五.聚合函数
32.查询总数:
select count(1) from user;
33.查询年龄总和
select sum(age) as 总和 from user;
34.查询年龄平均值
select avg(age) as 平均年龄 from user;
35.查询年龄中最大值
select max(age) as 最大年龄 from user;
36.查询年龄中最大值
select min(age) as 最小年龄 from user;
37.去重distinct
select distinct name from user;
select name from user;
38.过滤group by
查询表中男女总数各有几人
select sex,count(sex) from person group by sex;
select sex,count(sex) as 总数 from person group by sex having 总数>1;!=5
查询年龄小于18的
select age,count(age) as 年龄 from person group by age having age<19;
39.查询表之前的关联inner join
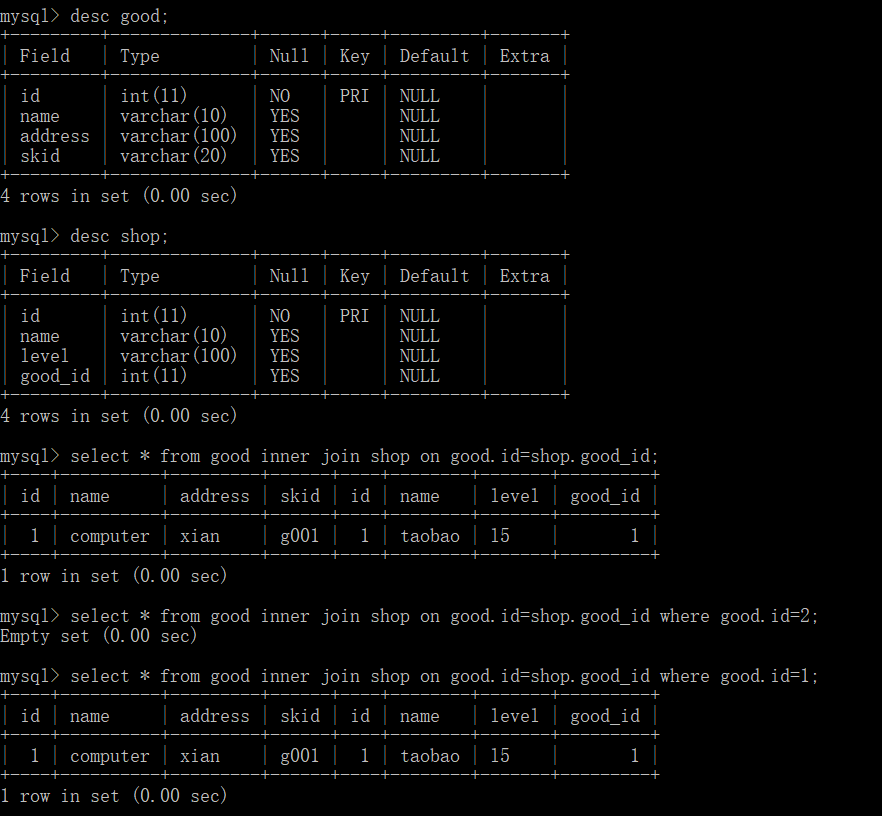
39.1查询good和shop 两个表之间共同的good的id进行关联
select * from good inner join shop on good.id=shop.good_id;
select * from good inner join shop on good.id=shop.good_id where good.id=2;
good表和shop表,拥有同样的good_id的,即good里边的Id是shop里边的good_id。
39.2测试:查询出商品名称、商城名称和商场等级之间的关联(两个表),一起展示的内容是否正确
在good和shop之间关联
测试方法:
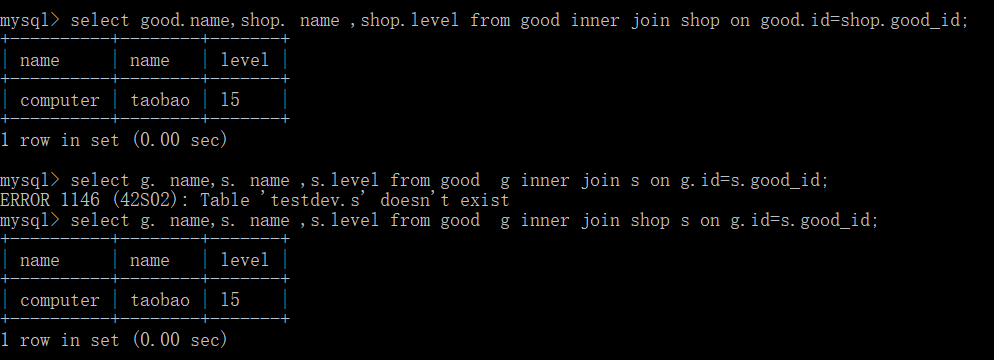
select good.name,shop. name ,shop.level from good inner join shop on good.id=shop.good_id;
使用别名:
select g. name,s. name ,s.level from good g inner join shop s on g.id=s.good_id;
39.3测试:查询商品的全部信息之间的关联,三个表的关联
测试方法:
select * from good inner join shop on good.id=shop.good_id inner join city on shop.id=city.shop_id;

39.4城市名称和商品地址
select good. address,city. name from good inner join shop on good.id=shop.good_id inner join city on shop.id=city.shop_id;
select g. address,c. name from good g inner join shop s on g.id=s.good_id inner join city c on s.id=c.shop_id;
场景练习:
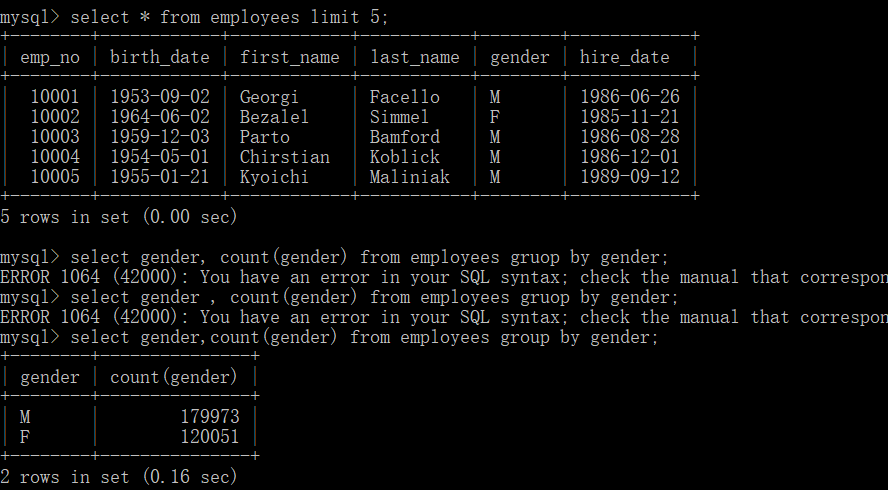
表格employees和salaries:
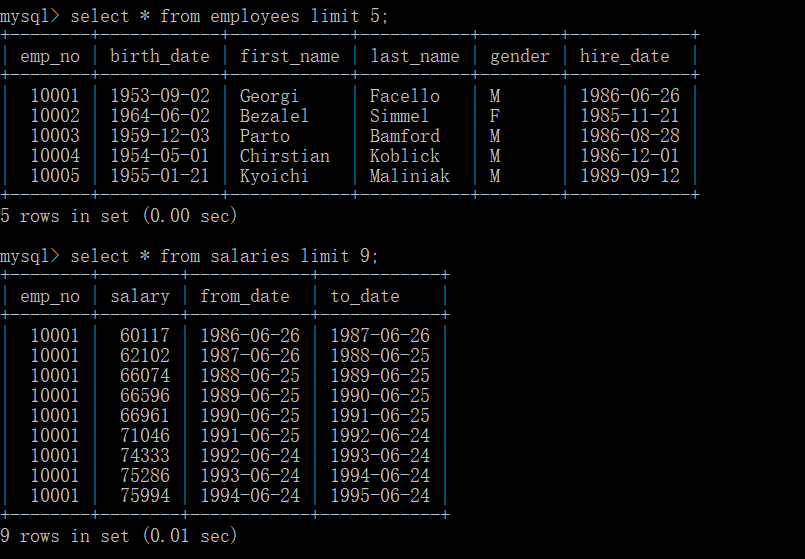
1.过滤出性别男女的总数
select gender,count(gender) from employees group by gender;
2.过滤出平均工资大于10万前9条数据
select emp_no,avg(salary) avg from salaries group by emp_no having avg>100000 limit 9;
3.过滤出平均工资大于10万前9条数据升序排列
select emp_no,avg(salary) avg from salaries group by emp_no having avg>100000 order by avg limit 9;

4.查询表中的薪资总和、平均、最大、最小(特别注意标点符号都是英文)
select sum(salary) 总和,avg(salary) 平均薪资,max(salary) 最大薪资,min(salary) 最低薪资 from salaries;

表达式:5
5.最高薪资与最低薪资的差值是多少
select (select max(salary) from salaries)-(select min(salary) from salaries);
