(size) | 返回适合作为加密使用的、最多由 N 个字节组成的 bytes 对象。该函数通过操作系统特定的随机性来源返回随机字节,该随机字节通常是不可预测的,因此适用于绝大部分加密场景。 |
| os进程管理函数 | 功能描述 |
|---|---|
| os.system(command) | 运行操作系统上的指定命令。 |
| os.abort() | 生成一个 SIGABRT 信号给当前进程。在 UNIX 系统上,默认行为是生成内核转储;在 Windows 系统上,进程立即返回退出代码 3。 |
| os.execl(path, arg0, arg1, ...) | 该函数还有一系列功能类似的函数,比如 os.execle()、os.execlp() 等,这些函数都是使用参数列表 arg0, arg1,...来执行 path 所代表的执行文件的。由于 os.exec*() 函数都是 PosIX 系统的直接映射,因此如采使用该命令来执行 Python 程序,传入的 arg0 参数没有什么作用。os._exit(n) 用于强制退出 Python 解释器。将其放在 try 决中可以阻止 finally 块的执行。 |
| os.forkpty() | fork一个子进程。 |
| os.kill(pid, sig) | 将 sig 信号发送到 pid 对应的过程,用于结束该进程。 |
| os.killpg(pgid, sig) | 将 sig 信号发送到 pgid 对应的进程组。 |
| os.popen(cmd, mode='r', buffering=-1) | 用于向 cmd 命令打开读写管道(当 mode 为 r 时为只读管道,当 mode 为 rw 时为读写管道),buffering 缓冲参数与内置的 open() 函数有相同的含义。该函数返回的文件对象用于读写字符串,而不是字节。 |
| os.spawnl(mode, path, ...) | 该函数还有一系列功能类似的函数,比如 os.spawnle()、os.spawnlp() 等,这些函数都用于在新进程中执行新程序。 |
| os.startfile(path[,operation]) | 对指定文件使用该文件关联的工具执行 operation 对应的操作。如果不指定 operation 操作,则默认执行打开(open)操作。operation 参数必须是有效的命令行操作项目,比如 open(打开)、edit(编辑)、print(打印)等。 |
Python random模块及用法
random 模块包括返回随机数的函数,可以用于模拟或者任何产生随机输出的程序。
在 random 模块下提供了表 1 所示的常用函数。
| random模块常用函数 | 功能描述 |
|---|---|
| random.seed(a=None, version=2) | 指定种子来初始化伪随机数生成器。 |
| random.randrange(start, stop[, step]) | 返回从 start 开始到 stop 结束、步长为 step 的随机数。其实就相当于 choice(range(start, stop, step)) 的效果,只不过实际底层并不生成区间对象。 |
| random.randint(a, b) | 生成一个范围为 a≤N≤b 的随机数。其等同于 randrange(a, b+1) 的效果。 |
| random.choice(seq) | 从 seq 中随机抽取一个元素,如果 seq 为空,则引发 IndexError 异常。 |
| random.choices(seq, weights=None, cum_weights=None, k=1) | 从 seq 序列中抽取 k 个元素,还可通过 weights 指定各元素被抽取的权重(代表被抽取的可能性高低)。 |
| random.shuffle(x[, random]) | 对 x 序列执行洗牌“随机排列”操作。 |
| random.sample(population, k) | 从 population 序列中随机抽取 k 个独立的元素。 |
| random.random() | 生成一个从0.0(包含)到 1.0(不包含)之间的伪随机浮点数。 |
| random.uniform(a, b) | 生成一个范围为 a≤N≤b 的随机数。 |
| random.expovariate(lambd) | 生成呈指数分布的随机数。其中 lambd 参数(其实应该是 lambda,只是 lambda 是 Python 关键字,所以简写成 lambd)为 1 除以期望平均值。如果 lambd 是正值,则返回的随机数是从 0 到正无穷大;如果 lambd 为负值,则返回的随机数是从负无穷大到 0。 |
root@kube sys]# cat demo4.py import random #生成范围为0.0≤x<1.0 的伪随机浮点数 print (random.random()) #生成范围为2.5≤x<10.0 的伪随机浮点数 print (random.uniform(2.5, 10.0)) #生成呈指数分布的伪随机浮点数 print (random.expovariate(1/5)) #生成从0 到9 的伪随机整数 print(random.randrange(10)) #生成从0 到100 的随机偶数 print (random.randrange(0, 101 , 2)) #随机抽取一个元素 print (random.choice (['Python','Swift','Kotlin'])) book_list = ['Python','Swift','Kotlin'] #对列表元素进行随机排列 random.shuffle (book_list) print (book_list) #随机抽取4 个独立的元素 print (random.sample([10, 20 , 30 , 40 , 50], k=4)) print (random.randrange(18,32))
#指定随机抽取6 个元素,各元素被抽取的权重(概率)不同
print(random.choices(['Python','Swift','Kotlin'], [5, 5, 1], k=6))
[root@kube sys]#
Python time模块详解
time 模块主要包含各种提供日期、时间功能的类和函数。该模块既提供了把日期、时间格式化为字符串的功能,也提供了从字符串恢复日期、时间的功能。
在 time 模块内提供了一个 time.struct_time 类,该类代表一个时间对象,它主要包含 9 个属性,每个属性的信息如表 1 所示:
| 字段名 | 字段含义 | 值 |
|---|---|---|
| tm_year | 年 | 如 2017、2018 等 |
| tm_mon | 月 | 如 2、3 等,范围为 1~12 |
| tm_mday | 日 | 如 2、3 等,范围为 1~31 |
| tm_hour | 时 | 如 2、3 等,范围为 0~23 |
| tm_min | 分 | 如 2、3 等,范围为 0~59 |
| tm_sec | 秒 | 如 2、3 等,范围为 0~61 |
| tm_wday | 周 | 周一为 0,范围为 0~6 |
| tm_yday | 一年内第几天 | 如 65,范围 1~366 |
| tm_isdst | 夏时令 | 0、1 或 -1 |
