ELASTICSEARCH-分析器详解和搜索原理
ELASTICSEARCH-分析器:
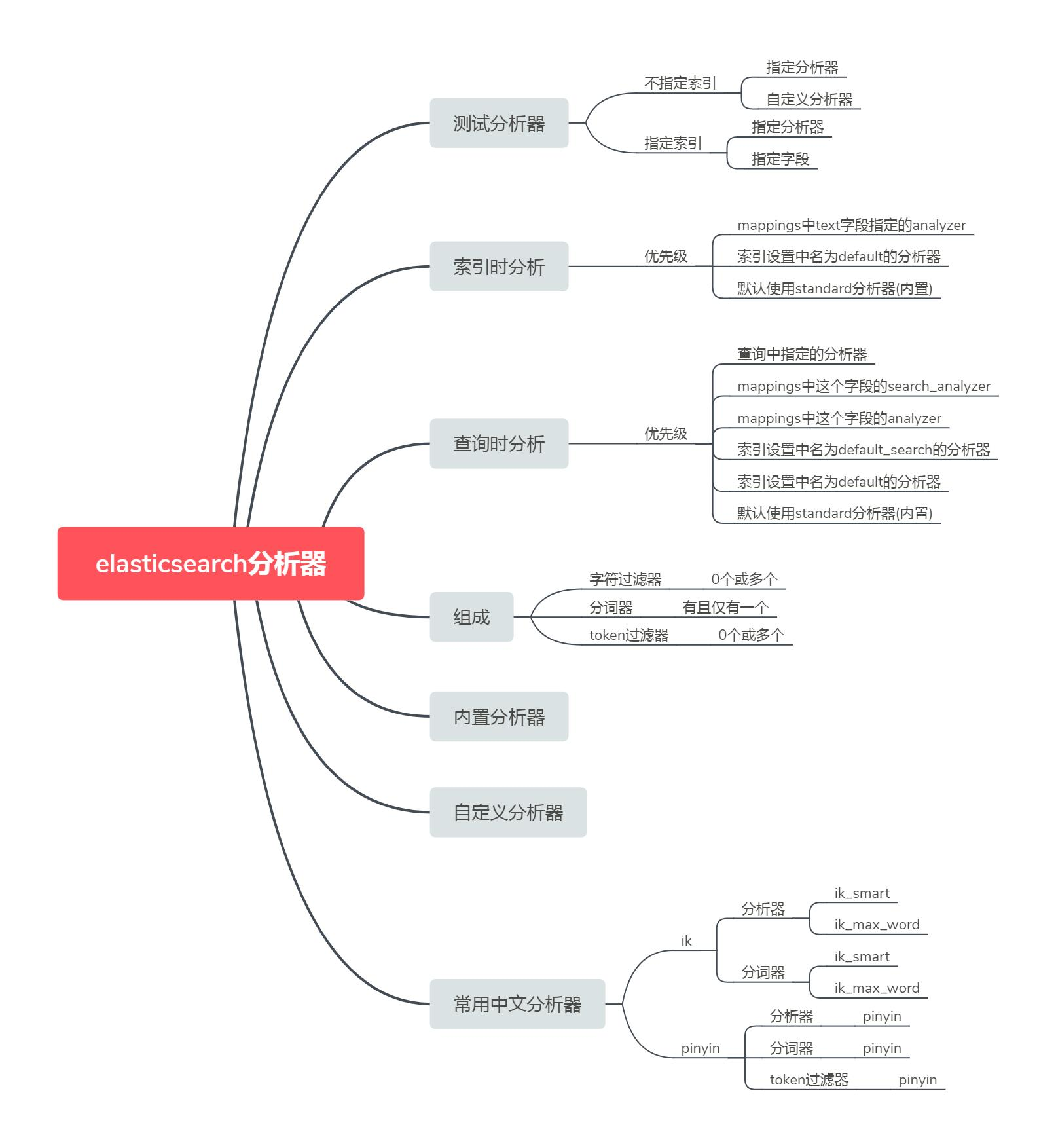
转载:https://www.freesion.com/article/79701102614/
Elasticsearch Client发送搜索请求,某个索引库,一般默认是5个分片(shard)。
它返回的时候,由各个分片汇总结果回来。

