

四.python基础语法
1、交互式编程
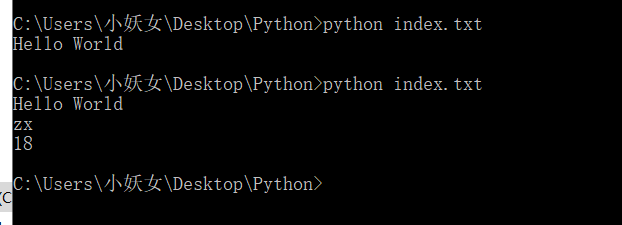
简单来说,就是直接在终端中运行解释器,而不使用文件名的方式来执行文件。 交互式编程不需要创建脚本文件,是通过Python解释器的交互模式来进行编写代码。Python解释器它能对输入的Python代码进行解释和执行。进入创建的文件所在的路径针对使用Python代码编写的文件进行解释 在cmd命令行中输入Python命令即可启动交互式编程,如下图所示:

2、脚本式编程
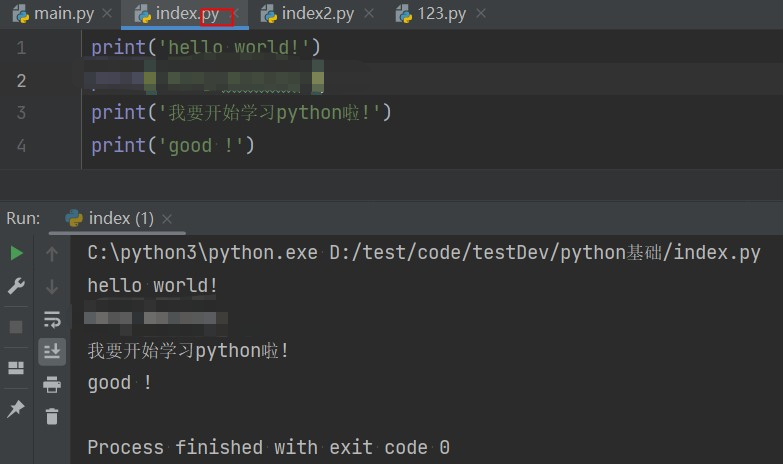
通过脚本参数调用解释器开始执行脚本,直到脚本执行完毕。当脚本执行完成后,解释器不再有效。 我们写一个简单的Python脚本程序。所有Python文件将以.py为扩展名,如下图所示:
3.Python变量
3.1变量
变量是可以赋给值的标签,也可以说变量指向特定的值。 每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。 等号 = 用来给变量赋值。 等号 = 运算符左边是一个变量名,等号 = 运算符右边是存储在变量中的值。
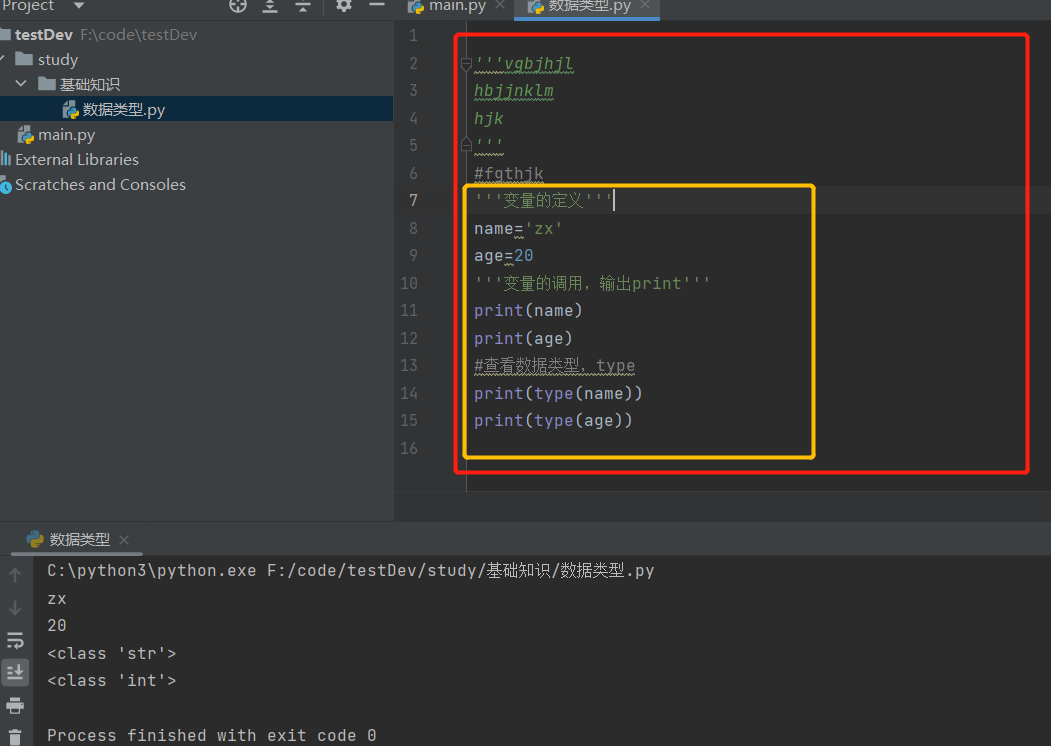
变量的生命周期:当一个变量调用的时候,会在内存当中给这个变量分配地址,比如name分配zx,age分配20,当变量调用结束后,分配的内存地址也会消失。print输出
name=‘zx’ print(name) 意思是添加了一个名为name的变量。每个变量都指向一个值,与该变量相关的信息。在这里指向的值为文本‘zx’