注意,秒的范围 0~61 是为了应付闰秒和双闰秒。
在日期、时间模块内常用的功能函数如表 1 所示。
表 1 time模块常用函数 time常用函数 功能描述 time.asctime([t]) 将时间元组或 struct_time 转换为时间字符串。如果不指定参数 t,则默认转换当前时间。 time.ctime([secs]) 将以秒数代表的时间(格林威治时间)转换为时间字符串。 time.gmtime([secs]) 将以秒数代表的时间转换为 struct_time 对象。如果不传入参数,则使用当前时间。 time.localtime([secs]) 将以秒数代表的时间转换为代表当前时间的 struct_time 对象。如果不传入参数,则使用当前时间。 time.mktime(t) 它是 localtime 的反转函数,用于将 struct_time 对象或元组代表的时间转换为从 1970 年 1 月 1 日 0 点整到现在过了多少秒。 time.perf_counter() 返回性能计数器的值。以秒为单位。 time.process_time() 返回当前进程使用 CPU 的时间,以秒为单位。 time.sleep(secs) 暂停 secs 秒,什么都不干。 time.strftime(format[, t]) 将时间元组或 struct_time 对象格式化为指定格式的时间字符串。如果不指定参数 t,则默认转换当前时间。 time.strptime(string[, format]) 将字符串格式的时间解析成 struct_time 对象。 time.time() 返回从 1970 年 1 月 1 日 0 点整到现在过了多少秒。 time.timezone 返回本地时区的时间偏移,以秒为单位。 time.tzname 返回本地时区的名字。 Python 可以用从 1970 年 1 月 1 日 0 点整到现在所经过的秒数来代表当前时间(又称格林威治时间),比如我们写 30 秒,那么意味着时间是 1970 年 1 月 1 日 0 点 0 分 30 秒。但需要注意的是,在实际输出时可能会受到时区的影响,比如中国处于东八区,因此实际上会输出 1970 年 1 月 1 日 8 点 0 分 30 秒。
import time # 将当前时间转换为时间字符串 print(time.asctime()) # 将指定时间转换时间字符串,时间元组的后面3个元素没有设置 print(time.asctime((2018, 2, 4, 11, 8, 23, 0, 0 ,0))) # Mon Feb 4 11:08:23 2018 # 将以秒数为代表的时间转换为时间字符串 print(time.ctime(30)) # Thu Jan 1 08:00:30 1970 # 将以秒数为代表的时间转换为struct_time对象。 print(time.gmtime(30)) # 将当前时间转换为struct_time对象。 print(time.gmtime()) # 将以秒数为代表的时间转换为代表当前时间的struct_time对象 print(time.localtime(30)) # 将元组格式的时间转换为秒数代表的时间 print(time.mktime((2018, 2, 4, 11, 8, 23, 0, 0 ,0))) # 1517713703.0 # 返回性能计数器的值 print(time.perf_counter()) # 返回当前进程使用CPU的时间 print(time.process_time()) #time.sleep(10) # 将当前时间转换为指定格式的字符串 print(time.strftime('%Y-%m-%d %H:%M:%S')) st = '2018年3月20日' # 将指定时间字符串恢复成struct_time对象。 print(time.strptime(st, '%Y年%m月%d日')) # 返回从1970年1970年1月1日0点整到现在过了多少秒。 print(time.time()) # 返回本地时区的时间偏移,以秒为单位 print(time.timezone) # 在国内东八区输出-28800
time 模块中的 strftime() 和 strptime() 两个函数互为逆函数,其中 strftime() 用于将 struct_time 对象或时间元组转换为时间字符串;而 strptime() 函数用于将时间字符串转换为 struct_time 对象。这两个函数都涉及编写格式模板,比如上面程序中使用 %Y 代表年、%m 代表月、%d 代表日、%H 代表时、%M 代表分、%S 代表秒。这两个函数所需要的时间格式字符串支持的指令如表 2 所示:
表 2 Python 时间格式字符串所支持的指令 指令 含义 %a 本地化的星期几的缩写名,比如 Sun 代表星期天 %A 本地化的星期几的完整名 %b 本地化的月份的缩写名,比如 Jan 代表一月 %B 本地化的月份的完整名 %c 本地化的日期和时间的表示形式 %d 代表一个月中第几天的数值,范固: 01~31 %H 代表 24 小时制的小时,范围:00~23 %I 代表 12 小时制的小时,范围:01~12 %j 一年中第几天,范围:001~366 %m 代表月份的数值,范围:01~12 %M 代表分钟的数值,范围:00~59 %p 上午或下午的本地化方式。当使用 strptime() 函数并使用 %I 指令解析小时时,%p 只影响小时字段 %S 代表分钟的数值,范围:00~61。该范围确实是 00~61,60 在表示闰秒的时间戳时有效,而 61 则是由于一些历史原因造成的 %U 代表一年中表示第几周,以星期天为每周的第一天,范围:00~53。在这种方式下,一年中第一个星期天被认为处于第一周。当使用 strptime() 函数解析时间字符串时,只有同时指定了星期几和年份该指令才会有效 %w 代表星期几的数值,范围:0~6,其中 0 代表周日 %W 代表一年小第几周,以星期一为每周的第一天,范围:00~53。在这种方式下,一年中第一个星期一被认为处于第一周。当使用 strptime() 函数解析时间字符串时,只有同时指定了星期几和年份该指令才会有效 %x 本地化的日期的表示形式 %X 本地化的时间的表示形式 %y 年份的缩写,范围:00~99,比如 2018 年就简写成 18 %Y 年份的完整形式。如 2018 %z 显示时区偏移 %Z 时区名(如果时区不行在,则显示为空) %% 用于代表%符号
Python json模块完全攻略
JSON 主要有如下两种数据结构:
- 由 key-value 对组成的数据结构。这种数据结构在不同的语言中有不同的实现。例如,在 JavaScript 中是一个对象;在 Python 中是一种 dict 对象;在 C 语言中是一个 struct;在其他语言中,则可能是 record、dictionary、hash table 等。
- 有序集合。这种数据结构在 Python 中对应于列表;在其他语言中,可能对应于 list、vector、数组和序列等。
上面两种数据结构在不同的语言中都有对应的实现,因此这种简便的数据表示方式完全可以实现跨语言。所以,JSON 可以作为程序设计语言中通用的数据交换格式。
在 JavaScript 中主要有两种 JSON 语法,其中一种用于创建对象,另一种用于创建数组。
object =
{
propertyName1 : propertyValue1,
propertyName2 : propertyValue2,
...
