Deep Layer Aggregation论文笔记
概述
之前的组会中孙文宇学长分享了CenterNet,李普学长分享了FPN,DLA起到了承上启下的作用。
这篇顶会论文由UC Berkeley研究员Fisher Yu所在团队提出并发表:
1、 是将现今的网络结构由具像总结至抽象
2、 提出两种抽象的网络架构:Stage之间使用iterative layer aggregation,Stage内使用Hierarchical layer aggregation。我把他们称为迭代聚合以及层次聚合,
两个模型类似SENet,容易扩展在已有网络结构中。

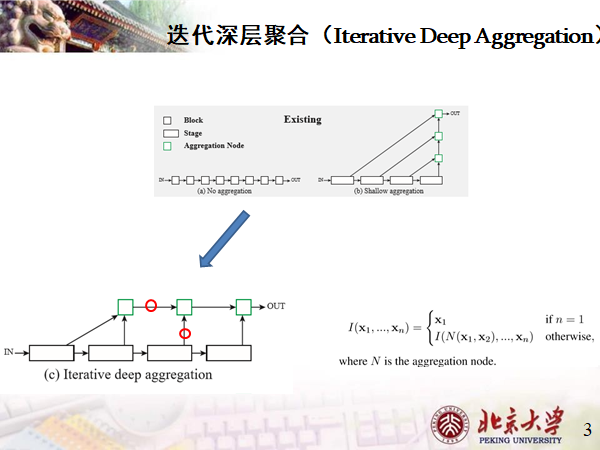
迭代深层聚合
深层阶段的语义信息很丰富但是空间上比较粗糙。将低层阶段通过跳跃连接到高层阶段来融合尺寸和分辨率。但现有的跳跃连接都是线性的,例如U-Net。
个人理解的迭代:上采样后的Stage与前一聚合节点融合后,迭代成为新的聚合节点。
优点
1、融合分辨率和尺寸
2、避免最浅层的部分会对最终结果产生最深远影响
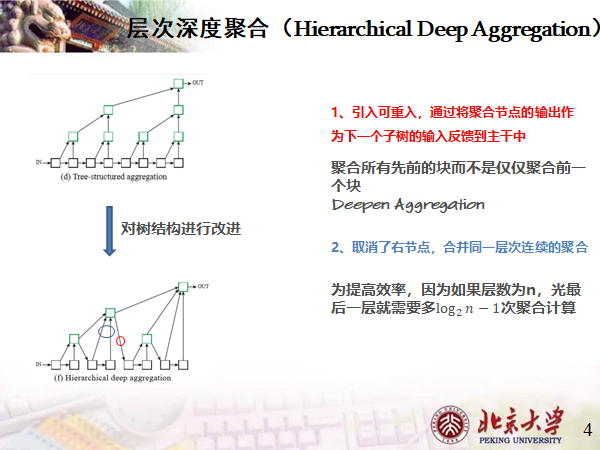
分层深度聚合
论文对原始的树结构进行改进,我们来找不同
首先是
1 引入可重入,将聚合节点的输出作为下一个子树的输入反馈到主干中;
2 取消了右节点,合并同一层次连续的聚合,个人觉得它是为了层次的多样性,例如将高度为0层、1层、2层相融合,而不是两个高度为2层的进行融合。
HDA将较浅和较深的层组合起来,以学习更丰富的、跨越层次的组合特征,同时也提高了效率。
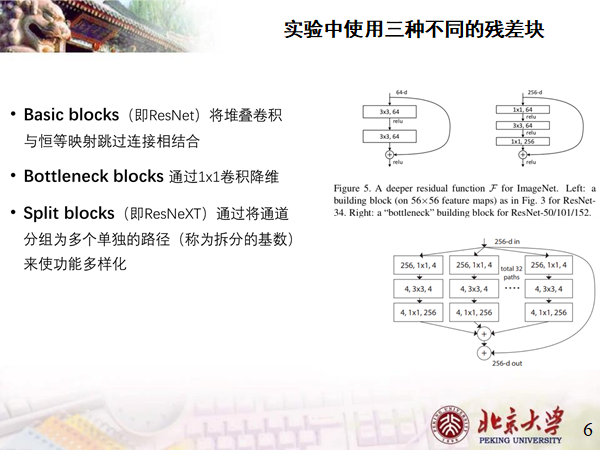
残差块
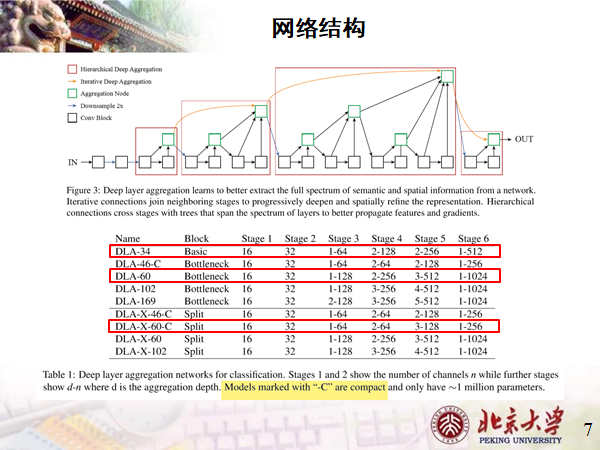
网络结构
选取三个具有代表性的:
-34采用Basic残差块,它也是CenterNet的BackBone;
-60 采用Bottleneck残差块,它的结构刚好对应下图所示结构;
-X-60 采用Split残差块,其中-C代表该模型小巧,参数只有1百万左右。
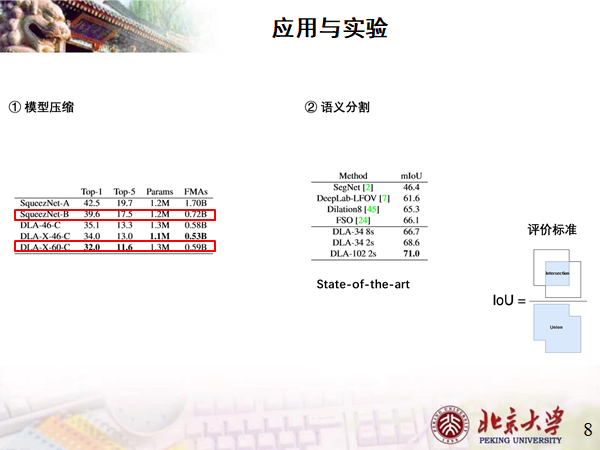
实验效果
1、模型压缩,DLA与SqueezeNet在ImageNet2012上的训练模型结果:
可以看到在参数几乎持平的情况下,Top1错误率下降了7个点。
2、语义分割,评价标准为交并比,数值越大表示越精确;
文章中说自己State of the art ,业界最强