FairMOT 英文详细解读与思考
takeaways
factors that leads to degradation of SOTA MOT trackers
- anchor
- feature sharing
In FairMOT
- CenterNet-based
- homogenous branches
achieves a giant improvement on MOTA
Background
traditional paradigm:detection + association
- detection
- bounding box
- association
- reid features
combining the two tasks is not trivial.
reasons affecting reid and detection joint learning
- anchors(from Faster RCNN)
- reid features depend on bounding boxes
- the model favor the detection task when
detectionandreidcompetes.
- the model favor the detection task when

- anchors introduce ambiguity of reid
- feature sharing
Detection task and re-ID task are two totally different tasks and they need different features.
TODO 『2022-03-21 [It says so. It may not be the case though.]?』
the shared features will reduce the performance of each task
- high-dimentional features for reid are not suitable for MOT
reid often use high-dimentional features.
It's not suitable for re-identification MOT tasks.
🤔
Related Works
seperate/joint model for detection and linking(data association)
FairMOT belongs to "seperate"
seperate model
MOTION BASED
SORT
Kalman filter for tracklet prediction
Hungarian algorithm for track assignment
IOU-Tracker
merely IOU-based
SOT-based MOT
slow when there are a large number of people in the scene.
Motion Evaluation Network
Long-Term Tracking With Deep Tracklet Association
LSTM based.
Handle tracklet fragments
Reid Network Based
- calculate affinity between
trackletsanddetections - using
Hungarian algorithmto link
Some methods focus on fusing or learning adaptive clues for
- enhancing appearance cues
- fuse multi cues
- e.g. Spatial-Temporal Relation Networks for Multi-Object Tracking
- leverage body pose priors
Offline methods
conclusion:
- develop the most suitable model for each task separately without making compromise
- too slow
- because of no feature sharing
joint model
Joint Detection and reID
Track RCNN
jointly regress bounding box and reid features based on Mask-RCNN
❗usually low and not as accurate as two-step models
Joint Detection and Motion Prediction
Tracktor
track auto regression
no box association needed!
actually tracktor with no extensions can already achieve relatively high MOTA
These box-based methods assume that bounding boxes have a large overlap between frames, which is not true in lowframe rate videos.
Actually, tracktor is robust with FPS as low as 5.
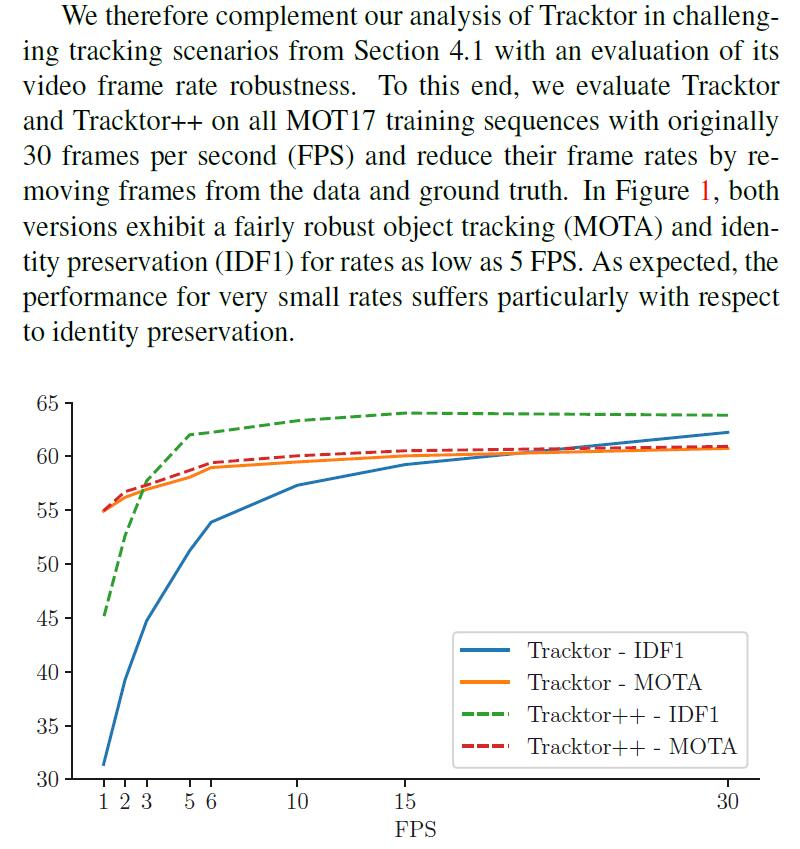
CenterTrack
drawbacks
- only associate objects in adjacent frames without re-initializing lost tracks
- cannot handle occlusion well
Tube-based Video Object Detection
Unfairness Issues in One-shot Trackers
by anchors
- Overlook reID
in the training stage, the model is seriously biased to estimate accurate object proposals rather than high quality re-ID features.
