如何利用Python实现图片自动上传博客园/博客园图床API外链
如何利用Python实现图片自动上传博客园/博客园图床API分析过程
动机
gitee 崩了😂,于是把所有照片都本地化了。
但是本地化之后照片就没办法加外链了,想要分享博客就只能一张一张地粘贴。
看看能不能实现自动化
怎么搞得和写论文Motivation似的哈哈
抓包
打开Chrome的调试模型,选择Network,按ctrl+R刷新一下,然后可以找到一个耗时比较长的请求,应该比较明显就能看到。我这里的名字叫做CorsUpload
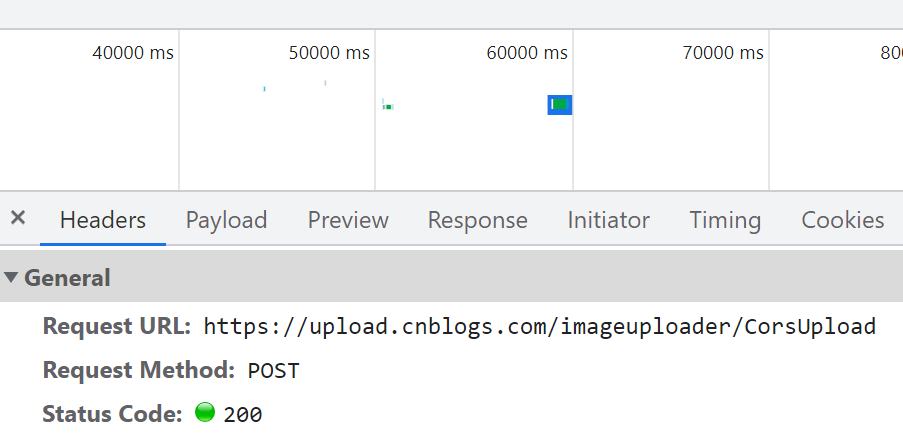
在这里可以看到请求的基本信息
:authority: upload.cnblogs.com
:method: POST
:path: /imageuploader/CorsUpload
:scheme: https
accept: application/json, text/plain, */*
accept-encoding: gzip, deflate, br
accept-language: en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7
content-length: 5502
content-type: multipart/form-data; boundary=----WebKitFormXXXXXXXXXXXXXXXXXXXXXXX
cookie: ???????
origin: https://i.cnblogs.com
referer: https://i.cnblogs.com/
sec-ch-ua: ".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
sec-fetch-dest: empty
sec-fetch-mode: cors
sec-fetch-site: same-site
user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36
x-xsrf-token: ??????
其实说实话我也搞不清楚这些东西都代表什么
先找找资料,找到了https://github.com/xiajingren/EasyBlogImageForTypora/ 这个开源的软件,但是已经不好使了,应该是API改掉了
又找到了这一篇博文
https://www.cnblogs.com/zepc007/p/14749300.html
找Cookie的话,可以点击Chrome地址栏旁边的小锁,里面有Cookie信息
其实这个博文已经可以实现功能了,但是这里面的API和上面抓包得到的结果已经不一样了
所以,也是第一次写一下这样的网络小应用,不如自己写一个
构造请求
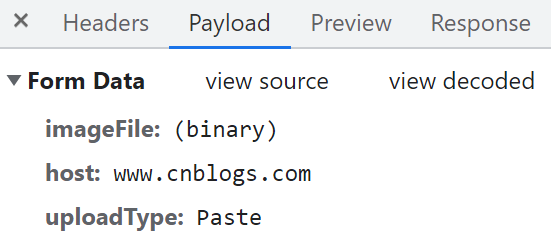
