Temporal RoI Align for Video Object Recognition 解读
可以采用翻译软件翻译
Temporal RoI Align for Video Object Recognition
TL;DR
- Goal: exploit temporal information for the same object instance in a video.
- RPN -> proposals
- proposal -> deformable attention along time axis -> aggregate temporal features to current frame
- regress
Introduction
Related Works
- image-level information
- D&T, DFF, FGFA, MANet, STSN
- the performance of these methods degrades quickly with longer time interval
can only utilize nearby frames within 1 sec(30 frames)
- proposal-level information?
- MANet, SELSA, Leveraging Long-Range Temporal Relationships Between Proposals for Video Object Detection
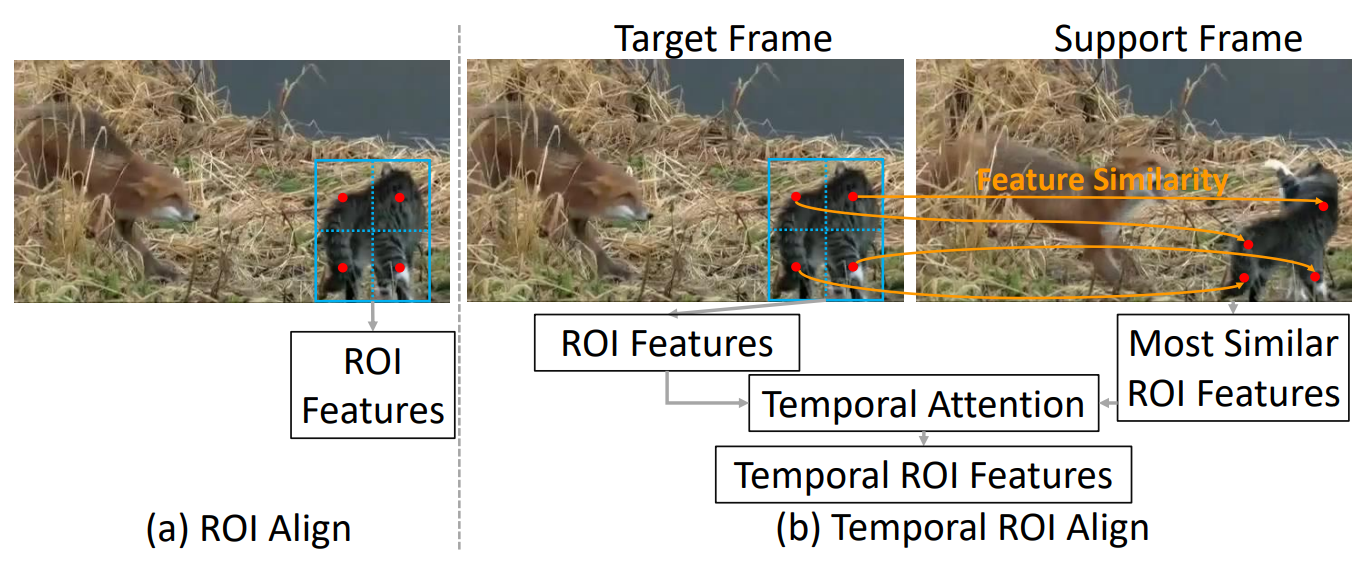
ROI Align


- Create uniform grids
- Create 4 sampling points in each grid
- Using Bilinear Interpolation
Temporal ROI Align
Extract features corresponding to target frame based on affine map, not positions in ROI regions in support frames
Notations
- \(T\), number of supporting frames
- \(F_{t} \in \mathbb{R}^{H\times W \times C}\), feature map(full image)
- \(X_{t} \in \mathbb{R}^{h\times w \times C}\)
- ROI-aligned feature
- Note: ROI-align is the prerequisite to perform detection, which adaptively rescale the feature to suit CNN
Most Similar ROI Align(Top K + concatenation)

pixel-level

deformable align, based on SIMILARITY rather than BBOX REGION in original ROI-align
- Input
- current ROI \(X_{t}\)
- feature maps of support frames \(\{F_{t+i}\}_{i = -\frac{T}{2}}^{\frac{T}{2}}\)
- Output
- \(\{X_{t+i}\}_{i = -\frac{T}{2}}^{\frac{T}{2}}\) ROI in every support frame
Temporal Feature Aggregation
How to use the T aligned feature blocks to help detection in this frame
- query: \(X_{t}\)
- key: \(\{X_{t+i}\}_{i = -\frac{T}{2}}^{\frac{T}{2}}\)
- value: \(\{X_{t+i}\}_{i = -\frac{T}{2}}^{\frac{T}{2}}\)
- multi-head
- split feature map to \(N \times \mathbf{F} \in \mathbb{R}^{h\times w\times \frac{C}{N}}\)
- apply \(N\) heads.
get an enhanced \(\bar{X}_{t}\)
Pipeline
- RPN
- ROI
- Deformable ROI Align
- Temporal Attention
- Contextualized ROI feature
Experiments
Difference from Non-local Network

Non-local Operation works

It's essentially the same: introducing dynamic, non-local reception as big as whole image.
However, I think the problem lies in the target frame*
- RPN cannot propose regions when encountering severe distortion
- We should not assume that distortion can be verified only based on single-pixel affinity
本博文本意在于记录个人的思考与经验,部分博文采用英语写作,可能影响可读性,请见谅
本文来自博客园,作者:ZXYFrank,转载请注明原文链接:https://www.cnblogs.com/zxyfrank/p/16500877.html