注释:1.多行注释’‘’ 规划‘’‘ 2.单行注释# 注释之后运行不受影响
3.2查看变量的数据类型
查看一个对象(变量)的数据类型,使用的关键字是type
4种数据类型:
-
-
str :姓名、地址等
-
bool:True/False:存储的变量表示的是真或者是假,而且这两个首字母必须是大写的
-
float :薪资,变量是带有数字的小数点
3.3变量的命名规则

-
-
变量名只能包含字母、数字和下划线。变量名只能以字母或下划线打头,但不能以数字打头。可以message_1,但不能将其命名为1_message。
-
变量名不能包含空格,但能是用下划线来分隔其中的单词。可以greeting_message,但变量名greeting message会引发错误。
-
不要将Python关键字和函数名用作变量名,即不要使用Python保留用于特殊用途的单词。
-
变量名应既简短又具有描述性。例如name比n好。
-
慎用小写字母l和大写字母O,因为它们可能被人错看成数字1和0。
-
就目前而言,应使用小写的Python变量名。大写字母在变量名中有特殊的含义。
-
骆驼式命名法(Camel-Case)又称驼峰式命名法, 小驼峰法 变量一般用小驼峰法标识。驼峰法的意思是:除第一个单词之外,其他单词首字母大写。譬如:int myStudentCount; 变量myStudentCount第一个单词是全部小写,后面的单词首字母大写。 大驼峰法 相比小驼峰法,大驼峰法(即帕斯卡命名法)把第一个单词的首字母也大写了。常用于类名,命名空间等。譬如public class DataBaseUser;
