
来自: https://www.jianshu.com/p/acb34a1d1b6e
Kubenernetes 调度器介绍
Kubernetes 调度器介绍
kube-scheduler是 kubernetes 系统的核心组件之一,主要负责整个集群资源的调度功能,根据特定的调度算法和策略,将 Pod 调度到最优的工作节点上面去,从而更加合理、更加充分的利用集群的资源,这也是我们选择使用 kubernetes 一个非常重要的理由。如果一门新的技术不能帮助企业节约成本、提供效率,我相信是很难推进的。
调度流程
默认情况下,kube-scheduler 提供的默认调度器能够满足我们绝大多数的要求,我们前面和大家接触的示例也基本上用的默认的策略,都可以保证我们的 Pod 可以被分配到资源充足的节点上运行。但是在实际的线上项目中,可能我们自己会比 kubernetes 更加了解我们自己的应用,比如我们希望一个 Pod 只能运行在特定的几个节点上,或者这几个节点只能用来运行特定类型的应用,这就需要我们的调度器能够可控。
kube-scheduler 是 kubernetes 的调度器,它的主要作用就是根据特定的调度算法和调度策略将 Pod 调度到合适的 Node 节点上去,是一个独立的二进制程序,启动之后会一直监听 API Server,获取到 PodSpec.NodeName 为空的 Pod,对每个 Pod 都会创建一个 binding。
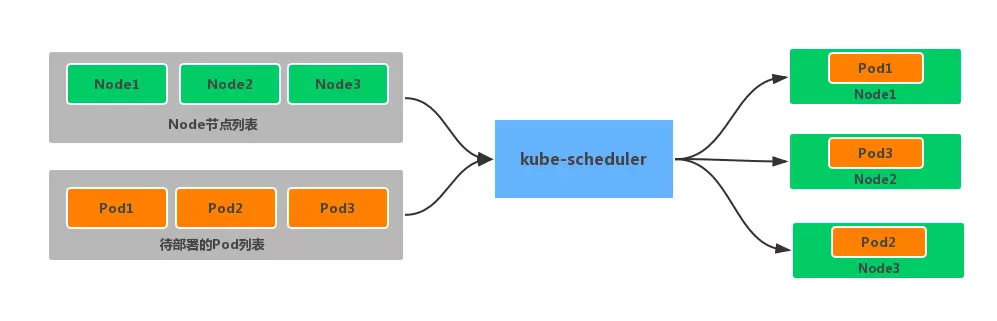

这个过程在我们看来好像比较简单,但在实际的生产环境中,需要考虑的问题就有很多了:
- 如何保证全部的节点调度的公平性?要知道并不是说有节点资源配置都是一样的
- 如何保证每个节点都能被分配资源?
- 集群资源如何能够被高效利用?
- 集群资源如何才能被最大化使用?
- 如何保证 Pod 调度的性能和效率?
- 用户是否可以根据自己的实际需求定制自己的调度策略?