从开发者工具当中可以看到有这个Payload,其实我也不太清楚Payload是什么,大概应该是附件之类的东西
还是自己没有接触过这些工作,其实这里Form-data就应该是指代的一种请求格式
代码当中读取图片的逻辑可以这样写
def upload_url_to_cnblog(url):
if not validators.url(url):
img_path = Path(url)
if not img_path.exists() or img_path.is_dir():
raise ValueError("cannot read image from {}".format(img_path))
else:
img_name = img_path.name
img_content = img_path.open('rb')
content_type = f'image/{img_path.suffix[1:]}'
else:
res = requests.get(url)
content_type = res.headers['Content-Type']
if 'image' in content_type:
temp_list = url.split('/')
img_name = temp_list[-1] if temp_list else uuid4().hex
img_content = res.content
else:
raise ValueError("cannot read image from web {}".format(url))
先试试直接POST
headers = {
"content-type":
"multipart/form-data; boundary=----WebKitFormBoundaryfs2hsmX7dbeEKF9e"
}
multi_form_data = {
"imageFile":img_content,
"host": "www.cnblogs.com",
"uploadType": "Paste"
}
得到了一个这个错误
无法识别的文件类型 (Parameter 'imageFile')
试错
POST函数的传参格式
或许有网络编程经验的人容易找到问题在哪里,但是我不知道……
所以其实一头雾水,就开始找资料
https://blog.csdn.net/m0_37586703/article/details/88998449
这篇博客里面,我发现这个文件是有其他参数的,(文件名,二进制,文件格式)

然后看请求包中的数据也可以发现有这样的参数
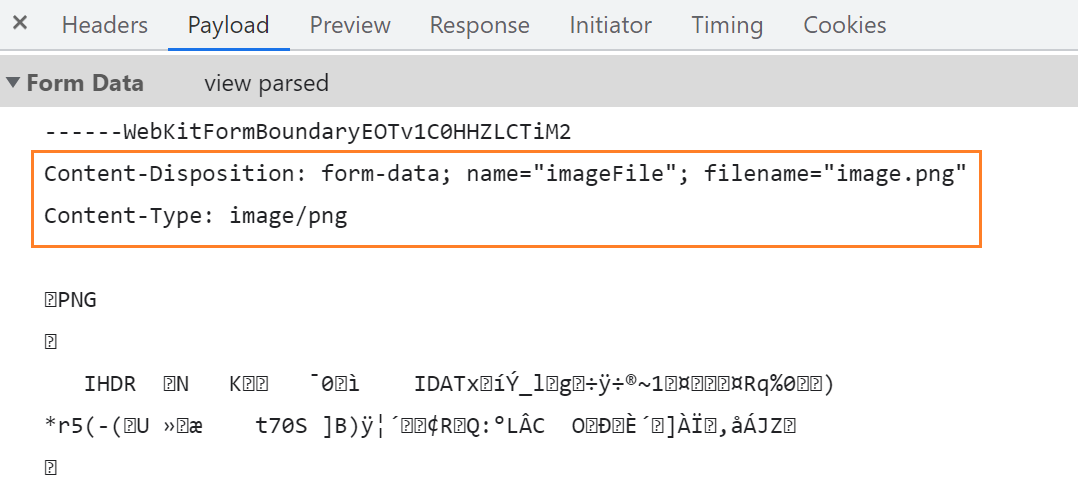
我首先查了查资料,回顾了一下multiform-data这个POST格式是什么,以前在计网学过
所以说,是需要把这个东西作为参数传进去吗?
我也忘了具体是查到什么资料了,应该是去谷歌查了一些params files python POST这样的关键词
最后找到了官方文档(文档!文档永远是好帮手!)