官网API
https://www.elastic.co/guide/en/elasticsearch/client/java-api/2.4/index.html

es 在查询时, 可以指定搜索类型为下面四种:
QUERY_THEN_FETCH
QUERY_AND_FEATCH
DFS_QUERY_THEN_FEATCH
DFS_QUERY_AND_FEATCH
那么这 4 种搜索类型有什么区别?
在讲这四种搜索类型的区别之前, 先分析一下分布式搜索背景介绍:
ES 天生就是为分布式而生, 但分布式有分布式的缺点。 比如要搜索某个单词, 但是数据却分别在 5 个分片(Shard)上面, 这 5 个分片可能在 5 台主机上面。 因为全文搜索天生就要排序( 按照匹配度进行排名) ,但数据却在 5 个分片上, 如何得到最后正确的排序呢? ES是这样做的, 大概分两步:
step1、 ES 客户端将会同时向 5 个分片发起搜索请求。
step2、 这 5 个分片基于本分片的内容独立完成搜索, 然后将符合条件的结果全部返回。
客户端将返回的结果进行重新排序和排名,最后返回给用户。也就是说,ES的一次搜索,是一次scatter/gather过程(这个跟mapreduce也很类似)
然而这其中有两个问题:
第一、 数量问题。 比如, 用户需要搜索"衣服", 要求返回符合条件的前 10 条。 但在 5个分片中, 可能都存储着衣服相关的数据。 所以 ES 会向这 5 个分片都发出查询请求, 并且要求每个分片都返回符合条件的 10 条记录。当ES得到返回的结果后,进行整体排序,然后取最符合条件的前10条返给用户。 这种情况, ES 中 5 个 shard 最多会收到 10*5=50条记录, 这样返回给用户的结果数量会多于用户请求的数量。
第二、 排名问题。 上面说的搜索, 每个分片计算符合条件的前 10 条数据都是基于自己分片的数据进行打分计算的。计算分值使用的词频和文档频率等信息都是基于自己分片的数据进行的, 而 ES 进行整体排名是基于每个分片计算后的分值进行排序的(相当于打分依据就不一样, 最终对这些数据统一排名的时候就不准确了), 这就可能会导致排名不准确的问题。如果我们想更精确的控制排序, 应该先将计算排序和排名相关的信息( 词频和文档频率等打分依据) 从 5 个分片收集上来, 进行统一计算, 然后使用整体的词频和文档频率为每个分片中的数据进行打分, 这样打分依据就一样了。
Elasticsearch在搜索过程中存在以下几个问题:
(1)返回数据量问题
如果数据分散在默认的5个分片上,ES会向5个分片同时发出请求,每个分片都返回10条数据,最终会返回总数据为:5 * 10 = 50条数据,远远大于用户请求。
(2)返回数据排名问题
每个分片计算符合条件的前10条数据都是基于自己分片的数据进行打分计算的。计算分值(score)使用的词频和文档频率等信息都是基于自己分片的数据进行的,而ES进行整体排名是基于排名是基于每个分片计算后的分值进行排序的(打分依据就不一致,最终对这些数据统一排名的时候就不准确了)
============================================================================
再举个例子解释一下【 排名问题】:
假设某学校有一班和二班两个班级。
期末考试之后, 学校要给全校前十名学员发奖金。
但是一班和二班考试的时候使用的不是一套试卷。
一班: 使用的是 A 卷【 A 卷偏容易】
二班: 使用的是 B 卷【 B 卷偏难】
结果就是一班的最高分是 100 分, 最低分是 80 分。
二班的最高分是 70 分, 最低分是 30 分。
这样全校前十名就都是一班的学员了。 这显然是不合理的。
因为一班和二班的试卷难易程度不一样, 也就是打分依据不一样, 所以不能放在一块排名。
【 这个就解释了刚才的排名问题】
如果想要保证排名准确的话, 需要保证一班和二班使用的试卷内容一样。
可以这样做, 把 A 卷和 B 卷的内容组合到一块, 作为 C 卷。
一班和二班考试都使用 C 卷, 这样他们的打分依据就一样了, 最终再根据所有学员的成绩排
名求前十名就准确合理了。
