



re正则表达式初识
re正则表达式:
导入方法:import re
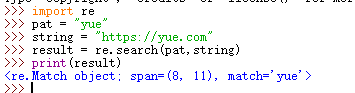
example:
import re
pat = "yue"
string = "https://yue.com"
result = re.search(pat,string)
print(result)
通用字符也可以作为原子:
\w:可以匹配任意的字母,数字和下划线。
\d:匹配任意一个十进制数。
\s:可以匹配任意一个空白字符。
\W:可以匹配除字母,数字,下划线以外的任意一个字符、
例:
pat = "\w\dpython\w"
string = "jkldghfjgkhl"
rs = re.search(pat,string)
print(rs)

分析:string中的字符串不符合pat中的规则,所以最后不能匹配成功,最终结果为None.
若:
pat = "\w\dpython\w"
string = "jhjh7pythonkjlkj"
rs = re.search(pat,string)
print(rs)

分析:string中字符串符合pat中规则,最终能提取成功,最终提取的结果为:h7pythonk
若:
pat = "pyth[jsz]n"
string = "jkgkjhpythsnssff"
rs = re.search(pat,string)
print(rs)
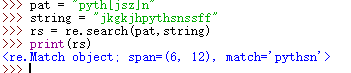
分析:string中字符串符合pat中规则,最终能提取成功,最终提取的结果为:pythsn
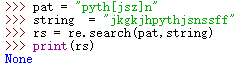
但若string中字符为:jkgkjhpythjsnssff,则不能匹配成功,因为pat中[]表示中间只有一位字符,若是有多位字符,则匹配不成功
元字符:
所谓元字符,就是正则表达式中具有特殊含义的字符,比如重复N次前面的字符等。
.:能匹配任意的字符
^:能匹配字符串的开始位置
$:匹配字符串中结束的位置
*:匹配0次,1次或多次字符
?:能匹配0次或者一次字符,适用于懒惰模式
+:匹配一次或多次前面的原子
{n}:代表大括号前面的原子出现n次
{n,}:代表括号前面的原子至少出现了n次
{n,m}:代表括号 前面的原子至少出现了n次,至多出现了m次
|(模式选择符或):t|s,表示t或者s
():表示模式单元,用于提取某个内容上
例:

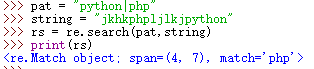
模式修正符:
所谓模式修正符,即可以在不改变正则表达式的情况下,通过模式修正符 改变正则表达式的意义,从而实现一些匹配结果的调整等功能。
I:因为正则表达式区分大小写,若要不区分大小写,可使用大写的I模式修正符修正
M:可以进行多行匹配
L:本地化识别 匹配
U:根据unicode字符解析字符
S:让.号匹配包括换行符
例:
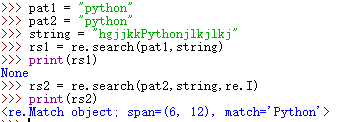
分析:在此例中,若不使用模式修正符I,正则表达式中将区分大小写,所以rs1中匹配为空,而使用模式修正符I后,将不再区分匹配的大小写,所以rs2能匹配成功。
贪婪模式与懒惰模式 :
贪婪模式的核心点就是尽可能多的匹配,而懒惰模式的核心点则是尽可能少的匹配
例:
1:贪婪模式:

分析,贪婪模式尽可能多的覆盖,不能实现精确定位
2:懒惰模式
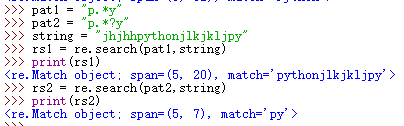
分析:懒惰模式可实现精确定位
re正则表达式函数:
正则表达式 函数有re.match()函数,re.search()函数,全局匹配函数,re.sub()函数
re.match():从头开始匹配,若开始的第一个字符与要匹配的字符串的第一个字符不同,则匹配为空

re.search:从字符串中去搜索对应的字符
全局匹配函数:re.compile(pat).findall(string)