- https://requests.readthedocs.io/en/latest/user/quickstart/#post-a-multipart-encoded-file
- https://requests.readthedocs.io/en/latest/user/advanced/#post-multiple-multipart-encoded-files
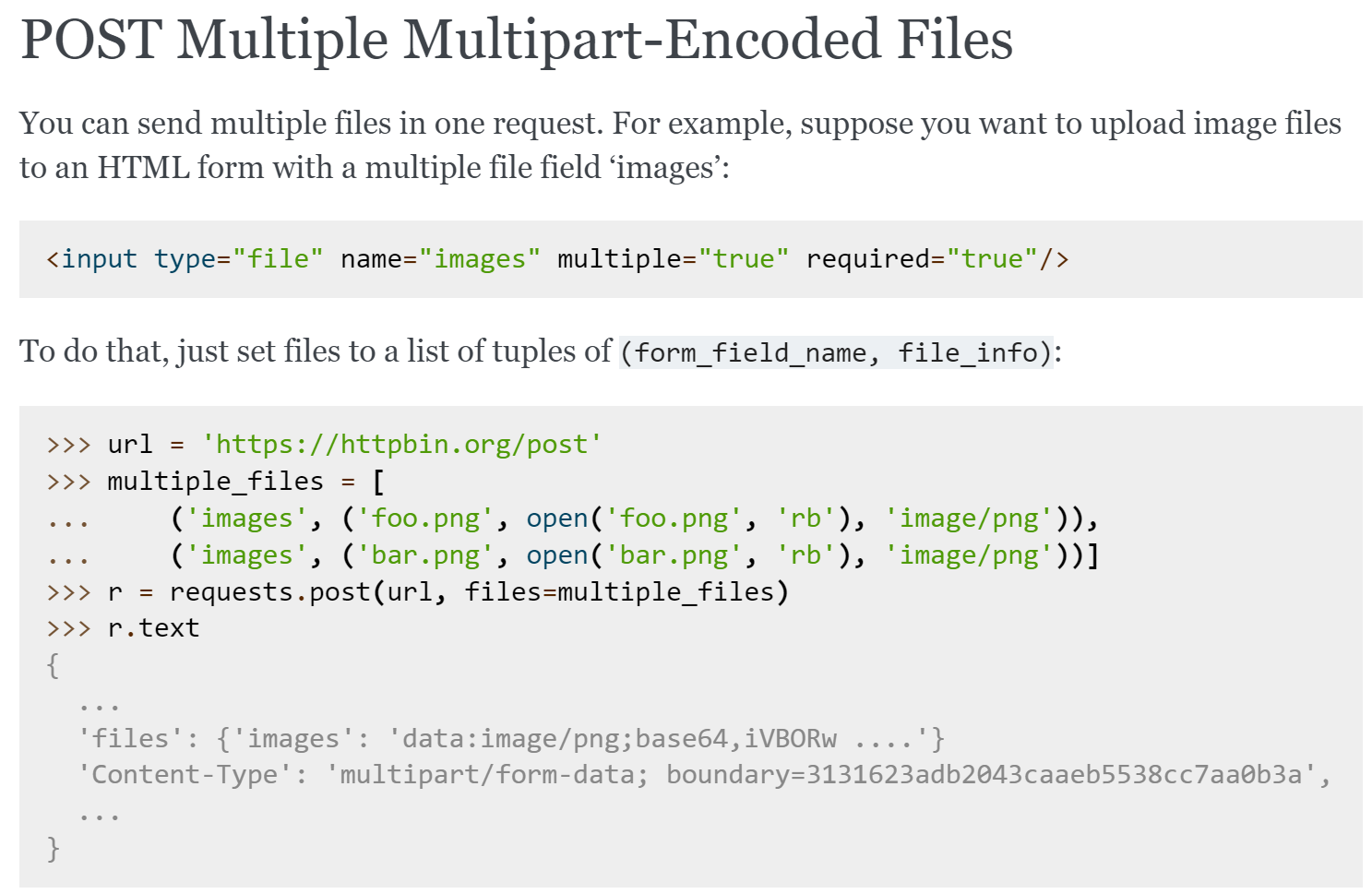
大概就是这个了!
headers = {
"content-type":
"multipart/form-data; boundary=----WebKitFormBoundaryfs2hsmX7dbeEKF9e"
}
multi_form_data = {
"imageFile": (img_name, img_content, content_type),
# "imageFile": img_content,
"host": "www.cnblogs.com",
"uploadType": "Paste"
}
res = requests.post(upload_url, files=multi_form_data, cookies=cookies)
不要自定义分隔符
又遇到了一个这个问题
Unexpected end of Stream, the content may have already been read by another component.
