
无序分类变量:无大小之分,无顺序之分,仅知道属于哪个类别
有序分类变量:无大小之分,但是有顺序之分,各个类别客户划分等级
连续型变量:有大小之分,一定区间范围内取值个数无法确定
离散变量:有小大之分,一定区间范围内取值个数是有限的,可数的。
随机抽样:每个个体被抽到的概率是一致的
总体参数和统计量
总体参数:刻画总体特征的指标称为总体参数,例如:总体均值(μ),总体标准差(σ),总体比例 (π)
统计量:刻画样本特征的指标称为统计量,例如:样本均值(x-bar),样本标准差(s),样本比例(p)
但是往往总体参数都是不可知的,我们经常会通过样本统计量去估算总体参数。
抽样误差
由随机抽样造成的样本统计量与总体指标之间的差异称为抽样误差(sampling error)
离散型随机变量的概率分布
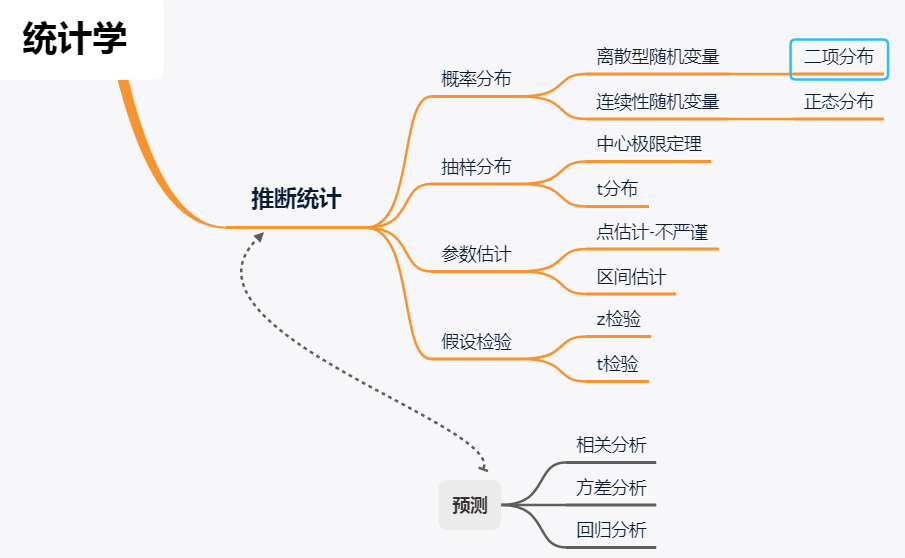
二项分布:在只有两个结果的n次独立的伯努利试验中,所期望的结果出现次数的概率
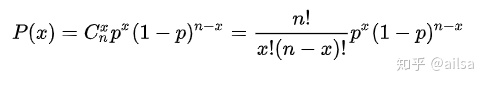
二项分布的excel函数
=BINOM.DIST(2,5,0.5,FALSE)
函数介绍
BINOM.DIST(number_s,trials,probability_s,cumulative)
BINOM.DIST 函数语法具有以下参数:
- Number_s 必需。 试验的成功次数。
- Trials 必需。 独立试验次数。
- Probability_s 必需。 每次试验成功的概率。
- cumulative 必需。 决定函数形式的逻辑值。 如果 cumulative 为 TRUE,则 BINOM.DIST 返回累积分布函数,即最多存在 number_s 次成功的概率;如果为 FALSE,则返回概率密度函数,即存在 number_s 次成功的概率。
二项分布的特征:
1.进行n次相同条件下的相互独立的重复试验
2.每次试验,只有2个结果,成功或者失败
3.出现成功的概率P每次试验是相同的,失败的概率q也是,并且p+q=1
如果符合上面的条件,那就是二项分布,如果上述试验只进行一次,就叫做伯努利试验,也是就二项分布是n次伯努利试验的结果。
泊松分布:
用来描述在一指定时间范围内或在指定的面积或体积内某一事件出现的次数的分布,他们对应的随机变量的概率服从的分布叫泊松分布。
例如:
1 某企业中每月某设备出现故障的次数
2 单位时间内到达某一服务台需要服务的顾客人数
泊松分布的excel函数
POISSON.DIST(x,mean,cumulative)
POISSON.DIST 函数语法具有下列参数:
- X 必需。 事件数。
- Mean 必需。 期望值。
- cumulative 必需。 一逻辑值,确定所返回的概率分布的形式。 如果 cumulative 为 TRUE,则 POISSON.DIST 返回发生的随机事件数在零(含零)和 x(含 x)之间的累积泊松概率;如果为 FALSE,则 POISSON 返回发生的事件数正好是 x 的泊松概率密度函数。
泊松分布是二项分布的极限
在n重伯努利实验中,当成功的概率很小,实验次数很大时,二项分布可近似等于泊松分布
在实际应用中,当p<=0.25,n>20,np<=25时,用泊松分布近似二项分布的效果良好
连续型随机变量的概率分布
正态分布
公式

