卷积和滤波器的关系 / 为什么2D卷积的卷积单元是3D的
Filters and Convolutions#
Excerpt from Focal Loss#
Classification Subnet:
The classification subnet predicts the probability of object presence at each spatial position for each of the A anchors and K object classes. This subnet is a small FCN attached to each FPN level; parameters of this subnet are shared across all pyramid levels.
Its design is simple. Taking an input feature map with
We use
Filters and Convs#
如果我说 3x3 conv,并且输入图像有
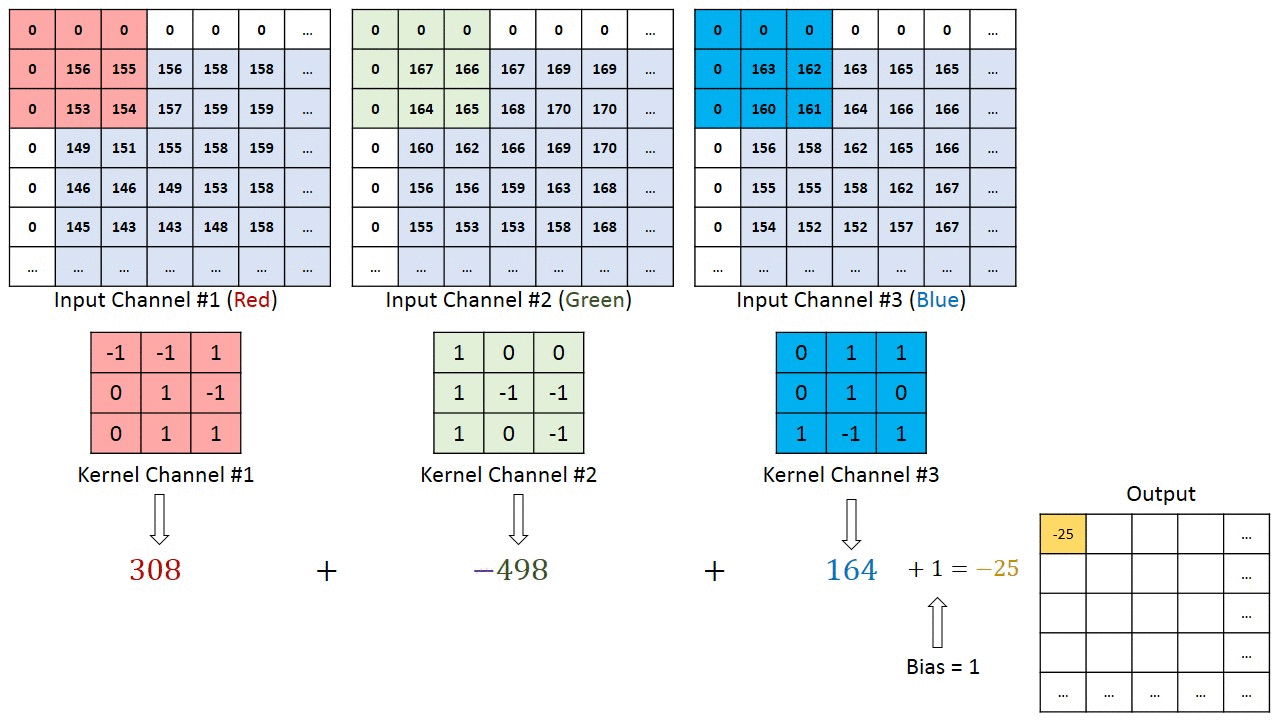
- 总共需要有
- 每个卷积单元有
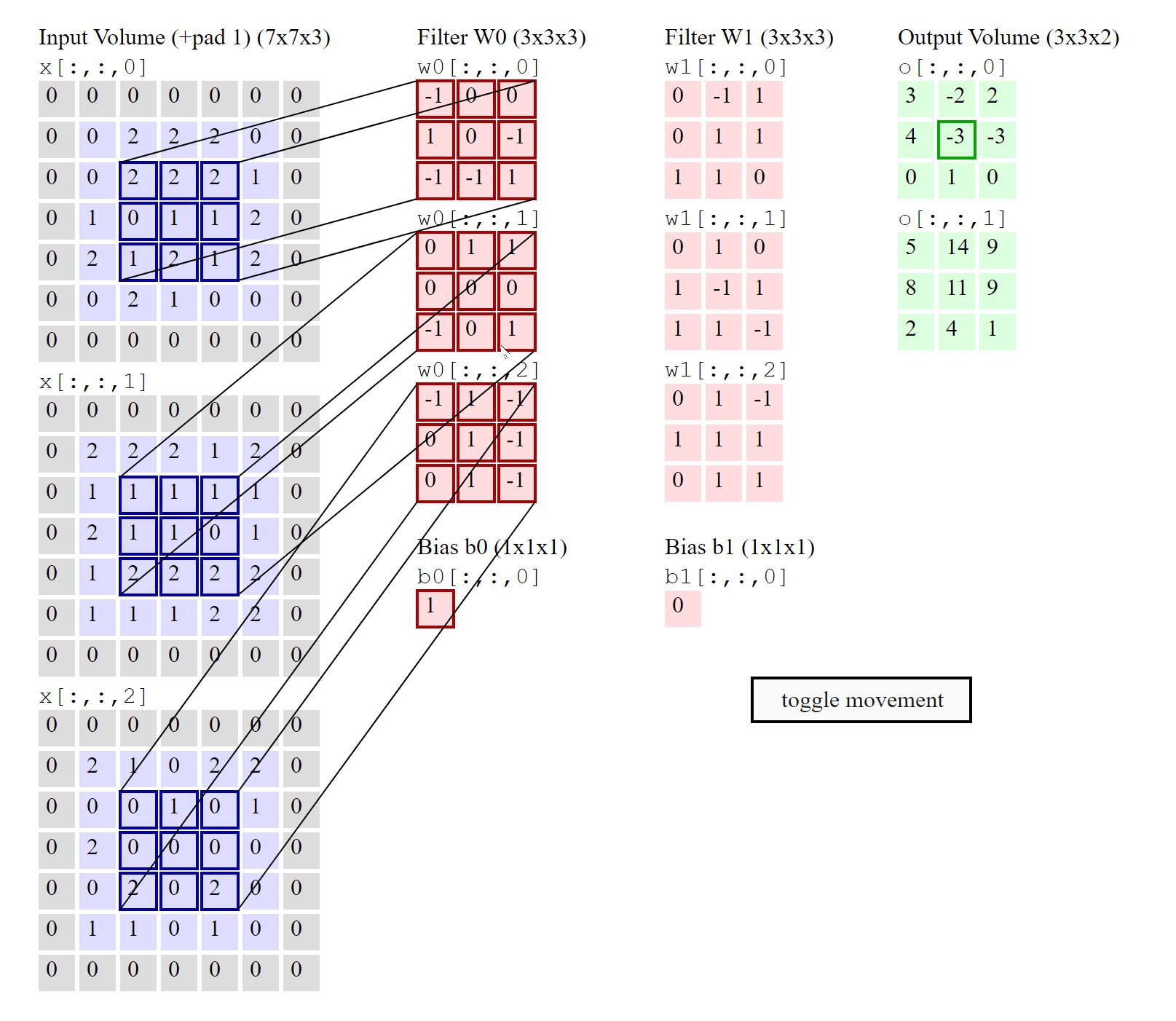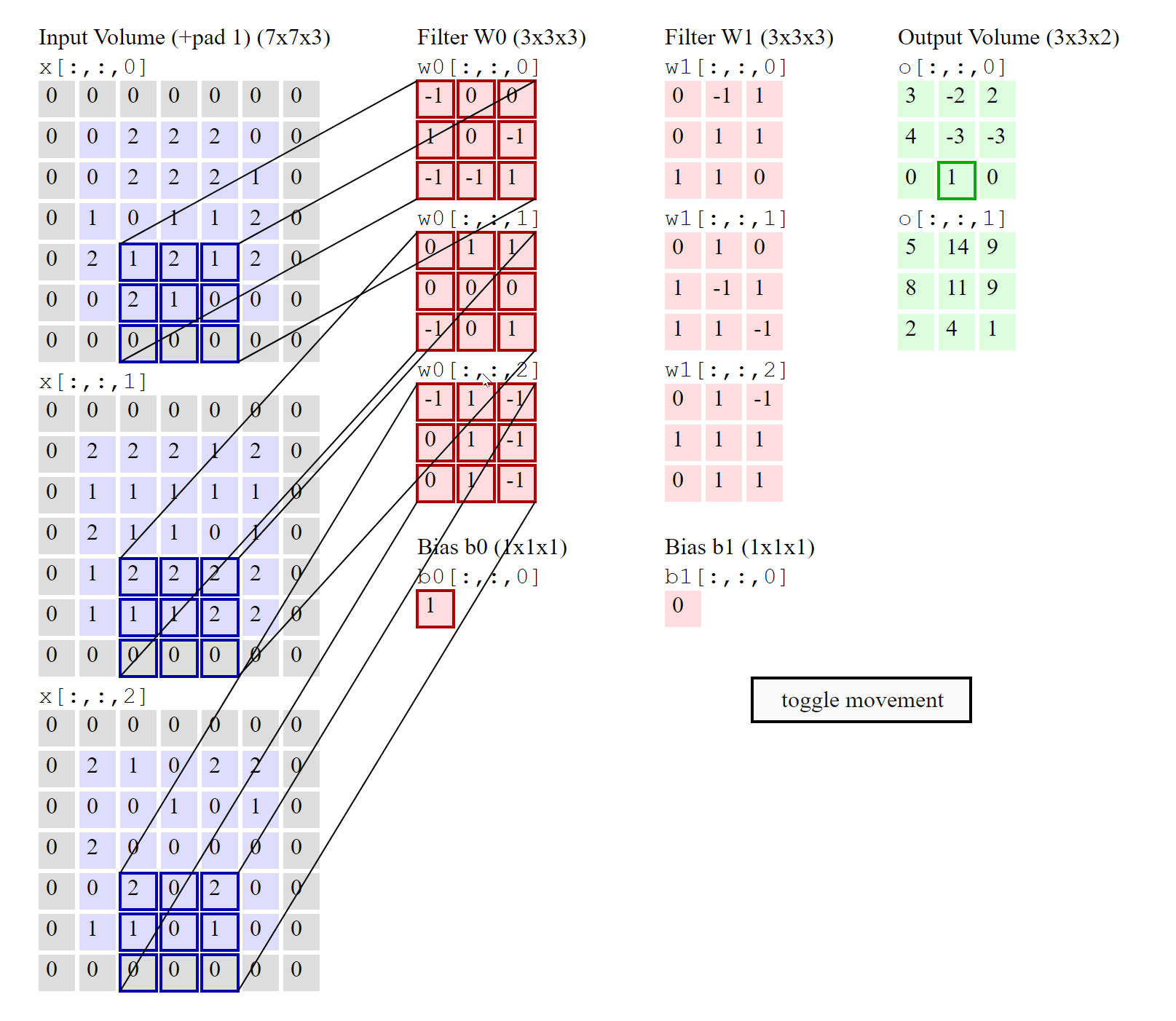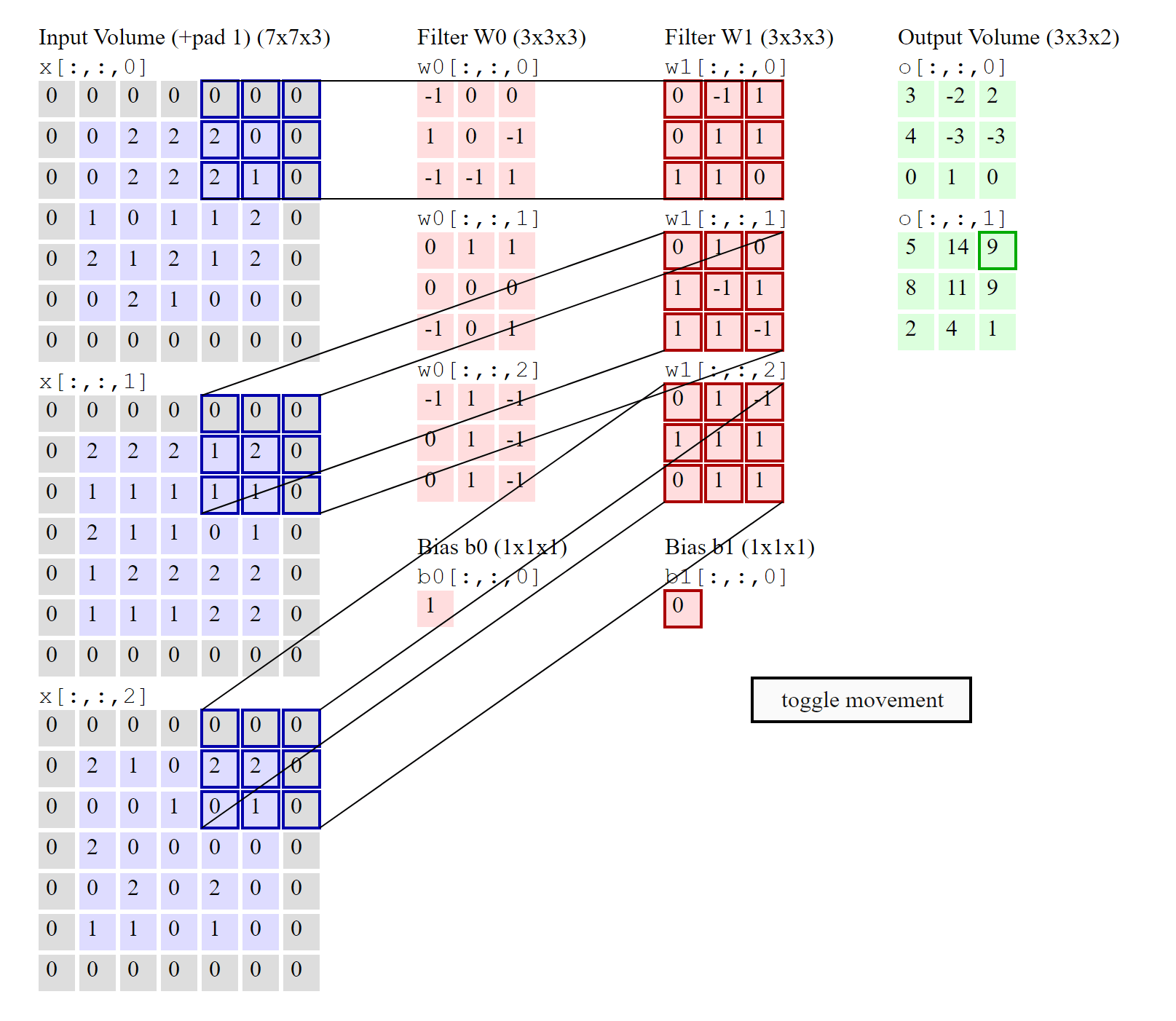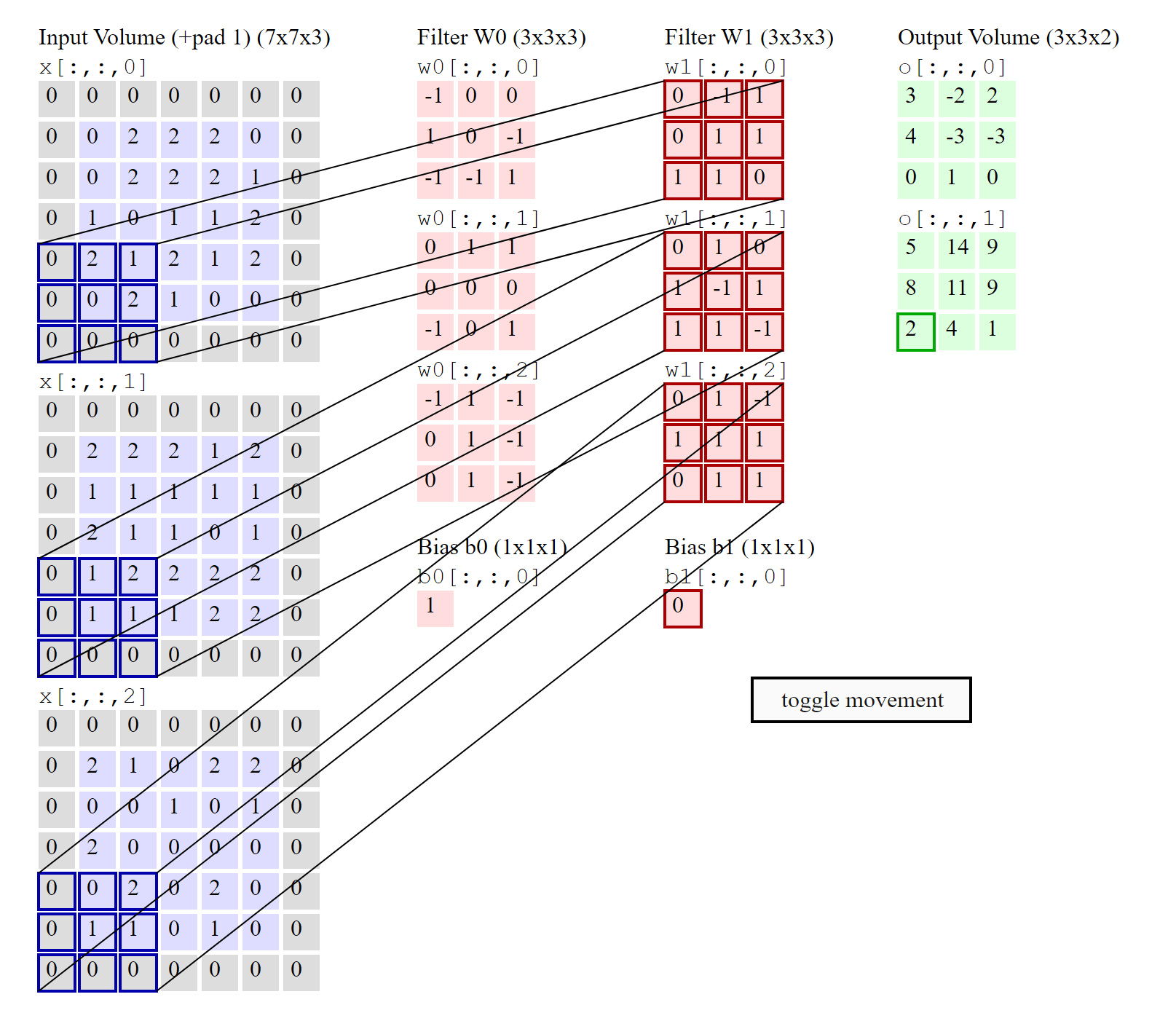
- 每个
2D卷积单元实际上是一个3D权重矩阵
叫2D的原因是卷积核步长移动的维度是2D的
