YOLO算法-论文笔记
2017-11-29 19:59 张小贤TT 阅读(5262) 评论(0) 收藏 举报最近看了Deep Learning中关于目标检测的一些内容,其中大部分的内容都是Coursera上吴恩达卷积神经网络的课程,没看过的可以看一下,讲的很好,通俗易懂,只是在编程
作业中关于网络训练以及具体的细节没有体现,可能是网络太复杂,不太好训练。。于是想看一下原作者的论文,看看有没有实现的细节,虽然论文里也米有具体的实现,但是啃下
一篇论文还是挺开心的。写博客只是阶段性的复习一下自己的学习成果,同时也留个纪念,流水账一样,勿喷
论文地址:https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf
在谈论YOLO算法之前先说一下Bounding box,假设我们要检测的图像只有一个物体,就是一张图像中只会出现一个物体,我们都很熟悉,因为在之前做classfication(分类)
问题的时候处理的就是单目标,我们能不能在做分类问题的时候同时也输出检测的目标的位置信息呢?也就是localization(定位),答案是可以的,例如我们已经训练好了一个
CNN模型能够很好的完成分类问题,那么我们也可以改变一下模型的输出,即给模型增加几个输出:(Pc, bx, by, bh, bw, c1, c2, c3), 其中Pc表示图像中是否存在目标,bx, by, bh, bw
分别表示Bounding box的中心点坐标,宽度和高度,假设我们原本的分类器只训练了人, 车, 狗三种分类,则c1, c2, c3对应人, 车, 狗三种分类的概率,(原谅我这三个类别选择
的可能不是很恰当),下面是关于分类,定位,和目标检测的一些联系

说完了Bounding box,下面来说说YOLO算法,You Only Live Once...
在论文的开始,作者列出了模型的一些优缺点:
1.模型简单速度快(见下图,确实挺简单,图像》》卷积网络》》输出),每秒45帧以上,能够达到实时性的要求

2.算法能够‘’考虑‘’到整张图片的所有信息,YOLO reasons globally about the image when
making predictions ,词穷了我,不知道怎么翻译最好。这一点要比其他基于RPN算法的目标检测算法要好,对于背景物体的识别,有更高的准确率
3.YOLO能够学习到目标的generalizable representations,应该理解成泛化能力比较强吧
当然,作者也说了关于YOLO的缺点,就是准确率可能稍稍低了一点。。
==================================================================================================================================================
We unify the separate components of object detection into a single neural network. Our network uses features from the entire image to predict each bounding box. It
also predicts all bounding boxes across all classes for an image simultaneously. This means our network reasons globally about the full image and all the objects in the image.
The YOLO design enables end-to-end training and realtime speeds while maintaining high average precision
Our system divides the input image into an S × S grid. If the center of an object falls into a grid cell, that grid cells responsible for detecting that object
YOLO模型支持端到端的训练,这样会减少很多不必要的工作,而整个模型其实就是一个卷积神经网络
首先,对于输入的图片,将其分成s*s个网格,如果图像中目标的中心点落在网格内,可以表示为这个网格检测到了目标
Each grid cell predicts B bounding boxes and confidence scores for those boxes. These confidence scores reflect how confident the model is that the box contains an object and
also how accurate it thinks the box is that it predicts. Formally we define confidence as Pr(Object) ∗ IOUtruth pred. If no object exists in that cell, the confidence scores should be
zero. Otherwise we want the confidence score to equal the intersection over union (IOU) between the predicted box and the ground truth
Each bounding box consists of 5 predictions: x, y, w, h, and confidence. The (x; y) coordinates represent the center of the box relative to the bounds of the grid cell. The width
and height are predicted relative to the whole image. Finally the confidence prediction represents the IOU between the predicted box and any ground truth box.
Each grid cell also predicts C conditional class probabilities, Pr(Classij\Object). These probabilities are conditioned on the grid cell containing an object. We only predict
one set of class probabilities per grid cell, regardless of the number of boxes B.
At test time we multiply the conditional class probabilities and the individual box confidence predictions,
每个网格会预测出B个Bounding box,和这些Bounding box的confidence scores,这个得分反应的是box包含物体的置信度和box预测的正确率,把confidence定义为![]()
如果目标存在,则confidence =![]() ,如果不存在,则为0。同时每个BOX也会预测出x, y, w, h四个量,x,y表示物体中心点的坐标,w,h表示宽度和高度。每个网格也会输出每个
,如果不存在,则为0。同时每个BOX也会预测出x, y, w, h四个量,x,y表示物体中心点的坐标,w,h表示宽度和高度。每个网格也会输出每个
类别对应的可能:Pr(Classij\Object), 是一个条件概率。
作者还给出下面这个公式表示每个类别对应的confidence score
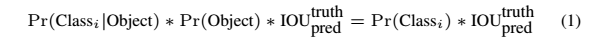