- Anchor Ambiguity
- Sharing Feature
feature maps in object detection are usually down-sampled by 8/16/32 times to balance accuracy and speed. This is acceptable for object detection but it is too coarse for learning re-ID features
- Question: I think it's also too coarse for object detection.
+ However, why does it work???
because features extracted at coarse anchors may not be aligned with object centers
by Features
- Detection
- high-level semantic features for classification
- reID
- low-level appearance features for distinguishing objects
Feature Dimension
- HIGH for reID
- LOW for detection
- Question: Why do reID features harm detection?
+ Are they independent???
Task Characteristics
- MOT
- small number of one-to-one matching
- demand for speed
- reID
- large number of queries
- more discriminative features
FairMOT philosophy
detection first, reid secondary
- based on
CenterNetanchor-free
- homogenous branches for detection and reid
+ Quesion: What does "fair" mean?
+ Quesion: Do the homogenous branches share features?
+ Quesion: What does "one-shot" tracker mean?
Model
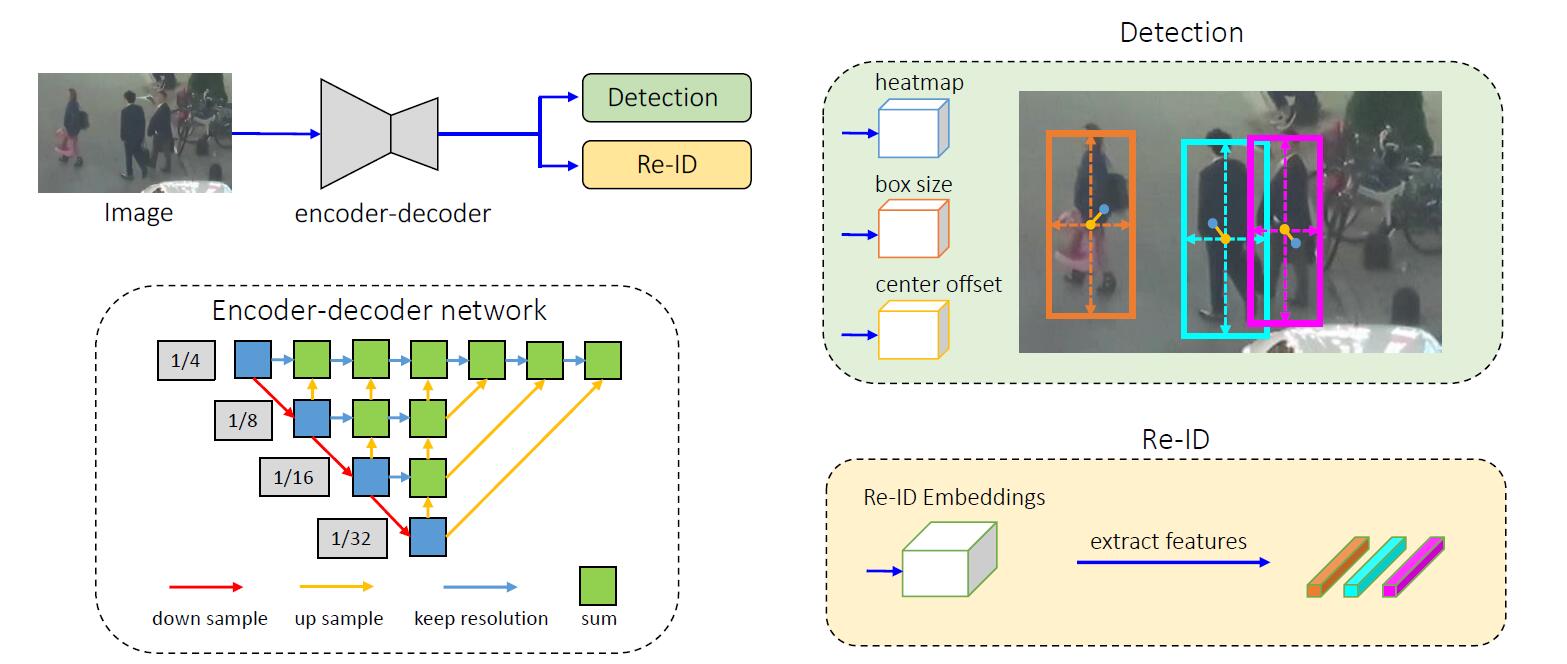
Backbone
DLA-34- ResNet-34 with DLA
- add more skip connections
- convolutions in up-sampling layers are replaced with
deformable conv
Branches
- detection (
CenterNet)- Heatmap Head(
1xHxW)- object center has highest response, which is exponentially decaying as the become far from the object center.