考虑到实际环境中的各种复杂情况,kubernetes 的调度器采用插件化的形式实现,可以方便用户进行定制或者二次开发,我们可以自定义一个调度器并以插件形式和 kubernetes 进行集成。
kubernetes 调度器的源码位于 kubernetes/pkg/scheduler 中,大体的代码目录结构如下所示:(不同的版本目录结构可能不太一样)
kubernetes/pkg/scheduler
-- scheduler.go //调度相关的具体实现
|-- algorithm
| |-- predicates //节点筛选策略
| |-- priorities //节点打分策略
|-- algorithmprovider
| |-- defaults //定义默认的调度器
其中 Scheduler 创建和运行的核心程序,对应的代码在 pkg/scheduler/scheduler.go,如果要查看kube-scheduler的入口程序,对应的代码在 cmd/kube-scheduler/scheduler.go。
调度主要分为以下几个部分:
- 首先是预选过程,过滤掉不满足条件的节点,这个过程称为
Predicates - 然后是优选过程,对通过的节点按照优先级排序,称之为
Priorities - 最后从中选择优先级最高的节点,如果中间任何一步骤有错误,就直接返回错误
Predicates阶段首先遍历全部节点,过滤掉不满足条件的节点,属于强制性规则,这一阶段输出的所有满足要求的 Node 将被记录并作为第二阶段的输入,如果所有的节点都不满足条件,那么 Pod 将会一直处于 Pending 状态,直到有节点满足条件,在这期间调度器会不断的重试。
所以我们在部署应用的时候,如果发现有 Pod 一直处于 Pending 状态,那么就是没有满足调度条件的节点,这个时候可以去检查下节点资源是否可用。
Priorities阶段即再次对节点进行筛选,如果有多个节点都满足条件的话,那么系统会按照节点的优先级(priorites)大小对节点进行排序,最后选择优先级最高的节点来部署 Pod 应用。
下面是调度过程的简单示意图:


更详细的流程是这样的:
- 首先,客户端通过 API Server 的 REST API 或者 kubectl 工具创建 Pod 资源
- API Server 收到用户请求后,存储相关数据到 etcd 数据库中
- 调度器监听 API Server 查看为调度(bind)的 Pod 列表,循环遍历地为每个 Pod 尝试分配节点,这个分配过程就是我们上面提到的两个阶段:
- 预选阶段(Predicates),过滤节点,调度器用一组规则过滤掉不符合要求的 Node 节点,比如 Pod 设置了资源的 request,那么可用资源比 Pod 需要的资源少的主机显然就会被过滤掉
- 优选阶段(Priorities),为节点的优先级打分,将上一阶段过滤出来的 Node 列表进行打分,调度器会考虑一些整体的优化策略,比如把 Deployment 控制的多个 Pod 副本分布到不同的主机上,使用最低负载的主机等等策略
- 经过上面的阶段过滤后选择打分最高的 Node 节点和 Pod 进行 binding 操作,然后将结果存储到 etcd 中
- 最后被选择出来的 Node 节点对应的 kubelet 去执行创建 Pod 的相关操作
其中Predicates过滤有一系列的算法可以使用,我们这里简单列举几个:
- PodFitsResources:节点上剩余的资源是否大于 Pod 请求的资源
- PodFitsHost:如果 Pod 指定了 NodeName,检查节点名称是否和 NodeName 匹配
- PodFitsHostPorts:节点上已经使用的 port 是否和 Pod 申请的 port 冲突
- PodSelectorMatches:过滤掉和 Pod 指定的 label 不匹配的节点
- NoDiskConflict:已经 mount 的 volume 和 Pod 指定的 volume 不冲突,除非它们都是只读的
- CheckNodeDiskPressure:检查节点磁盘空间是否符合要求
- CheckNodeMemoryPressure:检查节点内存是否够用
除了这些过滤算法之外,还有一些其他的算法,更多更详细的我们可以查看源码文件:k8s.io/kubernetes/pkg/scheduler/algorithm/predicates/predicates.go。
而Priorities优先级是由一系列键值对组成的,键是该优先级的名称,值是它的权重值,同样,我们这里给大家列举几个具有代表性的选项:
- LeastRequestedPriority:通过计算 CPU 和内存的使用率来决定权重,使用率越低权重越高,当然正常肯定也是资源是使用率越低权重越高,能给别的 Pod 运行的可能性就越大