============================================================================
这两个问题, ES 也没有什么较好的解决方法, 最终把选择的权利交给用户, 方法就是在搜索的时候指定 search type。
Elasticsearch在搜索问题的解决思路
(1)返回数据数量问题
第一步:先从每个分片汇总查询的数据id,进行排名,取前10条数据
第二步:根据这10条数据id,到不同分片获取数据
(2)返回数据排名问题
将各个分片打分标准统一
Elasticsearch的搜索类型(SearchType类型)
1、 query and fetch
向索引的所有分片 ( shard)都发出查询请求, 各分片返回的时候把元素文档 ( document)和计算后的排名信息一起返回。
这种搜索方式是最快的。 因为相比下面的几种搜索方式, 这种查询方法只需要去 shard查询一次。 但是各个 shard 返回的结果的数量之和可能是用户要求的 size 的 n 倍。
优点:这种搜索方式是最快的。因为相比后面的几种es的搜索方式,这种查询方法只需要去shard查询一次。
缺点:返回的数据量不准确, 可能返回(N*分片数量)的数据并且数据排名也不准确,同时各个shard返回的结果的数量之和可能是用户要求的size的n倍。
2、 query then fetch( es 默认的搜索方式)
如果你搜索时, 没有指定搜索方式, 就是使用的这种搜索方式。 这种搜索方式, 大概分两个步骤:
第一步, 先向所有的 shard 发出请求, 各分片只返回文档 id(注意, 不包括文档 document)和排名相关的信息(也就是文档对应的分值), 然后按照各分片返回的文档的分数进行重新排序和排名, 取前 size 个文档。
第二步, 根据文档 id 去相关的 shard 取 document。 这种方式返回的 document 数量与用户要求的大小是相等的。
优点:
返回的数据量是准确的。
缺点:
性能一般,并且数据排名不准确。
3、 DFS query and fetch
这种方式比第一种方式多了一个 DFS 步骤,有这一步,可以更精确控制搜索打分和排名。也就是在进行查询之前, 先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块, 再执行后面的操作、
优点:
数据排名准确
缺点:
性能一般
返回的数据量不准确, 可能返回(N*分片数量)的数据
4、 DFS query then fetch
比第 2 种方式多了一个 DFS 步骤。
也就是在进行查询之前, 先对所有分片发送请求, 把所有分片中的词频和文档频率等打分依据全部汇总到一块, 再执行后面的操作、
优点:
返回的数据量是准确的
数据排名准确
缺点:
性能最差【 这个最差只是表示在这四种查询方式中性能最慢, 也不至于不能忍受,如果对查询性能要求不是非常高, 而对查询准确度要求比较高的时候可以考虑这个
DFS 是一个什么样的过程?
从 es 的官方网站我们可以发现, DFS 其实就是在进行真正的查询之前, 先把各个分片的词频率和文档频率收集一下, 然后进行词搜索的时候, 各分片依据全局的词频率和文档频率进行搜索和排名。 显然如果使用 DFS_QUERY_THEN_FETCH 这种查询方式, 效率是最低的,因为一个搜索, 可能要请求 3 次分片。 但, 使用 DFS 方法, 搜索精度是最高的。
总结一下, 从性能考虑 QUERY_AND_FETCH 是最快的, DFS_QUERY_THEN_FETCH 是最慢的。从搜索的准确度来说, DFS 要比非 DFS 的准确度更高
转载:https://www.cnblogs.com/zlslch/p/6438352.html
智能推荐

[学习笔记]MATPLOTLIB.PYPLOT
本文记录matpltlib库中主要的绘图命令,列出各类型绘图的简单案例。 matplotlib.pyplot 1.各类型绘图命令 1.1 绘图类型总览及查看方法 1.2汇总案例 1.3 plot函数 1.各类型绘图命令 1.1 绘图类型总览及查看方法 图形 函数 曲线图 plot(data) 灰度图 hist(data) 散点图 scatter(data) 箱式图 boxplot(data) 直方...

