多目标跟踪综述 2021
- TransTrack(Init One Stage)/(TrackFormer)
- TransCenter(Trans + Regression)
- SiamMOT
- CorrTrack(Detection)
- CenterTrack 检测和跟踪联合
MPNTracker
Background
MOT Categories


Track-by-detection
-
Detection
-
ReID(Data Association)
ReID应该是充分的
-
Bounding Boxes
- Features of ROI
-
Siamese/Re-ID/IOU(Appearance Affinity)
-
Motion
-
the projection of non-linear 3D motion into the 2D image domain still poses a challenging problem for many models.?
-
这里有一个重要的假设:跟踪结果一定是检测结果的子集
Two-Stage Milestones: SORT and DeepSORT
Detector = +18.9%
- Faster-RCNN
- Kalman Filter
- \(\mathbf{o}_i = [\texttt{r},x,y,s,\dot{x},\dot{y},\dot{s}]\)
- 将位置和面积视作匀速变化的量(变化率为常数)
- linear constant velocity model / independent of other objects and camera motion.
- \(\mathbf{o}_i = [\texttt{r},x,y,s,\dot{x},\dot{y},\dot{s}]\)
- Tracklet Init and Deletion
- Accept all detection(>minHeight&minConfidence)
- Immediate Deleting
DeepSORTref
- Faster-RCNN
-
\[c = \lambda D_1(\text{track}_i,\text{detection}_j) + (1-\lambda)D_2(\text{track}_i,\text{detection}_j) \]
- Motion
- \(D_1\):马氏距离
- Appearance
- \(D_2\):深度特征的余弦相似度
- ReID Pretrained Model
-
- Tracklet Init and Deletion
Tentative= 3 frames (>minHeight&minConfidence)- Delete after 3 frames
Joint Detection and Tracking (Detection-by-tracking)


『IDEA [检测(检测本身就是多目标的)是多目标跟踪的一个上界]』
核心是Joint Learning
TODO 『2021-12-21 [CenterTrack]』
Eval


Specifically, the mapping between ground truthand hypotheses is established as follows: if the ground truth object oi and the hypothesis hj are matched in frame t - 1,and in frame t the IoU(oi; hj) \(\geq\) 0:5, then oi and hj are matched in that frame, even if there exists another hypothesis hk such that IoU(oi; hj) < IoU(oi; hk), considering the continuity constraint. After the matching from previousframes has been performed, the remaining objects are tried to be matched with the remaining hypotheses, still using a0.5 IoU threshold. The ground truth bounding boxes that cannot be associated with a hypothesis are counted as falsenegatives (FN), and the hypotheses that cannot be associated with a real bounding box are marked as false positives(FP). Also, every time a ground truth object tracking is interrupted and later resumed is counted as a fragmentation,while every time a tracked ground truth object ID is incorrectly changed during the tracking duration is counted as anID switch. Then, the simple metrics computed are the following:
Detection
Transformer
https://jalammar.github.io/illustrated-transformer/
- RNN
- Maintain the hidden state
- Transformer
- Self-Attention Global
Contextualized Embedding
SiamMOT = DeepSORT + Motion Model
Motivation & Background
- 传统MOT
- 二分图匹配
- 节点维护
外形+运动特征 - 全局优化问题
- 没有显式的帧间关联
-
improving local linking over consecutive frames rather than building an offline graph to re-identify instances across large temporal gaps.
- 节点维护
- 二分图匹配
SORT & DeepSORT

- 孪生网络
- 响应图
Siam网络缺点:无法区分不同的物体

TODO 『2021-12-21 [Faster RCNN]』
TODO 『2021-12-21 [center Track] SKIPPED』
Contribution
- SiamMOT: Faster RCNN + Motion Model
- consecutive frames & local linking
- Based on SORT
Pipeline
Arch