4.基础操作语法
输入:input 输出:print 换行:\n 批量注释:全选Ctrl+/ 查看数据类型:type()
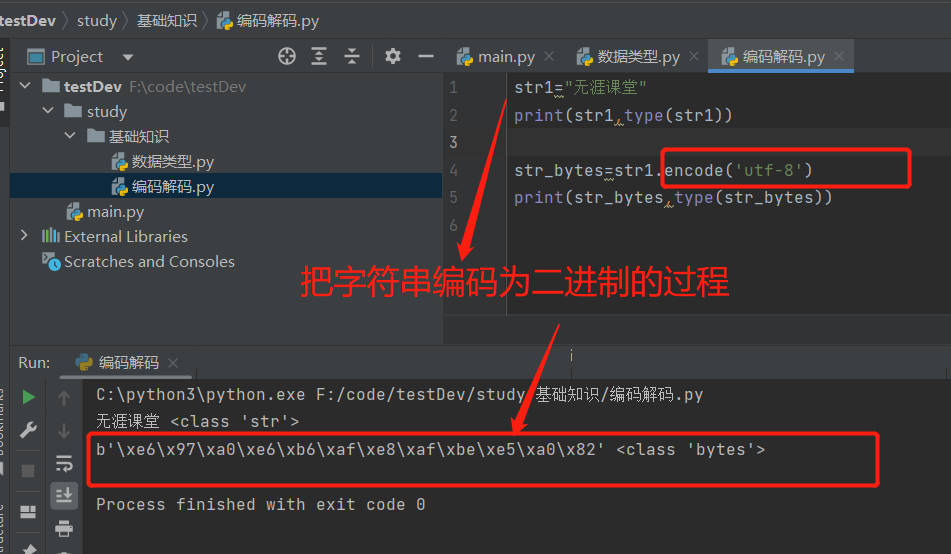
5.编码解码的过程
-
Python的默认编码是ascll,Python3 的默认编码是unicode
-
编码:encode() 把字符串转为bytes(二进制)数据类型的过程(转为二进制的过程) 解码:decode() 把bytes转为字符串的过程
-
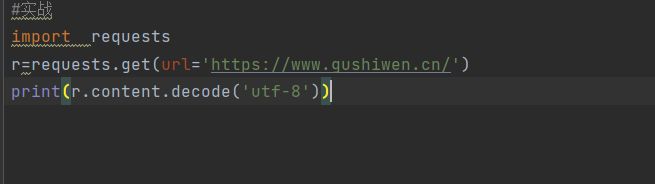
编码解码在网络爬虫中的应用,从很多数据中筛选出自己想要的数据
-
安装爬虫工具:pip install requests ——做网络爬虫的工具
6.控制流与逻辑判断
在Python⾥⾯,控制流我们会使⽤到For和While,判断主要值的是if
6.1while循环
-
-
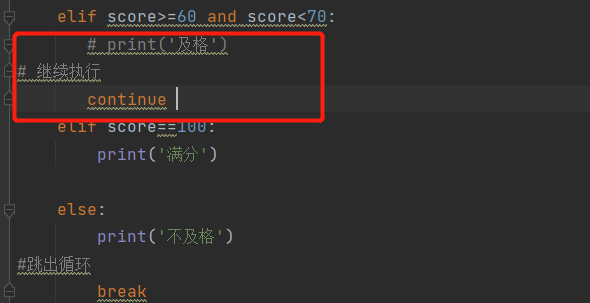
break:跳出循环
-
continue:当不想输入上一段的结果时,在后边加上此命令,就会默认跳过继续执行后边的任务,否则报错。
比如,不输出60——70的结果,需加此命令继续执行

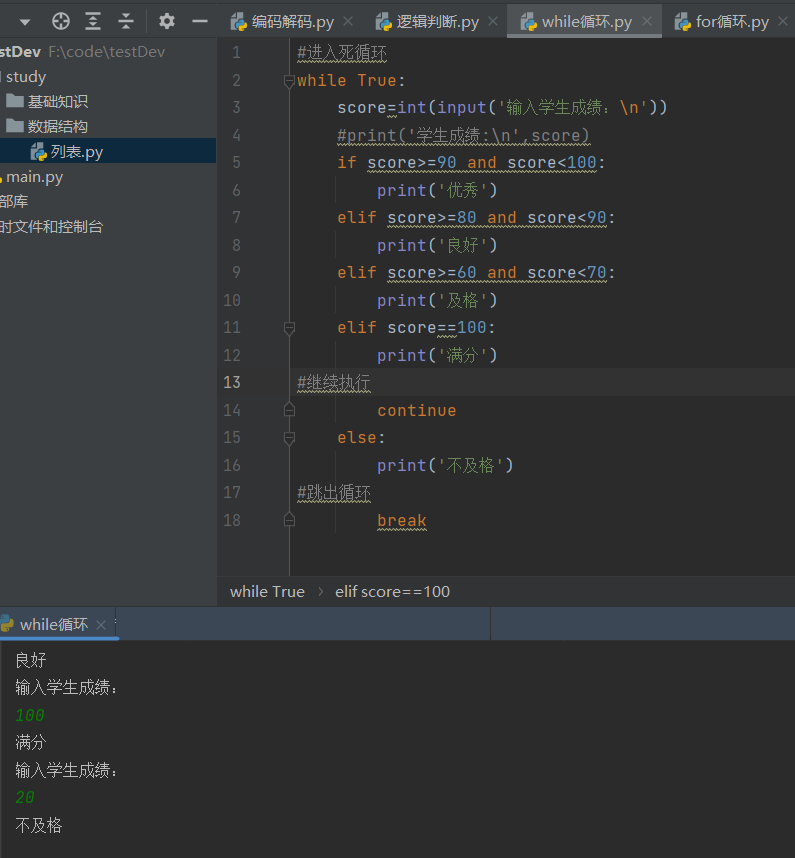