- SelectorSpreadPriority:为了更好的高可用,对同属于一个 Deployment 或者 RC 下面的多个 Pod 副本,尽量调度到多个不同的节点上,当一个 Pod 被调度的时候,会先去查找该 Pod 对应的 controller,然后查看该 controller 下面的已存在的 Pod,运行 Pod 越少的节点权重越高
- ImageLocalityPriority:就是如果在某个节点上已经有要使用的镜像节点了,镜像总大小值越大,权重就越高
- NodeAffinityPriority:这个就是根据节点的亲和性来计算一个权重值,后面我们会详细讲解亲和性的使用方法
除了这些策略之外,还有很多其他的策略,同样我们可以查看源码文件:k8s.io/kubernetes/pkg/scheduler/algorithm/priorities/ 了解更多信息。每一个优先级函数会返回一个0-10的分数,分数越高表示节点越优,同时每一个函数也会对应一个表示权重的值。最终主机的得分用以下公式计算得出:
finalScoreNode = (weight1 * priorityFunc1) + (weight2 * priorityFunc2) + … + (weightn * priorityFuncn)
自定义调度
上面就是 kube-scheduler 默认调度的基本流程,除了使用默认的调度器之外,我们也可以自定义调度策略。
调度器扩展
kube-scheduler在启动的时候可以通过 --policy-config-file参数来指定调度策略文件,我们可以根据我们自己的需要来组装Predicates和Priority函数。选择不同的过滤函数和优先级函数、控制优先级函数的权重、调整过滤函数的顺序都会影响调度过程。
下面是官方的 Policy 文件示例:
{
"kind" : "Policy",
"apiVersion" : "v1",
"predicates" : [
{"name" : "PodFitsHostPorts"},
{"name" : "PodFitsResources"},
{"name" : "NoDiskConflict"},
{"name" : "NoVolumeZoneConflict"},
{"name" : "MatchNodeSelector"},
{"name" : "HostName"}
],
"priorities" : [
{"name" : "LeastRequestedPriority", "weight" : 1},
{"name" : "BalancedResourceAllocation", "weight" : 1},
{"name" : "ServiceSpreadingPriority", "weight" : 1},
{"name" : "EqualPriority", "weight" : 1}
]
}
多调度器
如果默认的调度器不满足要求,还可以部署自定义的调度器。并且,在整个集群中还可以同时运行多个调度器实例,通过 podSpec.schedulerName 来选择使用哪一个调度器(默认使用内置的调度器)。
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
schedulerName: my-scheduler # 选择使用自定义调度器 my-scheduler
containers:
- name: nginx
image: nginx:1.10
要开发我们自己的调度器也是比较容易的,比如我们这里的 my-scheduler:
- 首先需要通过指定的 API 获取节点和 Pod
- 然后选择
phase=Pending和schedulerName=my-scheduler的pod - 计算每个 Pod 需要放置的位置之后,调度程序将创建一个
Binding对象 - 然后根据我们自定义的调度器的算法计算出最适合的目标节点
优先级调度
与前面所讲的调度优选策略中的优先级(Priorities)不同,前面所讲的优先级指的是节点优先级,而我们这里所说的优先级 pod priority 指的是 Pod 的优先级,高优先级的 Pod 会优先被调度,或者在资源不足低情况牺牲低优先级的 Pod,以便于重要的 Pod 能够得到资源部署。
要定义 Pod 优先级,就需要先定义PriorityClass对象,该对象没有 Namespace 的限制:
apiVersion: v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for XYZ service pods only."