- like gaussian
- pixel-wise logistic regression
- focal loss
- Bounding Box offset and size(both
2xHxW)- estimates a continuous offset relative to the object center for each pixel in order to mitigate the impact of down-sampling
- l1 loss and balance multi-task with hyperparameter \(\lambda\)
- Heatmap Head(
- reID
- \(\mathbf{E}^{128\times H \times W} = \text{Conv}(F_{l})\)(l is the top layer of backbone)
- \(\mathbf{E}_{x,y}\in \R^{128}\)(128 channels, 128 kinds of filter responses)
- train reID using cross entropy
- Question: !!! IRRATIONAL!
+ Kernel size is FIXED.
- (Maybe these 128 filters are the compromise to introduce different kernel)
- i.e. enough diversity for filters
+ How can it generalize to different size of objects?
+ IS THERE ANY DETECTOR USING THE CONTINUITY OF PIXELS,
+ e.g. quick selection in photoshop
- Question: HOW TO GENERATE DYNAMIC KERNEL?
+ Note: What if we segment the object and
- extract the feature in the OBJECT MASK
- instead of the so-called center
- (which is actually corresponding to a bounding box) ?
What if B is more easily-discriminated than A.
i.e. Although it's occluded by A, the visible part is enough for leading the model to WRONGLY reckon the object as B

reID branch
for the top-level feature of DLA-34 \(\mathbf{F}_{l}\) (low-resolution)
In ablation study, they use BI-LINEAR INTERPOLATION
- Question: How is BI-LINEAR INTERPOLATION performed.
Algorithm
Train
prepare data
given bounding boxes
- calculate CENTER for heatmap
Single Image Training
- without dense identity annotations
- assign each bounding box an ID
- perform data augmentation
- HSV permutation
- rotation, scaling, translation and shearing
can then be finetuned on relatively small MOT datasets
- boost human detection
- enhance generalization
use CENTER,SIZE,CLASS_LABEL
Inference
Inferece
- Input Image
Heatmap(Response Map)- to determine where there is some kind of object(no idea what the category is)
NMSon heatmap3x3maxpooing- keep the keypoints with score higher than a threshold
Regressbounding box- (
centerandsize) center\((x,y)\) = heatmap peak + offset
- (
- extract
reIDfeatures at \((x,y)\)conv+MLP+softmax- to learn the features via classification
-
During the training process of our network, only the identity embedding vectors located at object centers are used for training, since we can obtain object centers from the objectness heatmap in testing
- online association
- see below
Data Association using ReID features
Data Association is performed between
predicted(Motion Model, i.e. Kalman Filter) and detected bounding boxes.
-
\[D = \lambda D_{r} + (1-\lambda)D_{m} \]
- \(D_{m}\) is calculated using the distribution from
Kalman Filterfor predicted(motion cued) and detected bounding boxes - $D_{r} = \text{CosineAffinity}(\mathbf{R}{pred},\mathbf{R}) $(ReID features)
-
set Mahalanobis distance to infinity if it is larger than a threshold to avoid getting trajectories with large motion.
- \(D_{m}\) is calculated using the distribution from
- Using
Hungarian Algorithm- \(\tau_{1} = 0.4\) for linking
- \(\tau_{2} = 0.5\) for rematch tracklets
- save the unmatched tracklets for
30frames
Experiments
Center-based ReID
- ROI-Align
Track RCNN- reID feature from detection proposals
- POS-Anchor
JDE- from positive anchors
- CENTER(FairMOT)
- only from center(filter centered at center)
- two-stage
- FairMOT detection + ROI-Align = \(\mathbf{F}_{aligned}\)
- \(\mathbf{R} = \text{MLP}(\mathbf{F}_{aligned})\)
difference between
ROI-Alignandtwo-stageis in training
ROI-Align: \(\text{Conv}(\text{Detected-Proposals}(\mathbf{F}))\)
what's this? 😂
ROI-Align: \(\text{Conv}(\text{GT-BBoxes}(\mathbf{F}))\)????
