
四.WebDriver浏览器属性
(一)获取测试的地址
在测试中,由于实际的需求,我们需要获取被测试的地址,比如一个很具体的业务场景,验证用户登录一个系统成功后,怎么判断该用户是登录成功了呢?那么判断的依据可以分为两部分进行解答,一种是用户登录成功后显示的用户昵称,来获取它的文本信息,来验证昵称是否是自己期望的,另外一种方式是获取登录成功后的地址,看返回结果和实际是否一致

from selenium.webdriver.common.by import By from selenium import webdriver import time driver=webdriver.Chrome() driver.get('http://www.baidu.com') #获取当前的地址,登录后判断是否登陆成功 print(driver.current_url) time.sleep(2) driver.close()

(二)获取当前页面代码
使用到的方法为page_source,该方法为特性方法,所谓特性方法可以简单的理解为它是类里面的一个方法,但是该方法它是属于只读属性,所以所有的特性方法在调用的时候都是没有()的,这点其实很好的理解,如果一个方法有了形式参数,那么在这个方法调用的时候必然需要给这个方法的形式参数赋予实际的参数,但是特性方法是调用的时候没有(),那么也就无法给形式参数值,这点需要特别的注意,特性方法使用到的装饰器为@property。page_source方法实战的具体测试代码如下:
from selenium import webdriver import time driver=webdriver.Chrome() driver.get('http://www.baidu.com') #获取当前的源码,做网络爬虫使用 print(driver.page_source) time.sleep(2) driver.close()
(三)获取当前的Title
案例测试代码如下所示:
from selenium import webdriver import time driver=webdriver.Chrome() driver.get('http://www.baidu.com') #获取title,属于面向对象的特性方法,只读属性 print(driver.title) time.sleep(2) driver.close()

(四)页面的前进和后退
页面的前进使用到的方法为forward(),后面的后退使用到的方法为back(),这主要应用于很多的业务场景,比如在第一次打开的是百度,后面由于测试的需求,打开的是bing搜索页面,那么可以回退回去,当然也可以再次前进到bing搜索的页面,下面
from selenium import webdriver import time #浏览器的前进回退、窗口最大化 driver=webdriver.Chrome() #窗口最大化 driver.maximize_window() driver.get('http://www.baidu.com') time.sleep(1) driver.get('http://www.bing.com') time.sleep(1) #回退 driver.back() print(driver.current_url) time.sleep(1) #前进 driver.forward() print(driver.current_url) time.sleep(1) driver.close()
(五)多窗口实战
如果是2个以上的窗口,是很难判断的,因为缺少判断的基准,多窗口的解决步骤可以具体的描述为:
-
先获取当前窗口句柄
-
然后点击链接,打开一个新的窗口句柄
-
然后获取到所有的窗口句柄
-
循环所有的窗口句柄,判断如果不是当前窗口句柄,那么就切换到新的窗口句柄(如果当前的,就只能是新的窗口了)
-
切换到新的窗口后,进行操作完成后,然后关闭新的窗口,再切换到当前窗口句柄