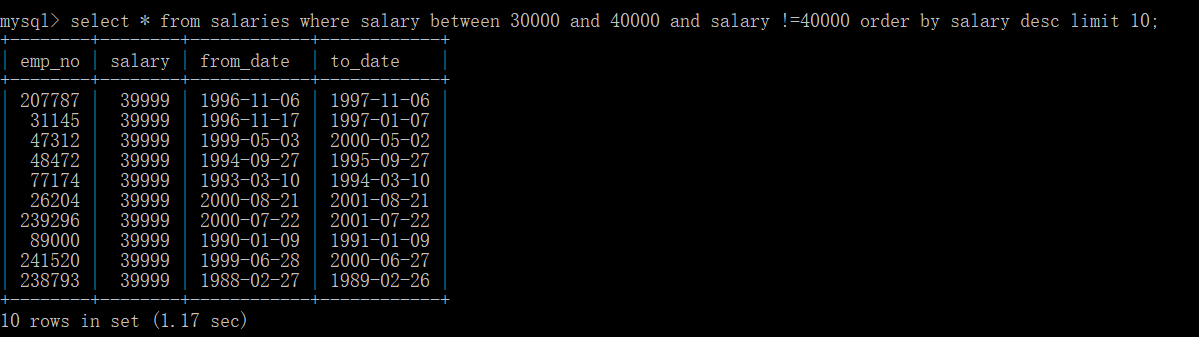
6.查询薪资在3万到4万之间且不等于4万的前10条数据且倒叙排列
select * from salaries where salary between 30000 and 40000 and salary !=40000 order by salary desc limit 10;
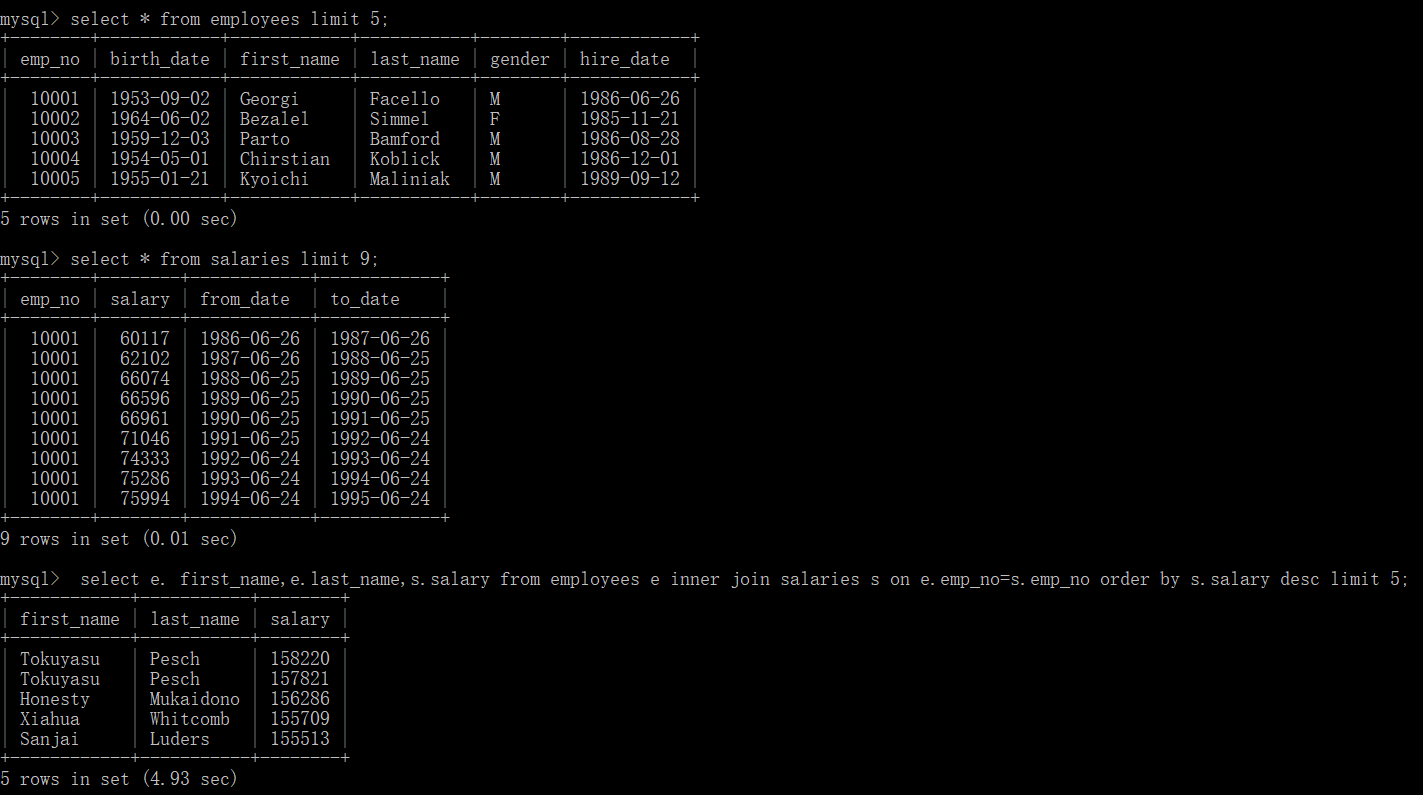
7.查询员工第一个名字和最后一个名字和薪资显示5行,并且降序排列(两个表的关联)
select employees. first_name,employees.last_name,salaries.salary from employees inner join salaries on employees.emp_no=salaries.emp_no limit 5;
select e. first_name,e.last_name,s.salary from employees e inner join salaries s on e.emp_no=s.emp_no order by s.salary desc limit 5;
40.查询表之间的左关联:left join
先进行左边表的全部查询,并且包含右边表和左边表的重复部分(内连接部分)
1、先走内连接的逻辑 2、再查询出左表所有的数据
select * from good g left join shop s on g.id=s.good_id;
41.右关联:right join
select * from good g right join shop s on g.id=s.good_id;
42.子查询(一条命令解决带有条件性的查询)
a.在shop表格内查询skid为"g001"的商品名称和等级
select name,level from shop where good_id in(select id from good where skid="g001");
a.1使用内连接的方式查询
select shop.name,shop.level from shop inner join good on good.id=shop.good_id where good.skid="g001";