}
必须注意的是,并不是在每个属性定义的后面都有英文逗号,必须当后面还有属性定义时才需要有逗号
Python 的JSON 支持
json 模块提供了对 JSON 的支持,它既包含了将 JSON 字符串恢复成 Python 对象的函数,也提供了将 Python 对象转换成 JSON 字符串的函数。
当程序把 JSON 对象或 JSON 字符串转换成 Python 对象时,从 JSON 类型到 Python 类型的转换关系如表 3 所示:
| JSON 类型 | Python 类型 |
|---|---|
| 对象(object) | 字典(dict) |
| 数组(array) | 列表(list) |
| 字符串(string) | 字符串(str) |
| 整数(number(int)) | 整数(int) |
| 实数(number(real)) | 浮点数(float) |
| true | True |
| false | False |
| null | None |
当程序把 Python 对象转换成 JSON 格式字符串时,从 Python 类型到 JSON 类型的转换关系如表 4 所示:
| Python 类型 | JSON 类型 |
|---|---|
| 字典(dict) | 对象(object) |
| 列表(list)和元组(tuple) | 数组(array) |
| 字符串(str) | 字符串(string) |
| 整型、浮点数,以及整型、浮点型派生的枚举(float,int-& float-derived Enums) | 数值型(number) |
| True | true |
| False | false |
| None | null |
在 Python 的交互式解释器中先导入 json 模块,然后输入 json.all 命令,即可看到该模块所包含的全部属性和函数:
>>> json.__all__
['dump', 'dumps', 'load', 'loads', 'JSONDecoder', 'JSONDecodeError', 'JSONEncoder']
json 模块中常用的函数和类的功能如下:
- json.dump(obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw):将 obj 对象转换成 JSON 字符串输出到 fp 流中,fp 是一个支持 write() 方法的类文件对象。
- json.dumps(obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan= True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw):将 obj 对象转换为 JSON 字符串,并返回该JSON 字符串。
- json.load(fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):从 fp 流读取 JSON 字符串,将其恢复成 JSON 对象,其中 fp 是一个支持 write() 方法的类文件对象。
- json.loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw):将 JSON 字符串 s 恢复成 JSON 对象。
Python re正则表达式模块及其用法
实际上,掌握 Python 的正则表达式并不难,无非就是几个简单的函数。在 Python 的交互式解释器中先导入 re 模块,然后输入 re.__all__ 命令,即可看到该模块所包含的全部属性和函数:
>>> re.__all__
['match', 'fullmatch', 'search', 'sub', 'subn', 'split', 'findall', 'finditer', 'compile', 'purge', 'template', 'escape', 'error', 'A', 'I', 'L', 'M', 'S', 'X', 'U', 'ASCII', 'IGNORECASE', 'LOCALE', 'MULTILINE', 'DOTALL', 'VERBOSE', 'UNICODE']
从上面的输出结果可以看出,re 模块包含了为数不多的几个函数和属性(用于控制正则表达式匹配的几个选项)。下面先介绍这些函数的作用:
- re.compile(pattern, flags=0):该函数用于将正则表达式字符串编译成 _sre.SRE_Pattern 对象,该对象代表了正则表达式编译之后在内存中的对象,它可以缓存并复用正则表达式字符串。如果程序需要多次使用同一个正则表达式字符串,则可考虑先编译它。
该函数的 pattern 参数就是它所编译的正则表达式字符串,flags 则代表了正则表达式的匹配旗标。编译得到的 _sre.SRE_Pattern 对象包含了 re 模块中绝大部分函数对应的方法。比如下面两行代码表示先编译正则表达式,然后调用正则表达式的 search() 方法执行匹配:
re.match(pattern, string, flags=0):尝试从字符串的开始位置来匹配正则表达式,如果从开始位置匹配不成功,match() 函数就返回 None 。其中 pattern 参数代表正则表达式;string 代表被匹配的字符串;flags 则代表正则表达式的匹配旗标。该函数返回 _sre.SRE_Match 对象,该对象包含的 span(n) 方法用于获取第 n+1 个组的匹配位置,group(n) 方法用于获取第 n+1 个组所匹配的子串。 re.search(pattern, string, flags=0):扫描整个字符串,并返回字符串中第一处匹配 pattern 的匹配对象。其中 pattern 参数代表正则表达式;string 代表被匹配的字符串;flags 则代表正则表达式的匹配旗标。该函数也返回 _sre.SRE_Match 对象。 根据上面介绍不难发现,match() 与 search() 的区别在于,match() 必须从字符串开始处就匹配,但 search() 可以搜索整个字符串 re.findall(pattern, string, flags=0):扫描整个字符串,并返回字符串中所有匹配 pattern 的子串组成的列表。其中 pattern 参数代表正则表达式;string 代表被匹配的宇符串;flags 则代表正则表达式的匹配旗标。 re.finditer(pattern, string, flags=0):扫描整个字符串,并返回字符串中所有匹配 pattern 的子串组成的迭代器,迭代器的元素是 _sre.SRE_Match 对象。其中 pattern 参数代表正则表达式;string 代表被匹配的字符串;flags 则代表正则表达式的匹配旗标。
import re m1 = re.match('www', 'www.fkit.org')# 开始位置可以匹配 print(m1.span()) # span返回匹配的位置 print(m1.group()) # group返回匹配的组 print(re.match('fkit', 'www.fkit.com')) # 开始位置匹配不到,返回None m2 = re.search('www', 'www.fkit.org') # 开始位置可以匹配 print(m2.span()) print(m2.group()) m3 = re.search('fkit', 'www.fkit.com') # 中间位置可以匹配,返回Match对象 print(m3.span()) print(m3.group()) # 返回所有匹配pattern的子串组成的列表, 忽略大小写 print(re.findall('fkit', 'FkIt is very good , Fkit.org is my favorite' , re.I)) # 返回所有匹配pattern的子串组成的迭代器, 忽略大小写 it = re.finditer('fkit', 'FkIt is very good , Fkit.org is my favorite' , re.I) for e in it: print(str(e.start()) + "-->" + e.group()) my_date = '2008-08-18' # 将my_date字符串里中画线替换成斜线 print(re.sub(r'-', '/' , my_date)) # 将my_date字符串里中画线替换成斜线,只替换一次 print(re.sub(r'-', '/' , my_date, 1)) # 使用逗号对字符串进行分割 print(re.split(', ', 'fkit, fkjava, crazyit')) # 输出:['fkit', 'fkjava', 'crazyit'] # 指定只分割1次,被切分成2个子串 print(re.split(', ', 'fkit, fkjava, crazyit', 1)) # 输出:['fkit', 'fkjava, crazyit'] # 使用a进行分割 print(re.split('a', 'fkit, fkjava, crazyit')) # 输出:['fkit, fkj', 'va, crazyit'] # 使用x进行分割,没有匹配内容,则不会执行分割 print(re.split('x', 'fkit, fkjava, crazyit')) # 输出:['fkit, fkjava, crazyit'] # 对模式中特殊字符进行转义 print(re.escape(r'www.crazyit.org is good, i love it!')) # 输出:www\.crazyit\.org\ is\ good\,\ i\ love\ it\! print(re.escape(r'A-Zand0-9?')) # 输出:A\-Zand0\-9\?