找到的答案都是以下那种需要设置参数的,然后我也不知道怎么回事,找到了这篇文章
不需要手动设置boundary,我一看,还真是,我手动设置的boundary无效了。
其实之前还出现过Multipart body length limit 16384 exceeded这种错误,大概都是因为这个原因。
之后我意识到,其实也可以用request.Request("post",...).prepare()来看一看生成的请求和预想的是否一致。当时自己确实没有注意分隔符这件事情
索性干脆不写请求头了,竟然成功了!
https://requests.readthedocs.io/en/latest/user/advanced/#post-multiple-multipart-encoded-files
其实就是按照这个写法就可以
工作流的设置
- 读取md文件位置
- 利用正则表达式迭代获取每一个图片信息
- 在这里我是把所有图片本地化了,也可以通过VSCode的自定义Task实现
- 上传图片,获得链接(response.message)
- 替换原有字符串即可
总体代码
import os
import re
import sys
from pathlib import Path
from urllib.parse import quote
from uuid import uuid4
import requests
import validators
import traceback
PATTERN = "\.(\/imgs\/[^)]*)"
file_path = " ".join(sys.argv[1:])
def upload_url_to_cnblog(url):
if not validators.url(url):
img_path = Path(url)
if not img_path.exists() or img_path.is_dir():
raise ValueError("cannot read image from {}".format(img_path))
else:
img_name = img_path.name
img_content = img_path.open('rb')
content_type = f'image/{img_path.suffix[1:]}'
else:
res = requests.get(url)
content_type = res.headers['Content-Type']
if 'image' in content_type:
temp_list = url.split('/')
img_name = temp_list[-1] if temp_list else uuid4().hex
img_content = res.content
else:
raise ValueError("cannot read image from web {}".format(url))
print("========uploading: {}========".format(url))
cookies = {
'.Cnblogs.AspNetCore.Cookies':
'XXX',
}
upload_url = "https://upload.cnblogs.com/imageuploader/CorsUpload"
multi_form_data = {
"imageFile": (img_name, img_content, content_type),
"host": "www.cnblogs.com",
"uploadType": "Paste"
}
res = requests.post(upload_url, files=multi_form_data, cookies=cookies)
if res.status_code == 200:
data = res.json()
success = data['success']
message = data['message']
return message
else:
raise ValueError(res.json()['message'])
def _inplace_string_replace(start, end, old_string, new_substring):
return old_string[:start] + new_substring + old_string[end:]
# local_serve(PATTERN, file_path)
def rewrite_and_upload_to_cnblog(file_path):
file_path = os.path.abspath(file_path)
file_path = Path(file_path).as_posix()
print("========MD File: {}========".format(file_path))
filename = Path(file_path).stem
new_file_path = os.path.join(
os.path.dirname(file_path),
"___{}_cnblog{}".format(filename,
os.path.splitext(file_path)[1]))
with open(file_path, "r", encoding="utf-8") as old_file:
content = old_file.read()
m = re.search(PATTERN, content)
while m is not None:
img_path = os.path.abspath(
os.path.join(os.path.dirname(file_path), m.group()))
try:
img_link = upload_url_to_cnblog(img_path)
except Exception as e:
print(traceback.format_exc())
continue
content = _inplace_string_replace(m.start(), m.end(), content,
img_link)
m = re.search(PATTERN, content)
os.makedirs(os.path.dirname(new_file_path), exist_ok=True)
with open(new_file_path, "w", encoding="utf8") as new_file:
new_file.write(content)
arg = sys.argv[-1]
print(arg)
rewrite_and_upload_to_cnblog(arg)
本文来自博客园,作者:ZXYFrank,转载请注明原文链接:https://www.cnblogs.com/zxyfrank/p/16414642.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号