μ是分布曲线的最高峰的位置(集中趋势)
σ标准差是离散程度的度量(离散趋势)
正态分布是具有对称性的
1.正态分布的面积之和为1,每个条形图的面积即频率(百分比)
2.面积=直条高度X宽度(组距) = 频率
标准正态分布

正态分布的excel函数介绍
NORMDIST(x,mean,standard_dev,cumulative)
NORMDIST 函数语法具有下列参数:
- X 必需。 需要计算其分布的数值。
- Mean 必需。 分布的算术平均值。
- standard_dev 必需。 分布的标准偏差。
- cumulative 必需。 决定函数形式的逻辑值。 如果 cumulative 为 TRUE,则 NORMDIST 返回累积分布函数;如果为 FALSE,则返回概率密度函数。

抽样分布:通过样本去推估总体
任何一个总体参数都可以进行统计推断
抽样误差与标准误:
抽样误差:由样本导致的样本均数与相应的总体均数在数值上的差异
样本均数的概率分布

中心极限定理:
设从均值为μ,方差为 (有限)的任意一个总体中抽取样本量为n样本,当n充分大时,样本均值
的抽样分布近似服从均值为μ,方差为σ^2/n的正态分布。

影响抽样误差大小的因素有两个
- 总体内各个体间的变异程度
- 样本含量N的大小
卡方分布:

卡方分布特点:

t分布:t分布就是标准正态分布除以均方的根,主要用于处理小样本问题


F分布:对比两个方差

参数估计:
样本均数直接作为总体均数的点估计,不严谨
区间估计:根据响应标准误的大小,按照一定的可信度给出一个总体参数可能的取值范围。该区间被称为可信区间。平均下来每100个可信区间中,会有大约95个覆盖真实值


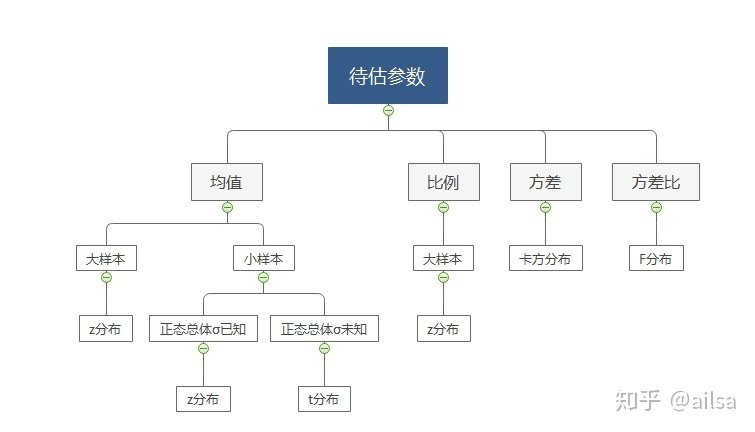
Z分布、卡方分布、t分布、F分布的区别(转自链接:https://www.zhihu.com/question/29549860/answer/1564599436)
假设检验
为什么要做检验
- 参数估计:推估样本所在的总体特征
- 假设检验:对提出的一些总体假设进行分析判断,做出统计决策
假设检验步骤之前需要做的工作
- 运用统计学知识根据研究设计和资料的性质正确选择分析过程
- 初步的统计描述(集中趋势、离散趋势)和统计分析
- 集中趋势:均数、中位数
- 离散趋势:标准差/方差、四分位差
- 分布特征
- 异常值及其他
假设检验原理:p<0.05表示小概率事件发生了(默认小概率时间不可能发生),此时拒绝原假设,接受备择假设(原假设与备择假设互斥)
假设检验分为单侧检验和双侧检验
双侧检验
- 不知道样本所在总体和假定总体的相应指标谁高谁低
- 得到拒绝结论更困难,因此相应的结果也更稳妥
单侧检验
- 在专业上可知所在总体的相应指标不可能更高/更低于假定总体值
- 单侧检验更为敏感,但设定单侧检验需要有充分的专业知识来支持
记住1.96这个常数,计算出Z值</>1.96时,可拒绝原假设。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律