Python set和frozenset集合操作
et 集合是可变容器,程序可以改变容器中的元素。与 set 对应的还有 frozenset 集合,frozenset 是 set 的不可变版本,它的元素是不可变的。
Python set集合
set 集合有如下两个特征:
- set 不记录元素的添加顺序。
- 元素不允许重复。
# 使用花括号构建set集合 c = {'白骨精'} # 添加元素 c.add("孙悟空") c.add(6) print("c集合的元素个数为:" , len(c)) # 输出3 # 删除指定元素 c.remove(6) print("c集合的元素个数为:" , len(c)) # 输出2 # 判断是否包含指定字符串 print("c集合是否包含'孙悟空'字符串:" , ("孙悟空" in c)) # 输出True c.add("轻量级Java EE企业应用实战") print("c集合的元素:" , c) # 使用set()函数(构造器)来创建set集合 books = set() books.add("轻量级Java EE企业应用实战") books.add("疯狂Java讲义") print("books集合的元素:" , books) # issubset()方法判断是否为子集合 print("books集合是否为c的子集合?", books.issubset(c)) # 输出False # issubset()方法与<=运算符效果相同 print("books集合是否为c的子集合?", (books <= c)) # 输出False # issuperset()方法判断是否为父集合 # issubset和issuperset其实就是倒过来判断 print("c集合是否完全包含books集合?", c.issuperset(books)) # 输出False # issuperset()方法与>=运算符效果相同 print("c集合是否完全包含books集合?", (c >= books)) # 输出False # 用c集合减去books集合里的元素,不改变c集合本身 result1 = c - books print(result1) # difference()方法也是对集合做减法,与用-执行运算的效果完全一样 result2 = c.difference(books) print(result2) # 用c集合减去books集合里的元素,改变c集合本身 c.difference_update(books) print("c集合的元素:" , c) # 删除c集合里的所有元素 c.clear() print("c集合的元素:" , c) # 直接创建包含元素的集合 d = {"疯狂Java讲义", '疯狂Python讲义', '疯狂Kotlin讲义'} print("d集合的元素:" , d) # 计算两个集合的交集,不改变d集合本身 inter1 = d & books print(inter1) # intersection()方法也是获取两个集合的交集,与用&执行运算的效果完全一样 inter2 = d.intersection(books) print(inter2) # 计算两个集合的交集,改变d集合本身 d.intersection_update(books) print("d集合的元素:" , d) # 将range对象包装成set集合 e = set(range(5)) f = set(range(3, 7)) print("e集合的元素:" , e) print("f集合的元素:" , f) # 对两个集合执行异或运算 xor = e ^ f print('e和f执行xor的结果:', xor) # 计算两个集合的并集,不改变e集合本身 un = e.union(f) print('e和f执行并集的结果:', un) # 计算两个集合的并集,改变e集合本身 e.update(f) print('e集合的元素:', e)
上面程序基本示范了 set 集合中所有方法的用法。不仅如此,该程序还示范了 set 集合支持的如下几个运算符: <=:相当于调用 issubset() 方法,判断前面的 set 集合是否为后面的 set 集合的子集合。 >=:相当于调用 issuperset() 方法,判断前面的 set 集合是否为后面的 set 集合的父集合。 -:相当于调用 difference() 方法,用前面的 set 集合减去后面的 set 集合的元素。 &:相当于调用 intersection() 方法,用于获取两个 set 集舍的交集。 ^:计算两个集合异或的结果,就是用两个集合的并集减去交集的元素。 此外,由于 set 集合本身是可变的,因此它除了提供 add()、remove()、discard() 方法来操作单个元素,还支持进行集合运算来改变集合内的元素。因此,它的集合运算方法都有两个版本: 交集运算:intersection() 和 intersection_update(),前者不改变集合本身,而是返回两个集合的交集;后者会通过交集运算改变第一个集合。 并集运算:union() 和 update(),前者不改变集合本身,而是返回两个集合的并集;后者会通过并集运算改变第一个集合。 减法运算:difference() 和 difference_update(),前者不改变集合本身,而是返回两个集合做咸法的结果;后者改变第一个集合。
Python frozenset集合
frozenset 是 set 的不可变版本,因此 set 集合中所有能改变集合本身的方法(如 add、remove、discard、xxx_update 等),frozenset 都不支持;set 集合中不改变集合本身的方法,fronzenset 都支持。
在交互式解释器中输入 [e for e in dir(frozenset) if not e.startswith('_')] 命令来查看 frozenset 集合的全部方法,
很明显,frozenset 的这些方法和 set 集合的同名方法的功能完全相同。
frozenset 的作用主要有两点:
- 当集合元素不需要改变时,使用 frozenset 代替 set 更安全。
- 当某些 API 需要不可变对象时,必须用 frozenset 代替set。比如 dict 的 key 必须是不可变对象,因此只能用 frozenset;再比如 set 本身的集合元素必须是不可变的,因此 set 不能包含 set,set 只能包含 frozenset。
[root@kube sys]# cat demo8.py s = set() frozen_s = frozenset('Kotlin') # 为set集合添加frozenset s.add(frozen_s) print('s集合的元素:', s) sub_s = {'Python'} # 为set集合添加普通set集合,程序报错 s.add(sub_s) #set 不能包含set [root@kube sys]# py demo8.py s集合的元素: {frozenset({'i', 'l', 'o', 'n', 't', 'K'})} Traceback (most recent call last): File "demo8.py", line 8, in <module> s.add(sub_s) TypeError: unhashable type: 'set' [root@kube sys]# #上面程序中第 4 行代码为 set 添加 frozenset,程序完全没有问题,这样 set 中就包括一个 frozenset 子集合;第 8 行代码试图向 set 中添加普通 set,程序会报出 TypeError 异常。
Python queue(双端队列)模块及用法
在“数据结构”课程中最常讲授的数据结构有栈、队列、双端队列。
栈是一种特殊的线性表,它只允许在一端进行插入、删除操作,这一端被称为栈顶(top),另一端则被称为栈底(bottom)。
从栈顶插入一个元素被称为进栈,将一个元素插入栈顶被称为“压入栈”,对应的英文说法为 push;相应地,从栈顶删除一个元素被称为出栈,将一个元素从栈顶删除被称为“弹出栈”,对应的英文说法为 pop。