#进入死循环 while True: score=int(input('输入学生成绩:\n')) #print('学生成绩:\n',score) if score>=90 and score<100: print('优秀') elif score>=80 and score<90: print('良好') elif score>=60 and score<70: print('及格') elif score==100: print('满分') #继续执行 continue else: print('不及格') #跳出循环 break
for … in … :
作用是在每一次的循环中,依次将in关键字后面序列变量的一个元素赋值给for关键字后的变量。
注意:
-
循环的次数是由字符串的长度决定的
-
这里"item"是变量,可以用任何字母来代它,“for”和“in”是关键字。
6.3enumerate()得到对象的索引和值
for....in enumerate():
也可以对索引进行判断
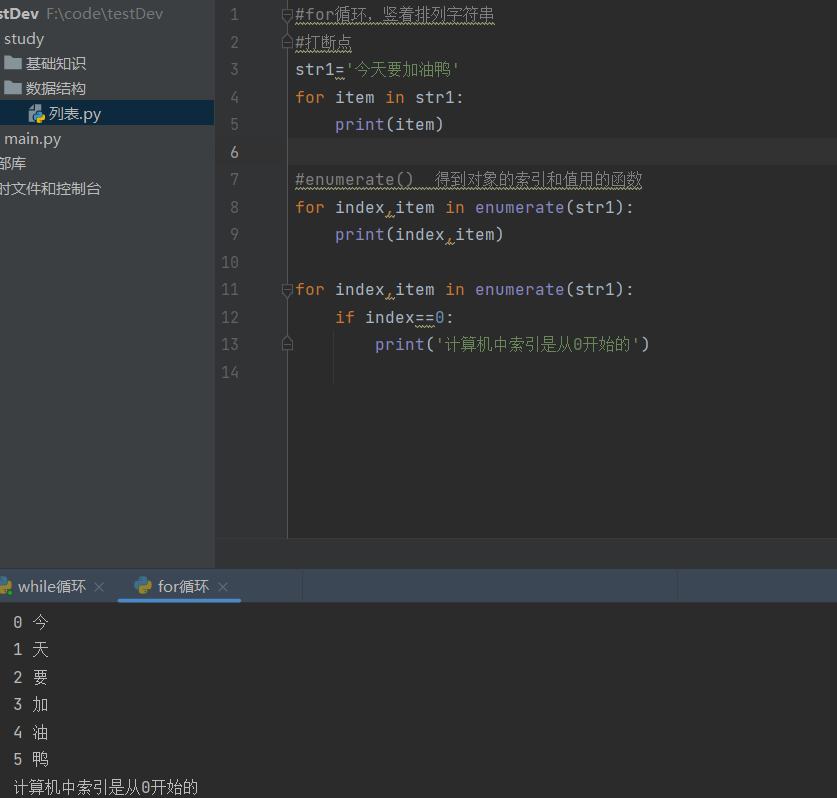
#for循环,竖着排列字符串 #打断点 str1='今天要加油鸭' for item in str1: print(item) #enumerate() 得到对象的索引和值用的函数 for index,item in enumerate(str1): print(index,item) for index,item in enumerate(str1): if index==0: print('计算机中索引是从0开始的')
7.字符串的格式化
-
python字符串格式化的意思就是在字符串中使用变量,通常用format函数格式化字符串的用法。
-