其中:
value为 32 位整数的优先级,该值越大,优先级越高globalDefault用于未配置 PriorityClassName 的 Pod,整个集群中应该只有一个PriorityClass将其设置为 true
然后通过在 Pod 的spec.priorityClassName中指定已定义的PriorityClass名称即可:
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
另外一个值得注意的是当节点没有足够的资源供调度器调度 Pod,导致 Pod 处于 pending 时,抢占(preemption)逻辑就会被触发。Preemption会尝试从一个节点删除低优先级的 Pod,从而释放资源使高优先级的 Pod 得到节点资源进行部署。
现在我们通过下面的图再去回顾下 kubernetes 的调度过程是不是就清晰很多了:

常用的预选机制
调度器: 预选策略:(一部分) CheckNodeCondition:#检查节点是否正常(如ip,磁盘等) GeneralPredicates HostName:#检查Pod对象是否定义了pod.spec.hostname PodFitsHostPorts:#pod要能适配node的端口 pods.spec.containers.ports.hostPort(指定绑定在节点的端口上) MatchNodeSelector:#检查节点的NodeSelector的标签 pods.spec.nodeSelector PodFitsResources:#检查Pod的资源需求是否能被节点所满足 NoDiskConflict: #检查Pod依赖的存储卷是否能满足需求(默认未使用) PodToleratesNodeTaints:#检查Pod上的spec.tolerations可容忍的污点是否完全包含节点上的污点; PodToleratesNodeNoExecuteTaints:#不能执行(NoExecute)的污点(默认未使用) CheckNodeLabelPresence:#检查指定的标签再上节点是否存在 CheckServiceAffinity:#将相同services相同的pod尽量放在一起(默认未使用) MaxEBSVolumeCount: #检查EBS(AWS存储)存储卷的最大数量 MaxGCEPDVolumeCount #GCE存储最大数 MaxAzureDiskVolumeCount: #AzureDisk 存储最大数 CheckVolumeBinding: #检查节点上已绑定或未绑定的pvc NoVolumeZoneConflict: #检查存储卷对象与pod是否存在冲突 CheckNodeMemoryPressure:#检查节点内存是否存在压力过大 CheckNodePIDPressure: #检查节点上的PID数量是否过大 CheckNodeDiskPressure: #检查内存、磁盘IO是否过大 MatchInterPodAffinity: #检查节点是否能满足pod的亲和性或反亲和性
常用的优选函数
LeastRequested:#空闲量越高得分越高 (cpu((capacity-sum(requested))*10/capacity)+memory((capacity-sum(requested))*10/capacity))/2 BalancedResourceAllocation:#CPU和内存资源被占用率相近的胜出; NodePreferAvoidPods: #节点注解信息“scheduler.alpha.kubernetes.io/preferAvoidPods” TaintToleration:#将Pod对象的spec.tolerations列表项与节点的taints列表项进行匹配度检查,匹配条目越,得分越低; SeletorSpreading:#标签选择器分散度,(与当前pod对象通选的标签,所选其它pod越多的得分越低) InterPodAffinity:#遍历pod对象的亲和性匹配项目,项目越多得分越高 NodeAffinity: #节点亲和性 、 MostRequested: #空闲量越小得分越高,和LeastRequested相反 (默认未启用) NodeLabel: #节点是否存在对应的标签 (默认未启用) ImageLocality:#根据满足当前Pod对象需求的已有镜像的体积大小之和(默认未启用)
高级调度设置方式
来自: https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
1、nodeSelector选择器
[root@kube ip_sh]# kubectl get nodes --show-labels // 查看标签,使用nodeSelector选择器,选择disk=ssd的node NAME STATUS ROLES AGE VERSION LABELS kube.master Ready master 62d v1.15.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube.master,kubernetes.io/os=linux,node-role.kubernetes.io/master= kube.node1 Ready <none> 62d v1.15.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube.node1,kubernetes.io/os=linux kube.node2 Ready <none> 62d v1.15.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube.node2,kubernetes.io/os=linux [root@kube ip_sh]#
[root@k8s-m schedule]# cat my-pod.yaml apiVersion: v1 kind: Pod metadata: name: nginx-pod labels: app: my-pod spec: containers: - name: my-pod image: nginx ports: - name: http containerPort: 80 nodeSelector: disk: ssd #如果nodeSelector中指定的标签节点都没有,该pod就会处于Pending状态(预选失败) [root@kube scheduler]# kubectl get pods NAME READY STATUS RESTARTS AGE dns-test 1/1 Running 0 10d myapp-deploy-6b8c5ff84f-65pqt 0/1 CrashLoopBackOff 272 23h myapp-deploy-6b8c5ff84f-zqkx5 0/1 CrashLoopBackOff 260 23h nginx-pod 0/1 Pending 0 7s //预选失败 web-0 1/1 Running 0 10d web-1 1/1 Running 0 10d web-2 1/1 Running 0 10d [root@kube scheduler]#