对于栈而言,最先入栈的元素位于栈底,只有等到上面所有元素都出栈之后,栈底的元素才能出栈。因此栈是一种后进先出(LIFO)的线性表。如图 1 所示为栈的操作示意图。
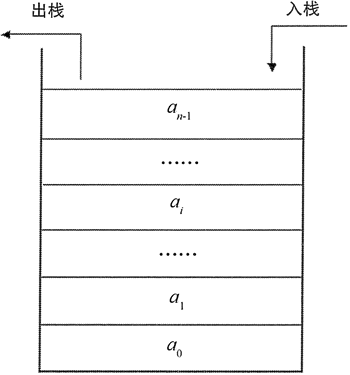
图 1 栈的操作示意图
队列也是一种特殊的线性表,它只允许在表的前端(front)进行删除操作,在表的后端(rear)进行插入操作。进行插入操作的端被称为队尾,进行删除操作的端被称为队头。
对于一个队列来说,每个元素总是从队列的 rear 端进入队列的,然后等待该元素之前的所有元素都出队之后,当前元素才能出队。因此,队列是一种先进先出(FIFO)的线性表。队列示意图如图 2 所示。

图 2 队列示意图
双端队列(即此处介绍的 deque)代表一种特殊的队列,它可以在两端同时进行插入、删除操作,如图 3 所示。
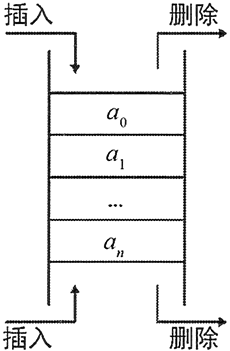
图 3 双端队列示意图
对于一个双端队列来说,它可以从两端分别进行插入、删除操作,如果程序将所有的插入、删除操作都固定在一端进行,那么这个双端队列就变成了栈;如果固定在一端只添加元素,在另一端只删除元素,那么它就变成了队列。因此,deque 既可被当成队列使用,也可被当成栈使用。
deque 位于 collections 包下,在交互式解释器中先导入 collections 包,然后输入 [e for e in dir(collections.deque) if not e.startswith('_')] 命令来查看 deque 的全部方法,可以看到如下输出结果:
deque 位于 collections 包下,在交互式解释器中先导入 collections 包,然后输入 [e for e in dir(collections.deque) if not e.startswith('_')] 命令来查看 deque 的全部方法,可以看到如下输出结果:
>>> from collections import deque
>>> [e for e in dir(deque) if not e.startswith('_')]
['append', 'appendleft', 'clear', 'copy', 'count', 'extend', 'extendleft', 'index', 'insert', 'maxlen', 'pop', 'popleft', 'remove', 'reverse', 'rotate']
从上面的方法可以看出,deque 的方法基本都有两个版本,这就体现了它作为双端队列的特征。deque 的左边(left)就相当于它的队列头(front),右边(right)就相当于它的队列尾(rear):
- append 和 appendleft:在 deque 的右边或左边添加元素,也就是默认在队列尾添加元素。
- pop 和 popleft:在 deque 的右边或左边弹出元素,也就是默认在队列尾弹出元素。
- extend 和 extendleft:在 deque 的右边或左边添加多个元素,也就是默认在队列尾添加多个元素。
deque 中的 clear() 方法用于清空队列:insert() 方法则是线性表的方法,用于在指定位置插入元素。
假如程序要把 deque 当成栈使用,则意味着只在一端添加、删除元素,因此调用 append 和 pop 方法即可。例如如下程序:
from collections import deque stack = deque(('Kotlin', 'Python')) # 元素入栈 stack.append('Erlang') stack.append('Swift') print('stack中的元素:' , stack) # 元素出栈,后添加的元素先出栈 print(stack.pop()) print(stack.pop()) print(stack) 运行上面程序,可以看到如下运行结果: stack中的元素: deque(['Kotlin', 'Python', 'Erlang', 'Swift']) Swift Erlang deque(['Kotlin', 'Python'])
从上面的运行结果可以看出,程序最后入栈的元素“Swift”最先出栈,这体现了栈的 LIFO 的特征。
假如程序要把 deque 当成队列使用,则意味着一端只用来添加元素,另一端只用来删除元素,因此调用 append、popleft 方法即可。例如如下程序:
from collections import deque q = deque(('Kotlin', 'Python')) # 元素加入队列 q.append('Erlang') q.append('Swift') print('q中的元素:' , q) # 元素出队列,先添加的元素先出队列 print(q.popleft()) print(q.popleft()) print(q)
从上面的运行结果可以看出,程序先添加的元素“Katlin”最先出队列,这体现了队列的 FIFO 的特征。
此外,deque 还有一个 rotate() 方法,该方法的作用是将队列的队尾元素移动到队头,使之首尾相连。例如如下程序:
from collections import deque q = deque(range(5)) print('q中的元素:' , q) # 执行旋转,使之首尾相连 q.rotate() print('q中的元素:' , q) # 再次执行旋转,使之首尾相连 q.rotate() print('q中的元素:' , q) 运行上面程序,可以看到如下输出结果: q中的元素: deque([0, 1, 2, 3, 4]) q中的元素: deque([4, 0, 1, 2, 3]) q中的元素: deque([3, 4, 0, 1, 2]) 从上面的输出结果来看,每次执行 rotate() 方法,deque 的队尾元素都会被移到队头,这样就形成了首尾相连的效果。
Python ChainMap用法
ChainMap 是一个方便的工具类,它使用链的方式将多个 dict“链”在一起,从而允许程序可直接获取任意一个 dict 所包含的 key 对应的 value。
简单来说,ChainMap 相当于把多个 dict 合并成一个大的 dict,但实际上底层并未真正合并这些 dict,因此程序无须调用多个 update() 方法将多个 dict 进行合并。所以说 ChainMap 是一种合并,但实际用起来又具有较好的效果。
需要说明的是,由于 ChainMap 只是将多个 dict 链在一起,并未真正合并它们,因此在多个 dict 中完全可能具有重复的 key,在这种情况下,排在“链”前面的 dict 中的 key 具有更高的优先级。
例如,下面程序示范了 ChainMap 的用法:
[root@kube import]# cat demo11.py from collections import ChainMap # 定义3个dict对象 a = {'Kotlin': 90, 'Python': 86} b = {'Go': 93, 'Python': 92} c = {'Swift': 89, 'Go': 87} # 将3个dict对象链在一起,就像变成了一个大的dict cm = ChainMap(a, b , c) print(cm) # 获取Kotlin对应的value print(cm['Kotlin']) # 90 # 获取Python对应的value print(cm['Python']) # 86 # 获取Go对应的value print(cm['Go']) # 93
上面程序 a、b、c 三个 dict 链在一起,组成一个 ChainMap,这个链的顺序就是 a、b、c,因此 a 的优先级最高,b 的优先级次之,c 的优先级最低。运行上面程序,可以看到如下输出结果:
[root@kube import]# py demo11.py ChainMap({'Kotlin': 90, 'Python': 86}, {'Go': 93, 'Python': 92}, {'Swift': 89, 'Go': 87}) 90 86 93 [root@kube import]#
Python Counter类用法完全攻略
collections 包下的 Counter 也是一个很有用的工具类,它可以自动统计容器中各元素出现的次数。
Counter 的本质就是一个特殊的 dict,只不过它的 key 都是其所包含的元素,而它的 value 则记录了该 key 出现的次数。因此,如果通过 Counter 并不存在的 key 访问 value,将会输出 0(代表该 key 出现了 0 次)。
程序可通过任何可法代对象参数来创建 Counter 对象,此时 Counter 将会自动统计各元素出现的次数,并以元素为 key,出现的次数为 value 来构建 Counter 对象;程序也能以 dict 为参数来构建 Counter 对象;还能通过关键字参数来构建 Counter 对象。例如如下程序:
[root@kube import]# cat demo12.py from collections import Counter # 创建空的Counter对象 c1 = Counter() # 以可迭代对象创建Counter对象 c2 = Counter('hannah') print(c2) # 以可迭代对象创建Counter对象 c3 = Counter(['Python', 'Swift', 'Swift', 'Python', 'Kotlin', 'Python']) print(c3) # 以dict来创建Counter对象 c4 = Counter({'red': 4, 'blue': 2}) print(c4) # 使用关键字参数的语法创建Counter c5 = Counter(Python=4, Swift=8) print(c5) [root@kube import]# py demo12.py Counter({'h': 2, 'a': 2, 'n': 2}) Counter({'Python': 3, 'Swift': 2, 'Kotlin': 1}) Counter({'red': 4, 'blue': 2}) Counter({'Swift': 8, 'Python': 4}) [root@kube import]#
事实上,Counter 继承了 dict 类,因此它完全可以调用 dict 所支持的方法。此外,Counter 还提供了如下三个常用的方法:
- elements():该方法返回该 Counter 所包含的全部元素组成的迭代器。
- most_common([n]):该方法返回 Counter 中出现最多的 n 个元素。
- subtract([iterable-or-mapping]):该方法计算 Counter 的减法,其实就是计算减去之后各元素出现的次数。
Python defaultdict用法(带实例分析)
defaultdict 是 dict 的子类,因此 defaultdict 也可被当成 dict 来使用,dict 支持的功能,defaultdict 基本都支持。但它与 dict 最大的区别在于,如果程序试图根据不存在的 key 采访问 dict 中对应的 value,则会引发 KeyError 异常;而 defaultdict 则可以提供一个 default_factory 属性,该属性所指定的函数负责为不存在的 key 来生成 value。
[root@kube import]# cat demo13.py from collections import defaultdict my_dict = {} # 使用int作为defaultdict的default_factory # 将key不存在时,将会返回int()函数的返回值 my_defaultdict = defaultdict(int) print(my_defaultdict['a']) # 0 print(my_dict['a']) # KeyError [root@kube import]# py demo13.py 0 Traceback (most recent call last): File "demo13.py", line 7, in <module> print(my_dict['a']) # KeyError KeyError: 'a' [root@kube import]#
Python namedtuple工厂函数功能及用法
namedtuple() 是一个工厂函数,使用该函数可以创建一个 tuple 类的子类,该子类可以为 tuple 的每个元素都指定宇段名,这样程序就可以根据字段名来访问 namedtuple 的各元素了。当然,如果有需要,程序依然可以根据索引来访问 namedtuple 的各元素。
namedtuple 是轻量级的,性能很好,其并不比普通 tuple 需要更多的内存。namedtuple 函数的语法格式如下:
namedtuple(typename, field_names, *, verbose=False, rename=False, module=None)
关于该函数参数的说明如下;
- typename:该参数指定所创建的 tuple 子类的类名,相当于用户定义了一个新类。
- field_names:该参数是一个字符串序列,如 ['x','y']。此外,field_names 也可直接使用单个字符串代表所有字段名,多个字段名用空格、逗号隔开,如 'x y' 或 'x,y'。任何有效的 Python 标识符都可作为字段名(不能以下画线开头)。有效的标识符可由字母、数字、下画线组成,但不能以数字、下面线开头,也不能是关键字(如 return、global、pass、raise 等)。
- rename:如果将该参数设为 True,那么无效的字段名将会被自动替换为位置名。例如指定 ['abc','def','ghi','abc'],它将会被替换为 ['abc', '_1','ghi','_3'],这是因为 def 字段名是关键字,而 abc 字段名重复了。
- verbose:如果该参数被设为 True,那么当该子类被创建之后,该类定义就会被立即打印出来。
- module:如果设置了该参数,那么该类将位于该模块下,因此该自定义类的 __module__ 属性将被设为该参数值。
下面程序示范了使用 namedtuple 工厂函数来创建命名元组:
from collections import namedtuple # 定义命名元组类:Point Point = namedtuple('Point', ['x', 'y']) # 初始化Point对象,即可用位置参数,也可用命名参数 p = Point(11, y=22) # 像普通元组一样用根据索引访问元素 print(p[0] + p[1]) # 33 # 执行元组解包,按元素的位置解包 a, b = p print(a, b) # 11, 22 # 根据字段名访问各元素 print(p.x + p.y) # 33 print(p) # Point(x=11, y=22)
Python OrderedDict用法详解
OrderedDict 也是 dict 的子类,其最大特征是,它可以“维护”添加 key-value 对的顺序。简单来说,就是先添加的 key-value 对排在前面,后添加的 key-value 对排在后面。
由于 OrderedDict 能维护 key-value 对的添加顺序,因此即使两个 OrderedDict 中的 key-value 对完全相同,但只要它们的顺序不同,程序在判断它们是否相等时也依然会返回 false。