因为在python中我们会遇到一个问题,问题是如何输出格式化的字符串。我们经常会输出类似"各位xx辖区市民:为切实保障人民群众身体健康和生命安全,xx区疫情防控指挥部决定于xx月xx日上午xx"而xxx的内容都是根据变量变化的,所以,需要一种简便的格式化字符串的方式。在python中,我们用传统的%或者{}实现格式化字符串。
-
%s:字符串,也是万能的 %d:整型 %f:浮点型
注意:在字符串格式化的输出中,int的数据类型可以使⽤%s来表示,但是str的数据类型,不能使⽤%d来表示
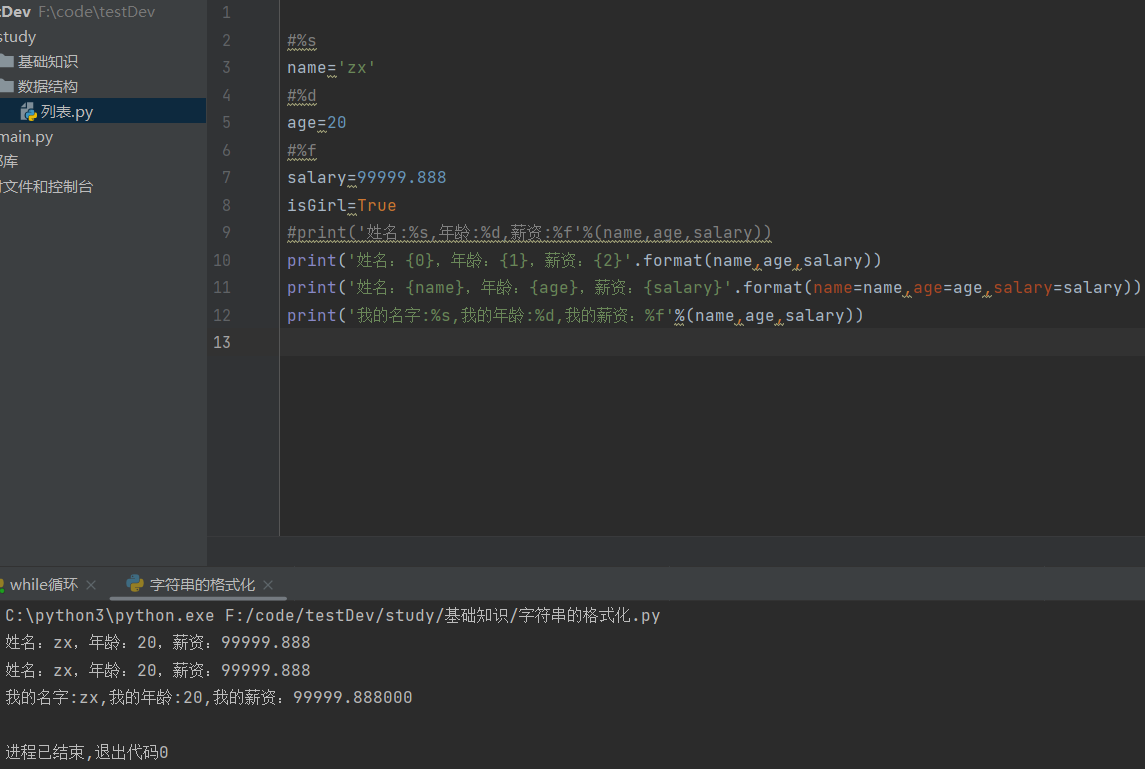
#%s name='zx' #%d age=20 #%f salary=99999.888 isGirl=True print('姓名:{0},年龄:{1},薪资:{2}'.format(name,age,salary)) print('姓名:{name},年龄:{age},薪资:{salary}'.format(name=name,age=age,salary=salary)) print('我的名字:%s,我的年龄:%d,我的薪资:%f'%(name,age,salary))
8.字符串详解
1.获取对象长度len
获取对象的长度:len()函数
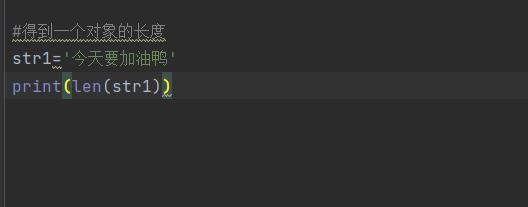
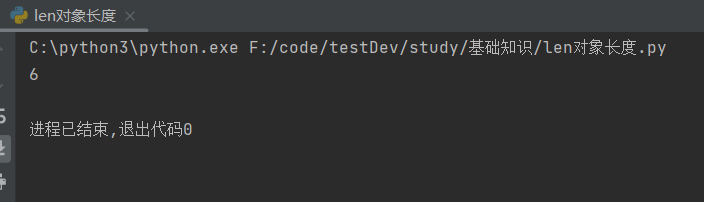
#得到一个对象的长度 str1='今天要加油鸭' print(len(str1))
2.大小写的转换
-