节点亲和力和反亲和力
nodeSelector提供了一种非常简单的方法来将pod限制为具有特定标签的节点。亲和力/反亲和力特征极大地扩展了您可以表达的约束类型。关键的改进是 语言更具表现力(不仅仅是“精确匹配”) 你可以指出规则是“软”/“偏好”而不是硬性要求,所以如果调度程序不能满足它,那么仍然会安排pod 您可以限制在节点(或其他拓扑域)上运行的其他pod上的标签,而不是针对节点本身上的标签,这允许有关哪些pod可以和不可以位于同一位置的规则 亲和特征由两种类型的亲和力组成,“节点亲和力”和“节点间亲和力/反亲和力”。节点亲和力就像现有的nodeSelector(但具有上面列出的前两个好处),而pod间亲和/反亲和力限制pod标签而不是节点标签,如上面列出的第三个项目中所述,除了拥有第一个和上面列出的第二个属性。
2、affinity
2.1、nodeAffinity的preferredDuringSchedulingIgnoredDuringExecution (软亲和,选择条件匹配多的,就算都不满足条件,还是会生成pod)
测试前先为节点打上标签
[root@kube ~]# kubectl label nodes kube.node1 name=node1 node/kube.node1 labeled [root@kube ~]# kubectl get node --show-labels NAME STATUS ROLES AGE VERSION LABELS kube.master Ready master 63d v1.15.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube.master,kubernetes.io/os=linux,node-role.kubernetes.io/master= kube.node1 Ready <none> 62d v1.15.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube.node1,kubernetes.io/os=linux,name=node1 kube.node2 Ready <none> 63d v1.15.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=kube.node2,kubernetes.io/os=linux [root@kube ~]#
[root@kube affinity]# cat aff1.yaml apiVersion: v1 kind: Pod metadata: name: affinity-pod labels: app: my-pod spec: containers: - name: affinity-pod image: busybox affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: #软亲和性 - preference: matchExpressions: - key: name //定义 key 值 operator: In values: - node1 //定义 value 值 - test1 weight: 60 [root@kube affinity]#
2.2、requiredDuringSchedulingIgnoredDuringExecution (硬亲和,类似nodeSelector,硬性需求,如果不满足条件不会调度pod,都不满足则Pending)
[root@kube affinity]# cat req-aff.yaml apiVersion: v1 kind: Pod metadata: name: req-affinity labels: app: my-pod spec: containers: - name: affinity-pod image: busybox affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: //强制标签匹配 nodeSelectorTerms: - matchExpressions: - key: name operator: In values: - node2 - test1 //查看(没有node2这个标签,所以会Pending) [root@kube affinity]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES myapp-deploy-6b8c5ff84f-cqv8z 0/1 CrashLoopBackOff 5 5m55s 10.244.1.38 kube.node2 <none> <none> myapp-deploy-6b8c5ff84f-qhzvz 0/1 CrashLoopBackOff 4 5m55s 10.244.2.67 kube.node1 <none> <none> req-affinity 0/1 Pending 0 42s <none> <none> <none> <none> web-0 1/1 Running 0 5m39s 10.244.1.39 kube.node2 <none> <none> web-1 1/1 Running 0 5m1s 10.244.2.68 kube.node1 <none> <none> web-2 1/1 Running 0 3m44s 10.244.1.40 kube.node2 <none> <none> [root@kube affinity]#
pod的亲和与反亲和性
1、podAffinity:(让pod和某个pod处于同一地方(同一地方不一定指同一node节点,根据个人使用的标签定义))