[root@kube import]# cat demo14.py from collections import OrderedDict # 创建OrderedDict对象 dx = OrderedDict(b=5, c=2, a=7) print(dx) # OrderedDict([('b', 5), ('c', 2), ('a', 7)]) d = OrderedDict() # 向OrderedDict中添加key-value对 d['Python'] = 89 d['Swift'] = 92 d['Kotlin'] = 97 d['Go'] = 87 # 遍历OrderedDict的key-value对 for k,v in d.items(): print(k, v) [root@kube import]# py demo14.py OrderedDict([('b', 5), ('c', 2), ('a', 7)]) Python 89 Swift 92 Kotlin 97 Go 87 [root@kube import]#
Python itertools模块:生成迭代器(实例分析)
itertools 模块中主要包含了一些用于生成迭代器的函数。在 Python 的交互式解释器中先导入 itertools 模块,然后输入 [e for e in dir(itertools) if not e.startswith('_')] 命令,即可看到该模块所包含的全部属性和函数:
>>> [e for e in dir(itertools) if not e.startswith('_')] ['accumulate', 'chain', 'combinations', 'combinations_with_replacement', 'compress', 'count', 'cycle', 'dropwhile', 'filterfalse', 'groupby', 'islice', 'permutations', 'product', 'repeat', 'starmap', 'takewhile', 'tee', 'zip_longest']
从上面的输出结果可以看出,itertools 模块中的不少函数都可以用于生成迭代器。
先看 itertools 模块中三个生成无限迭代器的函数:
- count(start, [step]):生成 start, start+step, start+2*step,... 的迭代器,其中 step 默认为 1。比如使用 count(10) 生成的迭代器包含:10, 11 , 12 , 13, 14,...。
- cycle(p):对序列 p 生成无限循环 p0, p1,..., p0, p1,... 的迭代器。比如使用 cycle('ABCD') 生成的迭代器包含:A,B,C,D,A,B,C,D,...。
- repeat(elem [,n]):生成无限个 elem 元素重复的迭代器,如果指定了参数 n,则只生成 n 个 elem 元素。比如使用 repeat(10, 3) 生成的法代器包含:10, 10, 10。
下面程序示范了使用上面三个函数来生成迭代器:
import itertools as it # count(10, 3)生成10、13、16……迭代器 for e in it.count(10, 3): print(e) # 用于跳出无限循环 if e > 20: break print('---------') my_counter = 0 # cycle用于对序列生成无限循环的迭代器 for e in it.cycle(['Python', 'Kotlin', 'Swift']): print(e) # 用于跳出无限循环 my_counter += 1 if my_counter > 7: break print('---------') # repeat用于生成n个元素重复的迭代器 for e in it.repeat('Python', 3): print(e)
在 itertools 模块中还有一些常用的迭代器函数,如下所示:
- accumulate(p[,func]):默认生成根据序列 p 元素累加的迭代器,p0, p0+p1, p0+p1+p2,...序列,如果指定了 func 函数,则用 func 函数来计算下一个元素的值。
- chain(p, q, ...):将多个序列里的元素“链”在一起生成新的序列。
- compress(data, selectors):根据 selectors 序列的值对 data 序列的元素进行过滤。如果 selector[0] 为真,则保留 data[0];如果 selector[1] 为真,则保留 data[1]......依此类推。
- dropwhile(pred, seq):使用 pred 函数对 seq 序列进行过滤,从 seq 中第一个使用 pred 函数计算为 False 的元素开始,保留从该元素到序列结束的全部元素。
- takewhile(pred, seq):该函数和上一个函数恰好相反。使用 pred 函数对 seq 序列进行过滤,从 seq 中第一个使用 pred 函数计算为 False 的元素开始,去掉从该元素到序列结束的全部元素。
- filterfalse(pred, seq):使用 pred 函数对 seq 序列进行过滤,保留 seq 中使用 pred 计算为 True 的元素。比如
filterfalse(lambda x:x%2, range(10)),得到 0, 2, 4, 6, 8。 - islice(seq, [start,] stop [, step]):其功能类似于序列的 slice 方法,实际上就是返回
seq[start:stop:step]的结果。 - starmap(func, seq):使用 func 对 seq 序列的每个元素进行计算,将计算结果作为新的序列元素。当使用 func 计算序列元素时,支持序列解包。比如 seq 序列的元素长度为 3,那么 func 可以是一个接收三个参数的函数,该函数将会根据这三个参数来计算新序列的元素。
- zip_longest(p,q,...):将 p、q 等序列中的元素按索引合并成元组,这些元组将作为新序列的元素。
上面这些函数的测试程序如下:
import itertools as it # 默认使用累加的方式计算下一个元素的值 for e in it.accumulate(range(6)): print(e, end=', ') # 0, 1, 3, 6, 10, 15 print('\n---------') # 使用x*y的方式来计算迭代器下一个元素的值 for e in it.accumulate(range(1, 6), lambda x, y: x * y): print(e, end=', ') # 1, 2, 6, 24, 120 print('\n---------') # 将两个序列“链”在一起,生成新的迭代器 for e in it.chain(['a', 'b'], ['Kotlin', 'Swift']): print(e, end=', ') # 'a', 'b', 'Kotlin', 'Swift' print('\n---------') # 根据第二个序列来筛选第一个序列的元素, # 由于第二个序列只有中间两个元素为1(True),因此前一个序列只保留中间两个元素 for e in it.compress(['a', 'b', 'Kotlin', 'Swift'], [0, 1, 1, 0]): print(e, end=', ') # 只有: 'b', 'Kotlin' print('\n---------') # 获取序列中从长度不小于4的元素开始、到结束的所有元素 for e in it.dropwhile(lambda x:len(x)<4, ['a', 'b', 'Kotlin', 'x', 'y']): print(e, end=', ') # 只有: 'Kotlin', 'x', 'y' print('\n---------') # 去掉序列中从长度不小于4的元素开始、到结束的所有元素 for e in it.takewhile(lambda x:len(x)<4, ['a', 'b', 'Kotlin', 'x', 'y']): print(e, end=', ') # 只有: 'a', 'b' print('\n---------') # 只保留序列中从长度不小于4的元素 for e in it.filterfalse(lambda x:len(x)<4, ['a', 'b', 'Kotlin', 'x', 'y']): print(e, end=', ') # 只有: 'Kotlin' print('\n---------') # 使用pow函数对原序列的元素进行计算,将计算结果作为新序列的元素 for e in it.starmap(pow, [(2,5), (3,2), (10,3)]): print(e, end=', ') # 32, 9, 1000 print('\n---------') # 将'ABCD'、'xy'的元素按索引合并成元组,这些元组作为新序列的元素 # 长度不够的序列元素使用'-'字符代替 for e in it.zip_longest('ABCD', 'xy', fillvalue='-'): print(e, end=', ') # ('A', 'x'), ('B', 'y'), ('C', '-'), ('D', '-')