下面就以sina的邮箱为案例来演示这部分,比如注册页面被注册的邮箱为空的错误提示信息,案例测试代码如下:
from selenium.webdriver.common.by import By from selenium import webdriver import time #多窗口切换 driver=webdriver.Chrome() driver.maximize_window() driver.get('http://www.baidu.com') time.sleep(1) #获取当前窗口 nowHandler=driver.current_window_handle driver.find_element(By.LINK_TEXT,'新闻').click() time.sleep(1) #获取所有窗口 allHandlers=driver.window_handles #对所有的窗口进行循环,判断当前是窗口不是新的窗口,切换到新窗口。在新窗口输入内容证明切换成功 for handler in allHandlers: if handler!=nowHandler: driver.switch_to.window(handler) time.sleep(1) driver.find_element(By.ID,'ww').send_keys('如何一夜暴富') time.sleep(1) driver.close() #切换到当前窗口 driver.switch_to.window(nowHandler) time.sleep(1) driver.find_element(By.ID,'kw').send_keys('嘤嘤嘤嘤嘤') time.sleep(1) driver.close()
五.WebElement类方法实战
(一)clear()
from selenium.webdriver.common.by import By from selenium import webdriver import time #清空,so是对象 driver=webdriver.Chrome() driver.maximize_window() driver.get('http://www.baidu.com') time.sleep(1) so=driver.find_element(By.ID,'kw') so.send_keys('刘亦菲') time.sleep(2) so.clear() driver.close()
(二)get_attribute()
from selenium.webdriver.common.by import By from selenium import webdriver import time #获取元素属性的值,input写的内容都是写到value的,可以在input内部手动添加value driver=webdriver.Chrome() driver.maximize_window() driver.get('http://www.baidu.com') time.sleep(1) so=driver.find_element(By.ID,'kw') so.send_keys('一夜暴富') time.sleep(2) print(so.get_attribute('value')) print(so.get_attribute('maxlength')) driver.close()
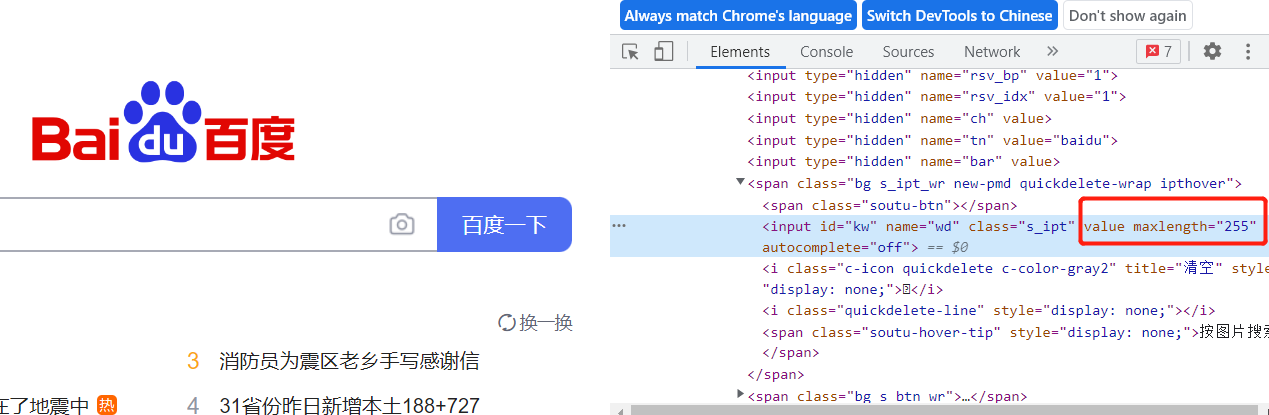

(三)is_displayed()
from selenium.webdriver.common.by import By from selenium import webdriver import time #是否可见 driver=webdriver.Chrome() driver.maximize_window() driver.get('http://www.baidu.com') time.sleep(1) obj=driver.find_element(By.LINK_TEXT,'关于百度') print(obj.is_displayed()) driver.close()