Given\(\mathbf{F}^{t},\mathbf{F}^{t+1};\mathbf{R}_{i}^{t}(\text{Region, Bounding Box})\)
Faster-RCNN
- \(R_{i}^{t}\)是t时刻的跟踪结果
- \(\mathbf{D}^{t+1} = \text{Detector}(\mathbf{F}^{t+1})\)
Region-based Siamese Tracker
-
\(\mathbf{f}_{R_i}^{t} = \operatorname{ROIAlign}(R_{i}^{t},\text{dim})\)
- feature of Region(Object) i in frame t
-
\(\mathbf{f}_{S_i}^{t} = \operatorname{ROIAlign}(S_{i}^{t},\text{dim})\)
- feature of Object Search Area i in frame t
- \(S_{i}^{t+1} = \operatorname{Expand}(R_{i}^{t},\text{factor})\)
- (考虑物体不会在两帧之间产生巨大位移)
-
\(\mathbf{R}^{t+1} = \text{SpatialMatching}(\mathbf{Mot}^{t+1},\mathbf{Det}^{t+1} )\)
- \(\mathbf{Mot}^{t+1},\mathbf{Det}^{t+1}\)分别代表运动模型的预测结果和目标检测器的结果
- 他们都是是在先验扩展的区域内得到的
- \(\mathbf{Mot}^{t+1}\)对应
互相关回归 - \(\mathbf{Det}^{t+1}\)对应
检测结果
核心:Siamese Tracker
Implicit MM

『IDEA [为什么采用Search]』

❓感觉好像是写错了
因为不一定是轨迹,没有运动关联性

Explicit MM- channel-wise cross-correlation
- response map

通过Correlation互相关——卷积操作:实际上利用了卷积操作的可扩展性(灵活性)
包括置信度
以及回归框
v,p都是在16*16大小的特征图上,每个像素点的
最后寻找最优位置
The penalty map is introduced to discourage dramatic movements
『IDEA [我一直感觉基于ROI的回归是不充分的,因为卷积操作对物体变化的感知在inference阶段是不存在的,参数都已经固化了]』
『IDEA [BoundingBoxReg学习到的是一个通用的,根据特征回归偏移量(调整量)的参数。按理说,但是效果却很好]』
❓其实这里说是Motion Model,我觉得并不是。这里并没有建立运动模型。在本质上和SiamFC是一样的。
First it uses the channel independent correlation operation to allow the network to explicitly learn a matching function between the same instance in sequential frames. Second, it enables a mechanism for finer-grained pixel-level supervision which is important to reduce the cases of falsely matching to distractors.
那为什么会有很好的效果呢?
Training
\(l_{motion}\)就是之前提到过的损失函数
Short Occlusion
Inference
Spacial Matching
Solver
一些匹配规则
CorrTrack/TLD = FairMOT+Corr.
这篇文章总体来讲写的不是很清楚
没有代码,也没有明确的架构图
Motivation & Background
- 卷积神经网络结构上的局部感知特性
- 相同语义个体相似度高,干扰强烈
- 不能有效获得空间和时间上的长程依赖
- MOT的任务特点:处理多尺度特征/物体大小不确定(和检测任务相同)检测任务处理多尺度特征的思路

相似度
- 基于
previous Frame/previous ROI计算语义相似度- 空间相关性受到了检测器的限制
- 大量外围相似个体(尤其在行人场景下)
- 导致
ID Switch
the correlation information between the cropped image patches is lost directly, and the adjacency spatial relationship is only retained in coordinates
需要区分DISTRACOTRS
❓但是这个有必要吗?相邻物体并不会出现很剧烈的移动啊。

也可能作者的意思是出现了Touching Switch(接触漂移,我自己起的名字)

- 基于
FairMOT
Pipeline

Arch
- 通用特征提取
- 从时空依赖中同时学习相关性并进行检测预测
- 将检测结果关联到最接近的轨迹上

Spatial Local Correlation Layers
目的是得到context correlation features(融合上下文的空间特征)
Spacial Correlation