Python functools模块完全攻略
functools 模块中主要包含了一些函数装饰器和便捷的功能函数。在 Python 的交互式解释器中先导入 functools 模块,然后输入 [e for e in dir(functools) if not e.startswith('_')] 命令,即可看到该模块所包含的全部属性和函数:
>>> [e for e in dir(functools) if not e.startswith('_')] ['MappingProxyType', 'RLock', 'WRAPPER_ASSIGNMENTS', 'WRAPPER_UPDATES', 'WeakKeyDictionary', 'cmp_to_key', 'get_cache_token', 'lru_cache', 'namedtuple', 'partial', 'partialmethod', 'recursive_repr', 'reduce', 'singledispatch', 'total_ordering', 'update_wrapper', 'wraps']
在functools 模块中常用的函数装饰器和功能函数如下:
- functools.cmp_to_key(func):将老式的比较函数(func)转换为关键字函数(key function)。在 Python 3 中比较大小、排序都是基于关键字函数的,Python 3 不支持老式的比较函数。
- @functools.lru_cache(maxsize=128, typed=False):该函数装饰器使用 LRU(最近最少使用)缓存算法来缓存相对耗时的函数结果,避免传入相同的参数重复计算。同时,缓存并不会无限增长,不用的缓存会被释放。其中 maxsize 参数用于设置缓存占用的最大字节数,typed 参数用于设置将不同类型的缓存结果分开存放。
- @functools.total_ordering:这个类装饰器(作用类似于函数装饰器,只是它用于修饰类)用于为类自动生成比较方法。通常来说,开发者只要提供 __lt__()、__le__()、__gt__()、__ge__() 其中之一(最好能提供 __eq__() 方法),@functools.total_ordering装饰器就会为该类生成剩下的比较方法。
- functools.partial(func, *args, **keywords):该函数用于为 func 函数的部分参数指定参数值,从而得到一个转换后的函数,程序以后调用转换后的函数时,就可以少传入那些己指定值的参数。
- functools.partialmethod(func, *args, **keywords):该函数与上一个函数的含义完全相同,只不过该函数用于为类中的方法设置参数值。
- functools.reduce(function, iterable[, initializer]):将初始值(默认为 0,可由 initializer 参数指定)、迭代器的当前元素传入 function 函数,将计算出来的函数结果作为下一次计算的初始值、迭代器的下一个元素再次调用 function 函数……依此类推,直到迭代器的最后一个元素。
- @functools.singledispatch:该函数装饰器用于实现函数对多个类型进行重载。比如同样的函数名称,为不同的参数类型提供不同的功能实现。该函数的本质就是根据参数类型的变换,将函数转向调用不同的函数。
- functools.update_wrapper(wrapper, wrapped, assigned=WRAPPER_ASSIGNMENTS, updated=WRAPPER_UPDATES):对 wrapper 函数进行包装,使之看上去就像 wrapped(被包装)函数。
- @functools.wraps(wrapped, assigned=WRAPPER_ASSIGNMENTS, updated=WRAPPER_UPDATES):该函数装饰器用于修饰包装函数,使包装函数看上去就像 wrapped 函数。
通过介绍不难发现,functools.update_wrapper 和 @functools.wraps 的功能是一样的,只不过前者是函数,因此需要把包装函数作为第一个参数传入;而后者是函数装饰器,因此使用该函数装饰器修饰包装函数即可,无须将包装函数作为第一个参数传入。
下面程序示范了 functiontools 棋块中部分函数或函数装饰器的用法:
from functools import * # 以初始值(默认为0)为x,以当前序列元素为y,x+y的和作为下一次的初始值 print(reduce(lambda x,y: x + y, range(5))) # 10 print(reduce(lambda x,y: x + y, range(6))) # 15 # 设初始值为10 print(reduce(lambda x,y: x + y, range(6), 10)) # 25 print('----------------') class User: def __init__(self, name): self.name = name def __repr__(self): return 'User[name=%s' % self.name # 定义一个老式的大小比较函数,User的name越长,该User越大 def old_cmp(u1 , u2): return len(u1.name) - len(u2.name) my_data = [User('Kotlin'), User('Swift'), User('Go'), User('Java')] # 对my_data排序,需要关键字参数(调用cmp_to_key将old_cmp转换为关键字参数 my_data.sort(key=cmp_to_key(old_cmp)) print(my_data) print('----------------') @lru_cache(maxsize=32) def factorial(n): print('~~计算%d的阶乘~~' % n) if n == 1: return 1 else: return n * factorial(n - 1) # 只有这行会计算,然后会缓存5、4、3、2、1的解乘 print(factorial(5)) print(factorial(3)) print(factorial(5)) print('----------------') # int函数默认将10进制的字符串转换为整数 print(int('12345')) # 为int函数的base参数指定参数值 basetwo = partial(int, base=2) basetwo.__doc__ = '将二进制的字符串转换成整数' # 相当于执行base为2的int()函数 print(basetwo('10010')) print(int('10010', 2))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号