(四)is_enabled()
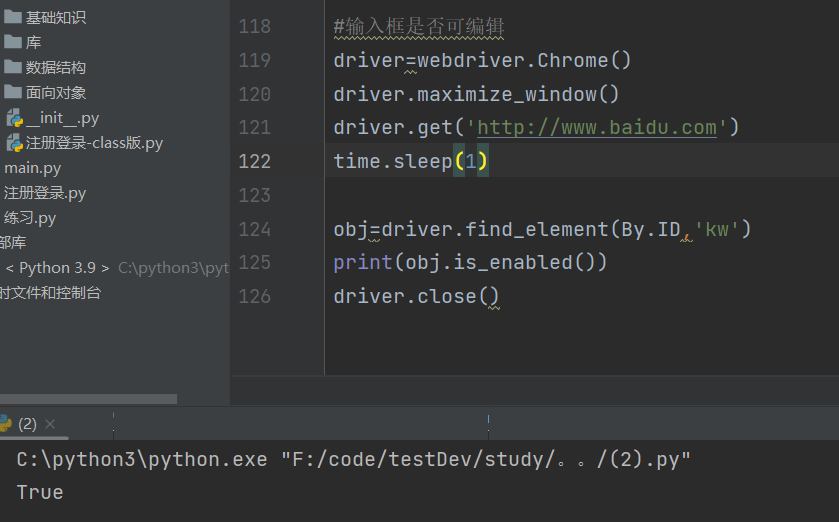
from selenium.webdriver.common.by import By from selenium import webdriver import time #输入框是否可编辑 driver=webdriver.Chrome() driver.maximize_window() driver.get('http://www.baidu.com') time.sleep(1) obj=driver.find_element(By.ID,'kw') print(obj.is_enabled()) driver.close()
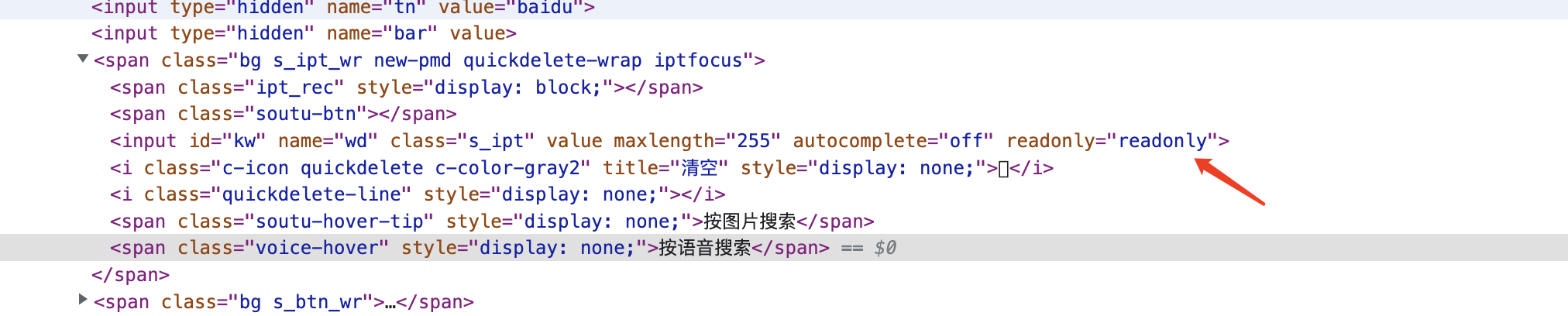
在input加入readonly输入框就不可编辑了
(五)is_selected()
该方法返回的结果信息是是否可选中,使用的场景主要为在登录的案例中,一般记住登录都是默认选中的,如下所示
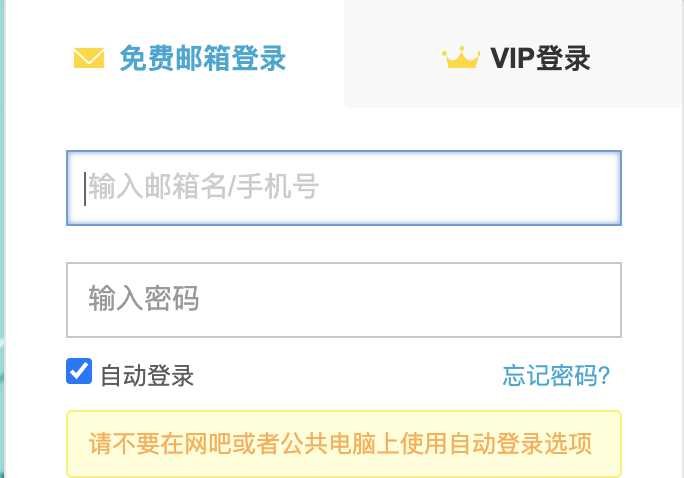
sina的邮箱自动登录是勾选的,但是在UI自动化测试中我们需要校验这部分是否勾选,那么这个时候使用的方法就是该方法,结合该案例,测试的代码为
from selenium.webdriver.common.by import By from selenium import webdriver import time #可选择.比如自动登录的是否勾选上了,is 系列都是判断 driver=webdriver.Chrome() driver.maximize_window() driver.get('https://mail.sina.com.cn') time.sleep(1) obj=driver.find_element(By.ID,'store1') print(obj.is_selected()) time.sleep(2) obj.click() print(obj.is_selected()) time.sleep(2) driver.close()
六.Select类方法实战
(一)源码分析
在UI的自动化测试实战中,如果遇到下拉框的选择,我们可以使用Select类里面的方法来具体进行定位和解决。下面使用HTML的代码来写一个下拉框的页面交互,从直观上知道下拉框的交互到底是怎么样的,HTML的源码信息如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <center> 喜欢的编程语言: <select id="nr"> <option value="" selected>请选择您喜欢的编程语言</option> <option value="Python">Python语言</option> <option value="Go">Go语言</option> <option value="Java">Java语言</option> </select> </center> </body> </html>
如上是HTML的源代码,下面具体看看交互的信息,如下所示:
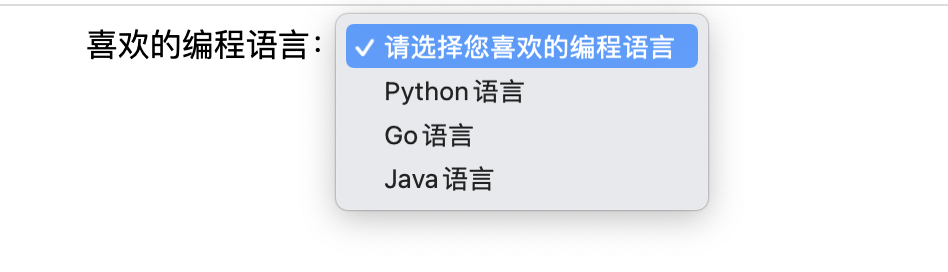
在这样一个下拉框的交互中,我们需要获取到下拉框的选项,来定位下拉框的内容,这是我们在工作里面的具体交互,WebDriver的测试框架中,我们可以使用Select类来处理下拉框的交互。
元素定位的方式步骤具体为:
-
首先获取下拉框的属性,当然这些属性可以是id,name以及xpath的信息
-