SHELL脚本小练习
shell脚本小练习 1.整数的四则运算 代码如下: 运行截图: 2.输入一个分数,返回其等级 代码如下: 运行截图: 3.截取出/etc/passwd文件里面所有的用户名,然后输出hello,用户名 代码如下: 运行截图: 4.扫描局域网内有哪些服务器开放了80和3306端口 代码如下: 运行截图: 5.扫描出局域网内正在使用的ip地址 代码如下: 运行截图: 6.批量生成用户密码,用户名由用户...

FLUTTER 报错COULD NOT DETERMINE THE DEPENDENCIES OF TASK :APP:COMPILEDEBUGJAVAWITHJAVAC
运行一个GitHub上的flutter项目报错Could not determine the dependencies of task ':app:compileDebugJavaWithJavac'。 网上查了一下一种是说删除android文件夹下的.gradle文件夹,然后再项目根目录下执行flutter clean命令,试了一下对我来说没有用处。 尝试另外一种,因为伟大的墙造成的无法访问Go...

MYSQL配置后无法在DOS里运行
异常:mysql卸载后重新安装后无法在Dos里运行,配置mysql无任何问题,异常原因可能没有mysql.ini的配置文件 一:解决步骤 1:找到mysql下的配置文件 在C:\Program Files\MySQL\MySQL Server 5.6找到默认配置文件my-default.ini(我这里使用的是5.6版本的) 没有的话自己新建一个名为my.ini的文件 内容如下,放在该目录下 2:修...

JUPYTER NOTEBOOK远程登陆
引言 最近买了台性能比较好的主机,准备在上面跑跑算法之类的,本来想做个利用tensorflow实现word2vec的demo,但是我一直在笔记本上办公,笔记本上有没有安装tensorflow环境,于是我配置了主机jupyter notebook环境,从而实现了远程访问jupyter-notebook并编码的功能。现总结如下 登陆远程服务器 这里我设置了SSH登陆 生成配置文件 这句命令会在用户目录...
猜你喜欢


面向对象学习总结--何为类、引用,类实例出对象的过程和原理
概述:在上一篇面向对象学习总结中主要围绕着何为对象展开,浅析了对象如何抽象出类。接下来,主要讲围绕着类如何实例出对象作一些学习总结。 涉及到的关键词:抽象,类,类型,实例,引用变量,对象引用,引用,指向,内存地址,栈,堆 何为类 类: 将所有具有相同的属性和方法的对象归属为一个类。 相当于:类是对象的模版,从类中刻印出l来的对象都是一个模子的。 在上篇总结中有提到,这个定义类的过程就叫抽象: 1....

轻量级性能测试工具 WRK-安装
wrk 是一款针对 Http 协议的基准测试工具,它能够在单机多核 CPU 的条件下,使用系统自带的高性能 I/O 机制,如 epoll,kqueue 等,通过多线程和事件模式,对目标机器产生大量的负载。 Wrk安装步骤如下: 以CentOS为例,依次执行如下命令: 验证是否安装成功,在命令行输入命令: 输入如图信息表示安装成功。 下一篇博文具体说明wrk工具如何使用。...

THINKING IN JAVA 之 多线程 3
Cooperation between tasks wait() and notifyAll() It’s important to understand that sleep() does not release the object lock when it is called, and neither does yield(). On the other hang, when a...

数据结构实验之二叉树一:树的同构
数据结构实验之二叉树一:树的同构 Time Limit: 1000MS Memory Limit: 65536KB Problem Description 给定两棵树T1和T2。如果T1可以通过若干次左右孩子互换就变成T2,则我们称两棵树是“同构”的。例如图1给出的两棵树就是同构的,因为我们把其中一棵树的结点A、B、G的左右孩子互换后,就得到另外一棵树。而图2就不是同构的。...