- 作者以Non-local Module为参照,进行了基于邻域的改进
其实这个改进很Intuitive

仅仅是人为设置了一个局部感受野


实际上是做了一个Self-Attention

- 注意力权重\(\alpha(x,y) = \text{NeighborsCorrAt}(x,y)\)
-
\[\text{Correlated Feature} = \mathbf{F}_{C}^{l} = \sum_{x,y} \alpha(x,y) \mathbf{F}_{t}^{l}(x,y) \]
- 上标\(l\)代表特征金字塔的位置
- 在这里指的是,还没有用到\(l\)
Spacial Corr. on FPN
这是什么意思?
Temporal Correlation


不是很懂
这是之前的一个公式,一模一样啊

colorization as a proxy task
这里甚至没有提到损失函数
Actually, our method intensively perform siamese tracking operations \(M\times N\) to increases the discrimination.

Self-Supervised Feature Learning
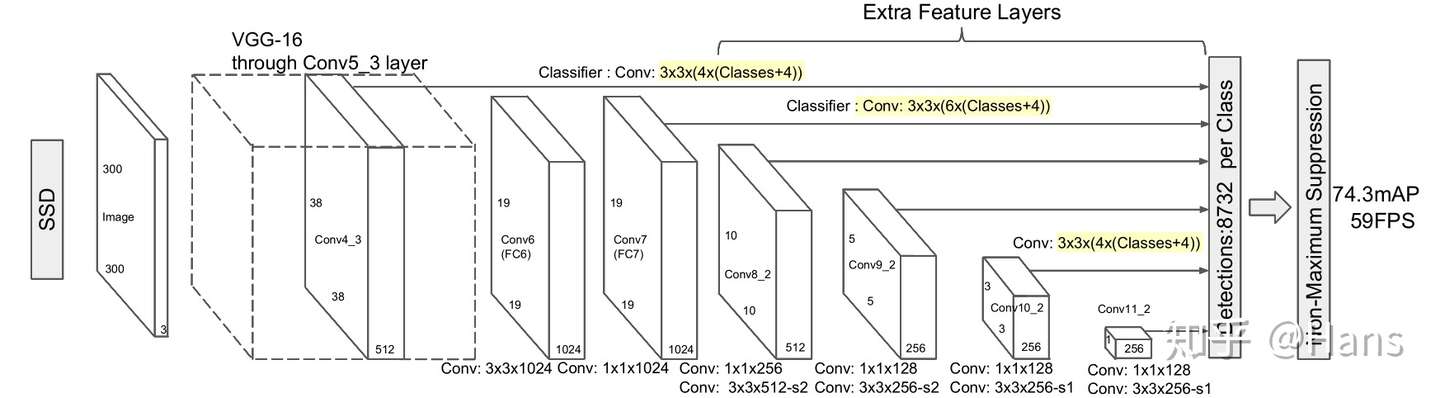
TransTrack
Motivation

Query-key Promising

For the same object, its feature in different frames is highly similar, which enables the query-key mechanism to output ordered object sets. This inspiration should also be beneficial to the MOT task.
How to transfer q-k from SOT to MOT
作者认为,最严重的问题在于new-coming物体,没有相应的Query。而在SOT当中,目标是保证在画面当中的
A desirable solution should be able to well capture new coming objects and propagate previously detected objects to the following frames at the same time
- New-coming Objects
Traditinoal Way
Pipeline

Arch
这里的Q-K不是指的Attention里面的
- one Encoder ->
key- Input: extracted features(2-frames)
- 2 Parallel Decoder ->
query?- Object Detection(DETR)
- Track
- Appearance & Location Information
- Box Association
- KM算法

- 带权二分图最大匹配

-
set prediction
- 2 sets
- (DETR)
object queryfordetection- (NO NMS)
- features(of objects on track) as
track query-
provide consistent object information to maintain tracklets.
-
-
simple IoU matching to generate the final ordered object set from them.
-
previous frames -> data association
Input and Output
Training