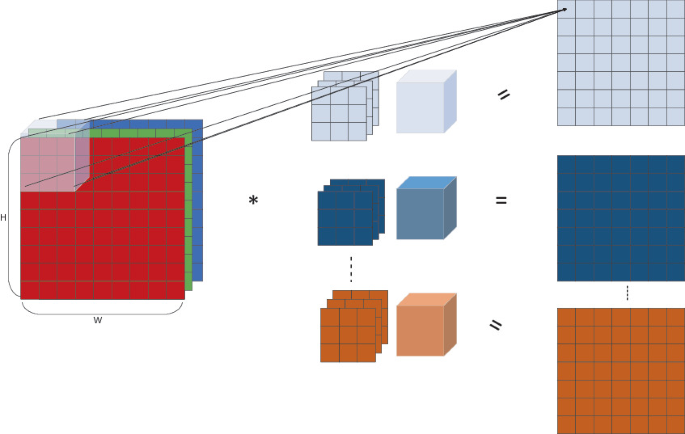
So, is there a separate filter for each input channel?#
YES, there are as many 2D filters as the number of input channels in the image. However, it helps if you think that for input matrices with more than one channel, there is only one 3D filter (as shown in the image above).
Then why is this called 2D convolution (if the filter is 3D and the input matrix is 3D)?#
This is 2D convolution because the strides of the filter are along the height and width dimensions only (NOT depth) and therefore, the output produced by this convolution is also a 2D matrix. The number of movement directions of the filter determines the dimensions of convolution.
Note: If you build up your understanding by visualizing a single 3D filter instead of multiple 2D filters (one for each layer), then you will have an easy time understanding advanced CNN architectures like Resnet, InceptionV3, etc.
作者:JoyFrank
出处:https://www.cnblogs.com/zxyfrank/p/16573301.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
世界上只有一种英雄主义,就是看到生活本来的样子,并且热爱它




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!