把小写转换为大写: .upper()函数,:判断是不是大写,is是判断:.isupper()
-
把大写转换为小写: .lower()函数,is是判断:.islower()
#把字符串转为大写upper函数 str1='hello' print(str1.upper()) print(str1.upper().isupper()) #把大写的字符串转为小写lower函数 str2='HELLO' print(str2.lower()) print(str2.lower().islower())


3.判断字符串开头结尾
-
-
判断字符串以什么结尾:.endswith()函数
str1='hello' #以什么开头,Python里边只会判断对错 print(str1.startswith('h')) #以什么结尾 ,大小写都有差别 print(str1.endswith('O'))

4.获取字符串里边的元素索引
查看字符串里面对象的索引,是线性查找的思路,所谓线性查找是指计算机一旦检索到了该对象,就停止再去检索该对象第二、三、四....次出现
.index()函数
#获取字符串里边的元素索引index(排序是从0开始的),线性查找 str1='hello' print(str1.index('l'))
5.字符串的替换
#替换对象的内容 str1='hello' print(str1.replace('ello','i,fairy'))
6.字符串的拆分合并
字符串的拆分:.split()函数,它的数据类型是列表 字符串的合并:.join()函数,它的数据类型为str
str4='go,java,python' #字符串拆分split,变成列表list,’‘里边是拆分方式 str_list=str4.split(',') print(str_list,type(str_list)) #列表的合并join变成字符串,’‘里边是合并方式 list_str=','.join(str_list) print(list_str,type(list_str))
7.字符串取消首尾空格
字符串的取消空格:.strip()函数
#取消空格,仅限前后 str3=' water' print(str3.strip())
8.字符串查找索引
#字符串的查找,返回的是索引,如果收尾是有空格的,空格也占索引序号 print(str1.find('l'))
#字符串的循环 str1='hello' for item in str1: print(item)
(一)列表
所谓列表,我们可以简单的把它理解为按照索引存放各种集合,在列表中,每个位置代表⼀个元素。在Python中, 列表的对象⽅法是list类提供的,列表是有序的。列表的特点具体如下:
-
可存放多个值
-
按照从左到右的顺序定义列表元素,下标从0开始顺序访问
-
列表是有序的
-
列表也是可变化的,也就是说可以根据列表的索引位置来修改列表的值
列表实战操作
1.列表的添加append、insert
-
append:默认把添加的元素添加到最后一位
-
insert:按照索引添加
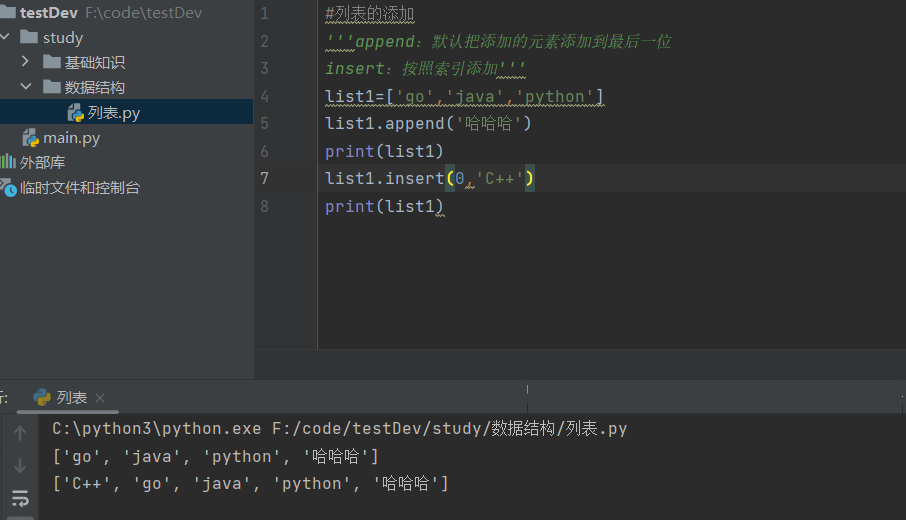
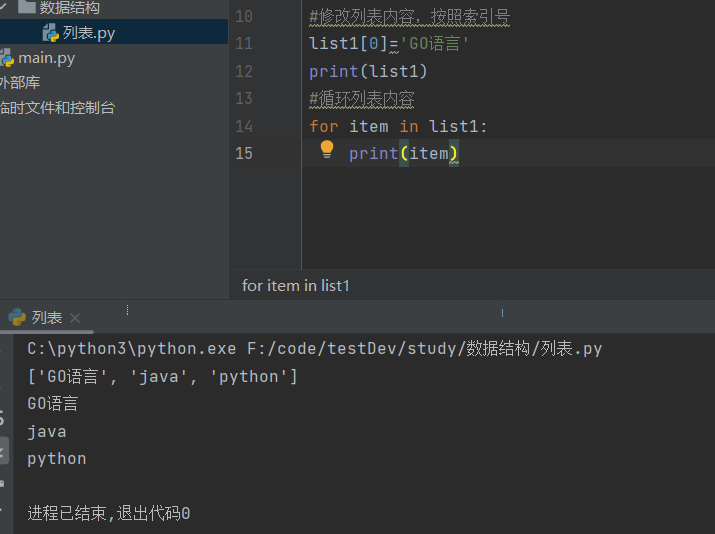