two-stage: \(\text{Conv}(\text{Detection-Head}(\mathbf{F}))\)
\(\mathbf{F}\) is the top-level feature of the backbone(downsampled)

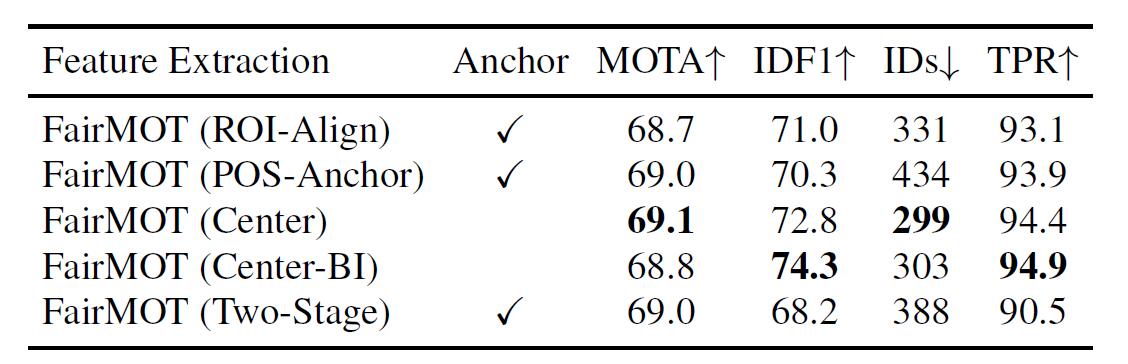
for
IDF1
refer to Performance measures and a data set for multi-target, multi-camera tracking.
Conflict between reID and detection
Learning lower dimensional re-ID features causes less harm to the detection accuracy and improves the inference speed.
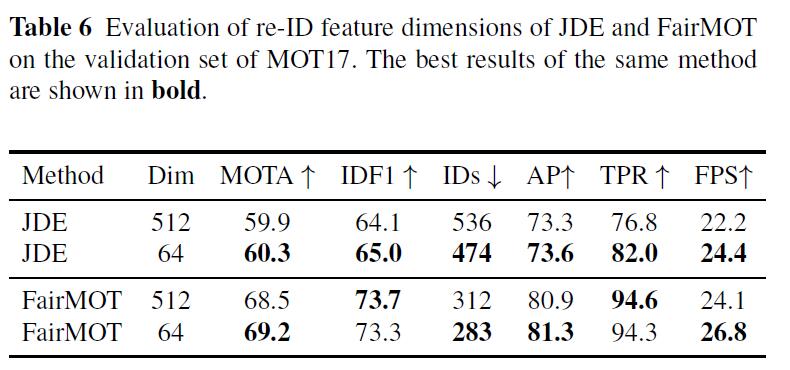
Single Image Training
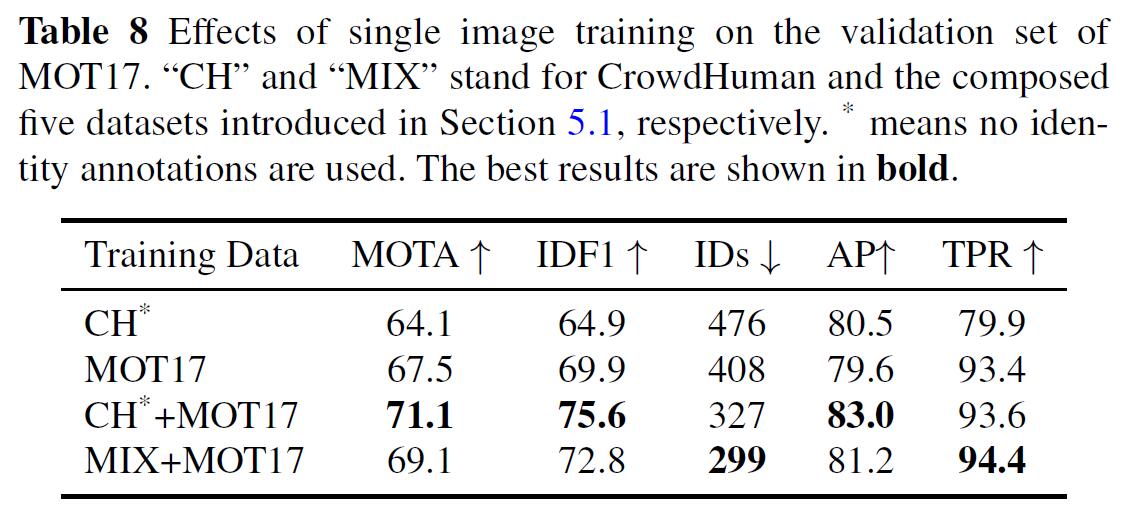
there are also other comparisons
- multi-task loss weighing strategies
- backbone
本文来自博客园,作者:ZXYFrank,转载请注明原文链接:https://www.cnblogs.com/zxyfrank/p/16041836.html