[root@kube affinity]# cat pod-affinity.yaml apiVersion: v1 kind: Pod metadata: name: my-aff labels: app1: my-aff spec: containers: - name: my-pod1 image: nginx ports: - name: http containerPort: 80 --- apiVersion: v1 kind: Pod metadata: name: affinity-pod-test labels: app: my-pod spec: containers: - name: affinity-pod image: nginx ports: - name: http containerPort: 80 affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: //通过标签选择想在一起的 pod matchExpressions: - key: app1 #标签键名,上面pod定义 operator: In #In表示在 values: - my-aff #app1标签的值 topologyKey: kubernetes.io/hostname [root@kube affinity]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES affinity-pod-test 1/1 Running 0 43s 10.244.2.70 kube.node1 <none> <none> my-aff 1/1 Running 0 93s 10.244.2.69 kube.node1 <none> <none> myapp-deploy-6b8c5ff84f-cqv8z 0/1 CrashLoopBackOff 8 19m 10.244.1.38 kube.node2 <none> <none> myapp-deploy-6b8c5ff84f-qhzvz 0/1 CrashLoopBackOff 7 19m 10.244.2.67 kube.node1 <none> <none> req-affinity 0/1 Completed 7 14m 10.244.1.41 kube.node2 <none> <none> web-0 1/1 Running 0 19m 10.244.1.39 kube.node2 <none> <none> web-1 1/1 Running 0 18m 10.244.2.68 kube.node1 <none> <none> web-2 1/1 Running 0 17m 10.244.1.40 kube.node2 <none> <none> [root@kube affinity]#
2、podAntiAffinity(让pod和某个pod不处于同一node,和上面相反)
[root@kube affinity]# cat pod-aff.yaml apiVersion: v1 kind: Pod metadata: name: my-pod1 labels: app1: my-pod1 spec: containers: - name: my-pod1 image: nginx ports: - name: http containerPort: 80 --- apiVersion: v1 kind: Pod metadata: name: affinity-pod labels: app: my-pod spec: containers: - name: affinity-pod image: nginx ports: - name: http containerPort: 80 affinity: podAntiAffinity: #就改了这里 requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app1 #标签键名,上面pod定义 operator: In #In表示在 values: - my-pod1 #app1标签的值 topologyKey: kubernetes.io/hostname #kubernetes.io/hostname的值一样代表pod不处于同一位置 [root@kube affinity]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES affinity-pod 1/1 Running 0 79s 10.244.2.71 kube.node1 <none> <none> affinity-pod-test 1/1 Running 0 8m28s 10.244.2.70 kube.node1 <none> <none> my-aff 1/1 Running 0 9m18s 10.244.2.69 kube.node1 <none> <none> my-pod1 1/1 Running 0 79s 10.244.1.42 kube.node2 <none> <none> myapp-deploy-6b8c5ff84f-cqv8z 0/1 CrashLoopBackOff 9 27m 10.244.1.38 kube.node2 <none> <none> myapp-deploy-6b8c5ff84f-qhzvz 0/1 CrashLoopBackOff 9 27m 10.244.2.67 kube.node1 <none> <none> req-affinity 0/1 CrashLoopBackOff 8 22m 10.244.1.41 kube.node2 <none> <none> web-0 1/1 Running 0 27m 10.244.1.39 kube.node2 <none> <none> web-1 1/1 Running 0 26m 10.244.2.68 kube.node1 <none> <none> web-2 1/1 Running 0 25m 10.244.1.40 kube.node2 <none> <none> [root@kube affinity]#
七、污点调度
taint的effect定义对Pod排斥效果:
NoSchedule:#仅影响调度过程,对现存的Pod对象不产生影响;
NoExecute:#既影响调度过程,也影响现在的Pod对象;不容忍的Pod对象将被驱逐;
PreferNoSchedule: #当没合适地方运行pod了,也会找地方运行pod
1、查看并管理污点
[root@kube affinity]# kubectl describe node kube.node1 |grep Taint //查看污点 Taints: <none> [root@kube affinity]# kubectl describe node kube.node2 |grep Taint Taints: <none> [root@kube affinity]# kubectl taint nodes kube.node1 key=value:NoSchedule //打上污点 node/kube.node1 tainted [root@kube affinity]# kubectl taint nodes kube.node2 key=value:NoSchedule node/kube.node2 tainted [root@kube affinity]# kubectl taint nodes kube.node2 key:NoSchedule- //删除污点 node/kube.node2 untainted [root@kube affinity]# kubectl taint nodes kube.node1 key:NoSchedule- node/kube.node1 untainted [root@kube affinity]#