list1=['go','java','python','go'] #修改列表内容,按照索引号 #list1[0]='GO语言' #print(list1)
#循环列表内容 #for item in list1: # print(item)
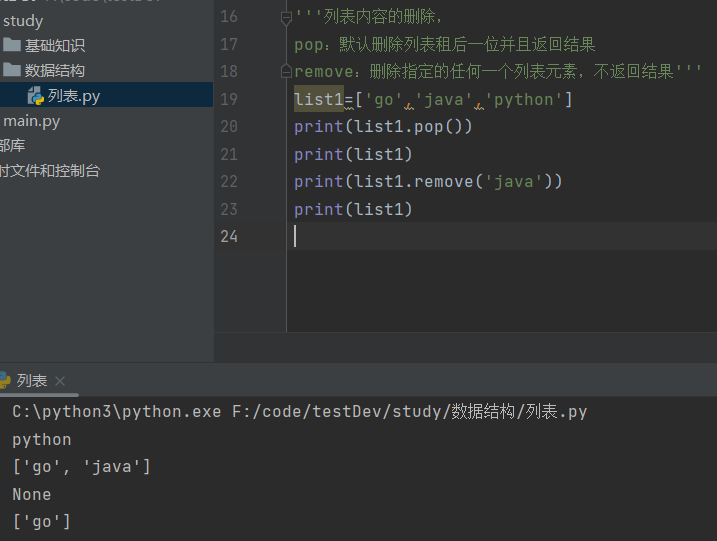
#列表内容的删除, #pop:默认删除列表租后一位并且返回结果 #remove:删除指定的任何一个列表元素,不返回结果 print(list1.pop()) print(list1) print(list1.remove('java')) print(list1)
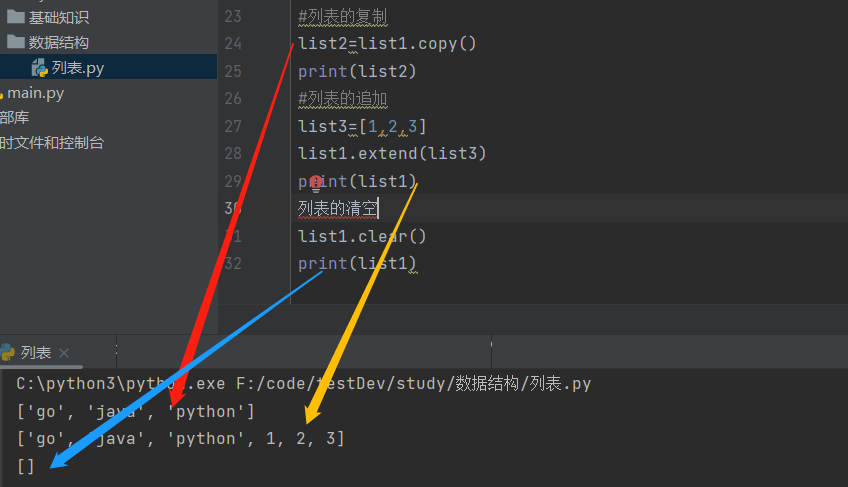
list2=list1.copy()
print(list2)
list3=[1,2,3] list1.extend(list3) print(list1)
list1.clear()
print(list1)
8.查看列表某元素的索引号
#查看某元素在列表中的总数 print(list1.count('go'))

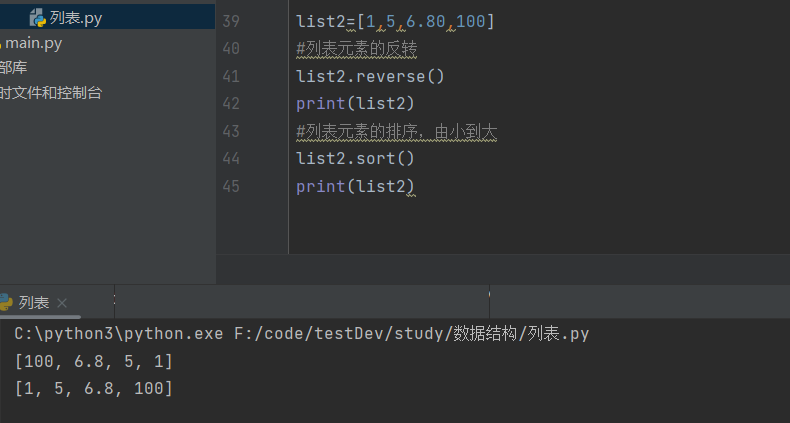
list2=[1,5,6.80,100] #列表元素的反转 list2.reverse() print(list2)
#列表元素的排序,由小到大
list2.sort()
print(list2)



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构