拿到下拉框属性的对象,然后实例化Select的类
-
下来调用该类里面的方法来获取下拉框选项里面的具体内容
在Select的类里面,针对获取下拉框选项里面的内容,使用到的方法主要是索引方式,和文本信息以及text的方式。
1.select_by_text()
select_by_text()的方法是通过文本信息来定位的,比如下拉框还是想选择Go,那么它的文本信息其实就是“Go语言”,见这部分的案例实战代码:
2.select_by_index()
select_by_index()的方法是通过索引的方式,如我们在上面的交互中,我们想选择下拉框中的Go语言,它是在第三位,那么它的索引就是2,因为索引是从0开始,下面的代码案例主要是以索引的方式来进行定位的,具体案例实战代码如下:
3.select_by_value()
select_by_value()方法是通过value的方式来进行定位,也就是标签中option里面的value属性来进行定位,比如我们还是Go语言,那么它的value的值就是“Go”,具体见如下的案例代码:
driver=webdriver.Chrome() driver.maximize_window() driver.get('file:///C:/Users/%E5%B0%8F%E5%A6%96%E5%A5%B3/Desktop/%E8%BD%AF%E4%BB%B6%E6%B5%8B%E8%AF%95%E8%B5%84%E6%96%99/select(1).html') time.sleep(1) sel=driver.find_element(By.ID,'nr') obj=Select(sel) time.sleep(1) #文本模式 obj.select_by_visible_text('Go语言') #索引模式 # obj.select_by_index(2) #value模式 # obj.select_by_value('Go') time.sleep(2) driver.close() #以上是标准的select代码选择才可以定位到
以上是标准的select代码选择才可以定位到。
(二)实际工作下拉框实战
在实际的工作中,前端程序员总是不遵守规则的,也就是说实现的下拉框的选项并不是很标准的select,那么这个时候到底如何解决了,比如:
#针对很多的下拉框交互,代码不标准需要使用点击的方法。大多数都是这个方法 driver=webdriver.Chrome() driver.maximize_window() driver.get('https://www.lagou.com/') time.sleep(5) #输入搜索关键字 driver.find_element(By.ID,'search_input').send_keys('测试开发工程师') time.sleep(2) driver.find_element(By.ID,'search_button').click() time.sleep(3) #点击学历要求 driver.find_element(By.XPATH,'//*[@id="jobsContainer"]/div[2]/div[1]/div[1]/div[2]/div/ul/li[2]/div/span').click() time.sleep(3) #选择大专 driver.find_element(By.XPATH,'//*[@id="jobsContainer"]/div[2]/div[1]/div[1]/div[2]/div/ul/li[2]/div/div/ul[2]/li[1]/span').click() time.sleep(5)
针对这种下拉框的选择,到底应该如何来进行定位和操作了,其实也是很简单的,它的步骤为:
-
-
然后再选择下拉框中需要选择的项,定位到后进行点击,就能够定位到了



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架