Inference
目标初始化
TransTrack first detects objects on the first frame, where the feature maps are from two copies of the first frame.
occlusions and shortterm
disappearing
Specifically, if a tracking box is unmatched, it keeps as an “inactive” tracking box until it remains unmatched for K consecutive frames. Inactive tracking boxes can be matched to detection boxes and regain their ID.
we choose K = 32.
Why using Transformer/ dominant reason
-
Decent Frame Work
-
No Prior
Summary
JDT paradigm
What's Different from TD
-
TD = Detection + Association
-
Joint Learning/Task-Driven
Questions
- 矩形框估计可能并不准确

- SiamMask
- Segmentation is the upper bound of Detection
- 可能影响准确率
-
ID Switch
TODO
Appendix
Kalman Filter

SORT
DeepSORT
- \(D_1\)
- 在卡尔曼滤波分布上计算的马氏距离
- \(M(\text{track}_i,\text{dec}_j;S_{\text{Kalman Filter}})\)

-
\(D_2\)
- 深度ReID特征余弦相似度
- 仅仅依靠外观特征进行匹配也是可以进行追踪的。
-
级联匹配
如果一条轨迹被遮挡了一段较长的时间,那么在卡尔曼滤波器的不断预测中就会导致概率弥散。那么假设现在有两条轨迹竞争同一个检测目标,那么那条遮挡时间长的往往得到马氏距离更小(更加接近)
马氏距离的协方差矩阵
使检测目标倾向于分配给丢失时间更长的轨迹,但是直观上,该检测目标应该分配给时间上最近的轨迹。所以deepsort引入了级联匹配的策略让更经常出现的目标被分配的优先级更高。
- 应对遮挡
IOU匹配
unconfirmed and unmatched tracks of age n = 1.This helps to to account for sudden appearance changes, e.g., due to partial occlusion with static scene geometry, and to increase robustness against erroneous initialization
Faster-RCNN

FPN + Fast RCNN
- RPN
Predefined Anchors

ROI Pooling
- 2 MLP Heads
- Classification
Coord. Regression:修正候选框
Feature Pyramid
需要解决的问题
- 多尺度
- 细粒度信息丢失
- 小物体无法重建

图像金字塔单个高层特征直接抽取不同特征层特征金字塔- 降采样
- 上采样
- 最近邻插值


- 1*1卷积,侧向连接+merge

Dilated Conv.
- 不做pooling损失信息的情况下,加大了感受野

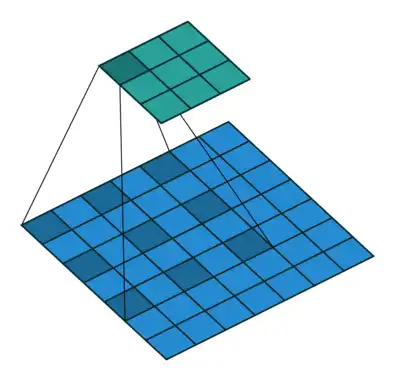
Non-local Module
- 捕捉局部精细结构/模式匹配
- 可以看做
局部滤波
- 可以看做



目的:大范围依赖
增大感受野的方式
- 堆叠
- Sampling 过程中丢失大量信息
- 全连接/Attention
Multi Scale Perception
-
ROI Pooling/ROI Align- 本质上属于
Pooling方法,有损采样
- 本质上属于
-
FPN- 特征金字塔
- 可以较好地融合不同尺度的特征
FairMOT
- 目标检测:视为高分辨率特征图上基于中心的包围盒回归任务
- =
Faster RCNN=clsHeatMap+BBReg
- =
- 网络架构适应ReID任务
- 类似于
特征金字塔 - 多尺度融合
- 类似于
核心在于损失函数的设计
- 数据关联上
- 基于DeepSORT
- 其实只是替代了ReID特征
- 变成了
Task-Driven

本文来自博客园,作者:ZXYFrank,转载请注明原文链接:https://www.cnblogs.com/zxyfrank/p/15768594.html