For evaluating YOLO on PASCAL VOC, we use S = 7,B = 2. PASCAL VOC has 20 labelled classes so C = 20.Our final prediction is a 7 × 7 × 30 tensor
下面是作者的网络的设计,顺便说一下,在读到这里的时候自己也仿照这搭建一个网络,当然只是做分类问题,结果手头图片太少,分分钟过拟合

关于网络的训练有几点细节,
每个grid有30维,这30维中,8维是回归box的坐标,2维是box的confidence,还有20维是类别
其中坐标的x,y用对应网格的offset归一化到0-1之间,w,h用图像的width和height归一化到0-1之间。
在实现中,最主要的就是怎么设计损失函数,让这个三个方面得到很好的平衡。作者简单粗暴的全部采用了sum-squared error loss来做这件事。这种做法存在以下几个问题:
It weights localization error equally with classification error which may not be ideal. Also, in every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells
towards zero, often overpowering the gradient from cells that do contain objects. This can lead to model instability,causing training to diverge early on.
To remedy this, we increase the loss from bounding box coordinate predictions and decrease the loss from confidence predictions for boxes that don’t contain objects. We use two parameters, λcoord
and λnoobj to accomplish this. We set λcoord = 5 and λnoobj = 0.5
第一,8维的localization error和20维的classification error同等重要显然是不合理的
第二,如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。
解决办法
更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为在pascal VOC训练中取5
对没有object的box的confidence loss,赋予小的loss weight,记为在pascal VOC训练中取0.5
有object的box的confidence loss和类别的loss的loss weight正常取1
Sum-squared error also equally weights errors in large boxes and small boxes. Our error metric should reflect that small deviations in large boxes matter less than in small
boxes. To partially address this we predict the square root of the bounding box width and height instead of the width and height directly
为了缓和这个问题,作者用了一个比较取巧的办法,就是将box的width和height取平方根代替原本的height和width。


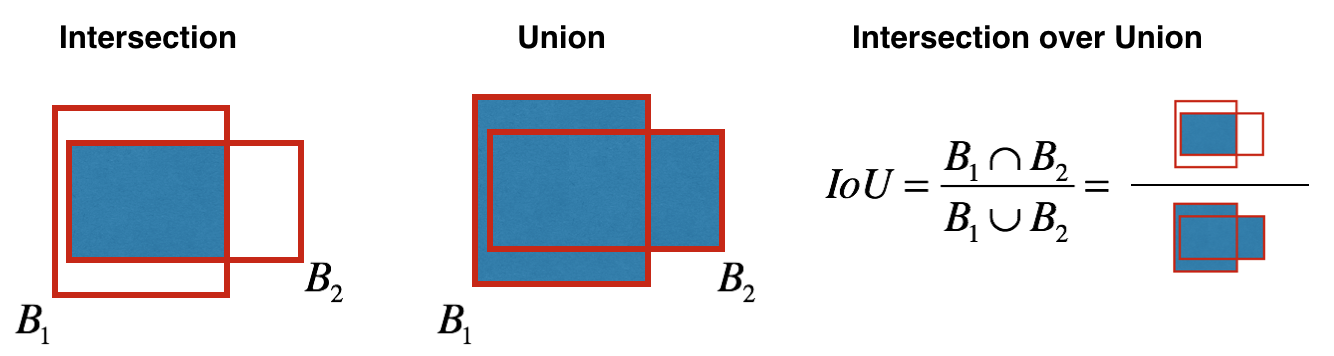
关于论文就说这么多,这里还想说一些关于IOU和非极大值抑制的理解,下图出自吴恩达老师的PPT
===================================================================================================================================================
因为YOLO会把图片分成s*s个网格,那么相邻的网格内跟肯定会有box圈到的同一个目标,就算在之前的步骤中把一些class confidence scores 低的过滤掉之后还是会得到类似下面的结果

那么该怎么办呢,非极大值抑制就要发挥作用了,首先,在每个类别中选出得分最高的,每个类别中其余的和选出来的这些做IOU运算(同类别之间运算),设定一个IOU_THRESHOLD
把结果中大于IOU_THRESHOLD的pass掉(因为IOU大说明重叠的部分大,表明box之间很有可能是同一个目标),然后在剩下的box中再次作同样的处理。多做几次之后就能得到满意的结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号