[root@kube affinity]# cat taint-pod.yaml apiVersion: v1 kind: Pod metadata: name: my-taint labels: app1: my-taint spec: containers: - name: my-t image: nginx ports: - name: http containerPort: 80 [root@kube affinity]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES affinity-pod 1/1 Running 0 15m 10.244.2.71 kube.node1 <none> <none> affinity-pod-test 1/1 Running 0 23m 10.244.2.70 kube.node1 <none> <none> my-aff 1/1 Running 0 23m 10.244.2.69 kube.node1 <none> <none> my-pod1 1/1 Running 0 15m 10.244.1.42 kube.node2 <none> <none> my-taint 0/1 Pending 0 99s <none> <none> <none> <none> req-affinity 0/1 CrashLoopBackOff 11 36m 10.244.1.41 kube.node2 <none> <none> web-0 1/1 Running 0 41m 10.244.1.39 kube.node2 <none> <none> web-1 1/1 Running 0 41m 10.244.2.68 kube.node1 <none> <none> web-2 1/1 Running 0 39m 10.244.1.40 kube.node2 <none> <none> [root@kube affinity]# kubectl describe pods my-taint |tail -l //提前给两个 node 打上了污点 SecretName: default-token-bsthb Optional: false QoS Class: BestEffort Node-Selectors: <none> Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s node.kubernetes.io/unreachable:NoExecute for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 25s (x2 over 101s) default-scheduler 0/3 nodes are available: 3 node(s) had taints that the pod didn't tolerate. //三个节点都不允许调度 [root@kube affinity]#
容忍污点
[root@kube affinity]# cat taint-allow.yaml apiVersion: v1 kind: Pod metadata: name: nginx-pod labels: app: my-pod spec: containers: - name: my-pod image: nginx ports: - name: http containerPort: 80 tolerations: #容忍的污点 - key: "key" #之前定义的污点名 operator: "Equal" #Exists,如果key污点在,就能容忍,Equal精确 value: "value" #污点值 effect: "NoSchedule" #效果 [root@kube affinity]# [root@kube affinity]# [root@kube affinity]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES affinity-pod 1/1 Running 0 21m 10.244.2.71 kube.node1 <none> <none> affinity-pod-test 1/1 Running 0 28m 10.244.2.70 kube.node1 <none> <none> my-aff 1/1 Running 0 29m 10.244.2.69 kube.node1 <none> <none> my-pod1 1/1 Running 0 21m 10.244.1.42 kube.node2 <none> <none> my-taint 0/1 Pending 0 7m9s <none> <none> <none> <none> nginx-pod 0/1 ContainerCreating 0 20s <none> kube.node1 <none> <none> req-affinity 0/1 CrashLoopBackOff 12 42m 10.244.1.41 kube.node2 <none> <none> web-0 1/1 Running 0 47m 10.244.1.39 kube.node2 <none> <none> web-1 1/1 Running 0 46m 10.244.2.68 kube.node1 <none> <none> web-2 1/1 Running 0 45m 10.244.1.40 kube.node2 <none> <none> [root@kube affinity]#
官方文档: https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/ 污点和容忍
https://kubernetes.io/docs/concepts/configuration/assign-pod-node/ 调度策略
还参考了: https://www.cnblogs.com/zhangb8042/p/10203266.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号