可以子查询的必然可以内查询
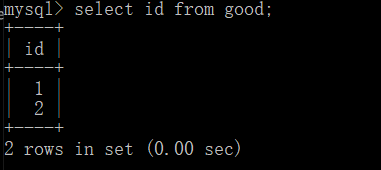
b.查询表shop的产品名称和等级

需要先查询shop产品的Id,这个id在good表里边设置的
select id from good;
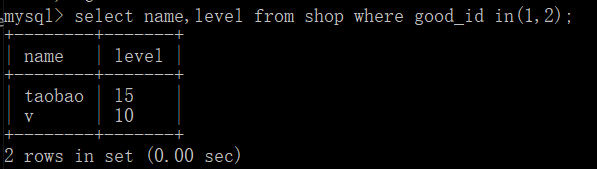
select name,level from shop where good_id in(1,2);
43.MySQL的时间类型:
DATETIME:YYYY-MM-DD HH:MM:SS 最大值到9999 TIMESTAMP:YYYY-MM-DD HH:MM:SS 最大值到2038年 DATE:YYYY-MM-DD TIME:HH:MM:SS YEAR:YYYY
带有时间的插入格式:
replace into user values(7,"apple",15,"2008-8-25 21:21:21"),(8,"bird",35,"1999-2-4 17:17:56");
带有时间的查询格式:
select * from user where birthday between "1999-1-1 00:00:00" and "2022-1-1 23:59:59";
44.MySQL小数点:
FLOAT:单精度 DOUBLE:双精度 DECIMAL (M, D):D代表小数点前的位数,M代表小数点后的位数
语法格式“DECIMAL(M,D)”。其中,M是数字的最大数(精度),其范围为“1~65”,默认值是10;D是小数点右侧数字的数目(标度),其范围是“0~30”,但不得超过M。
比如decimal(7,2),意思是后边小数点保留两位,前边的7是指的位数
七.索引index
45.创建索引
create table userindex (id int primary key,name varchar(20),code varchar(18),index code_index(code));
46.给本身已有的表增加索引
alter table user add index user_index(name);
47.删除已有的索引
drop index user_index on user;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号