

python全栈闯关--17-python正则表达式
1、匹配matc()方法
匹配成功返回一个匹配对象,失败返回None。
从字符串开始进行匹配
使用group方法显示成功的匹配
m = re.match('foo', 'food on the table') if m is not None: print(m.group()) print(m.groups())

2、搜索search()
与match一样,只是匹配位置从任意位置开始,搜索第一次出现匹配的情况
m = re.search('foo', 'seafood') m = re.search('foo', 'seafood') if m is not None: print(m.group())
3、匹配多个字符串|
满足多组规则中的任意一组,则返回
bt = 'bat|bet|bit' m = re.match(bt, 'bat') if m is not None: print(m.group())
4、匹配任何单个字符.
anyend = '.end' m = re.match(anyend,'bend') if m is not None: print(m.group()) # 匹配成功bend m = re.match(anyend, 'end') # 匹配失败 if m is not None: print(m.group()) m = re.match(anyend, '\nend') # 匹配失败,.默认能匹配\n if m is not None: print(m.group()) m = re.search(anyend, 'The end.') # .可以匹配空格,匹配到' end' if m is not None: print(m.group())
patt314 = '3.14' pi_patt = '3\.14' m = re.match(pi_patt, '3.14') # 匹配成功\.转义表示.,结果3.14 if m is not None: print(m.group()) m = re.match(patt314, '3014') # 匹配成功.匹配成0,结果3014 if m is not None: print(m.group()) m = re.match(patt314, '3.14') # 匹配成功.匹配成. if m is not None: print(m.group())
5、创建字符集[]
[]的满足任意单个字符,就算匹配上
m = re.match('[cr][23][dp][o2]', 'c3po') # 匹配c3po if m is not None: print(m.group()) m = re.match('[cr][23][dp][o2]', 'c2d2') # 匹配c2d2 if m is not None: print(m.group()) m = re.match('r2d2|c3po', 'c2do') # 不匹配 if m is not None: print(m.group()) m = re.match('r2d2|c3po', 'r2d2') # 匹配r2d2 if m is not None: print(m.group())
6、分组group和groups
group:要么返回整个匹配对象,要么返回特定子组
groups:返回一个包含唯一或者全部子组的元祖
如果没有子组要求,group依然返回整个匹配,groups返回一个空元祖
m = re.match('ab', 'ab') print(m.group()) # 匹配到ab print(m.groups()) # 没有子组,返回空元祖 m = re.match('(ab)', 'ab') print(m.group()) # 返回完整匹配ab print(m.group(1)) # 返回子组1 ab print(m.groups()) # 返回子组元祖 m = re.match('(a)(b)', 'ab') #两个子组 print(m.group()) # 返回完整匹配ab print(m.group(1)) # 返回子组1 a print(m.group(2)) # 返回子组2 b print(m.groups()) # 返回子组元祖 ('a', 'b') m = re.match('(a(b))', 'ab') #两个子组 print(m.group()) # 返回完整匹配ab print(m.group(1)) # 返回子组1 ab print(m.group(2)) # 返回子组2 b print(m.groups()) # 返回子组元祖 ('ab', 'b')
7、匹配字符串的起始和结尾及单词边界
字符串开始^
字符串结束$
单词边界/b
单词中间/B
m = re.search('^The', 'The end.') print(m.group() if m is not None else '未搜索到!') # 匹配到 m = re.search('^The', 'end. The') print(m.group() if m is not None else '未搜索到!') # 不作为起始,不能匹配到 m = re.search(r'\bthe', 'bit the dog') # 需要加r,否则\b会被当做asscii码的退格 print(m.group() if m is not None else '未搜索到!') # 边界匹配到 m = re.search(r'\bthe', 'bitethe dog') print(m.group() if m is not None else '未搜索到!') # 未匹配到 m = re.search(r'\Bthe', 'bitethe dog') print(m.group() if m is not None else '未搜索到!') # /B匹配字符中间,无边界
8、findall()和finditer()查找每一次出现的位置
findall:查询字符串中某个正则表达式模式全部的非重复出现的情况;
finditer:与findall类似,只是返回的是一个迭代器,每次返回一个值,比较节省内存;
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
m = re.findall('car', 'car') print(m) print(re.findall('car', 'scary')) print(re.findall('car', 'carry the barcardi to the car')) s = 'This and that.' print(re.findall(r"(th\w+) and (th\w+)", s, re.I)) # [('This', 'that')] print(re.finditer(r"(th\w+) and (th\w+)", s, re.I).__next__().groups()) # ('This', 'that') print(re.finditer(r"(th\w+) and (th\w+)", s, re.I).__next__().group()) # 匹配到的完整字符 print(re.finditer(r"(th\w+) and (th\w+)", s, re.I).__next__().group(1)) # 匹配到的子组1 print(re.finditer(r"(th\w+) and (th\w+)", s, re.I).__next__().group(2)) # 匹配到的子组2 l = [g.groups() for g in re.finditer(r"(th\w+) and (th\w+)", s, re.I)] # [('This', 'that')] print(l) # [('This', 'that')] # 一个模式匹配到多个分组 print(re.findall(r"(th\w+)", s, re.I)) it = re.finditer(r"(th\w+)", s, re.I) g = it.__next__() print(g.groups(), type(g)) print(g.group(1)) # 每次实际只匹配到一个组,所以只能使用一个子组 g = it.__next__() print(g.groups()) print(g.group(1)) l = [g.group(1) for g in re.finditer(r"(th\w+)", s, re.I)] print(l)
9、搜索和替换
sub:根据正则表达搜索替换,返回替换后的字符串
subn:功能与sub一样,返回元祖,元祖。(替换后的字符串,替换的字符数)
s1 = 'attn: X\n\nDear X,\n' # 匹配X替换成'Mr. Smith' s = re.sub('X', 'Mr. Smith', s1) print(s) # 替换返回元祖,(替换后的结果,替换数量) s = re.subn('X', 'Mr. Smith', s1) print(s) # 字符集替换a或者e字母替换未X print(re.sub('[ae]', 'X', 'aabedaadfaeddfd')) print(re.subn('[ae]', 'X', 'aabedaadfaeddfd')) # # 子分组分组1和子分组2替换位置 print(re.sub(r'(\d{1,2})/(\d{1,2})/(\d{2}|\d{4})', r'\2/\1/\3', '2/20/91')) print(re.subn(r'(\d{1,2})/(\d{1,2})/(\d{2}|\d{4})', r'\2/\1/\3', '2/20/91'))
10.split()分隔字符串
DATA = ( "Mountain View, CA 94040", "Sunnyvale, CA", "Los Altos, 94023", "Cupertino 95014", "Palo Alto CA" ) # 分割以, 或者两个大写字母,5个数字分组 for datnum in DATA: print(re.split(', |(?= (?:[A-Z]{2}|\d{5})) ', datnum))
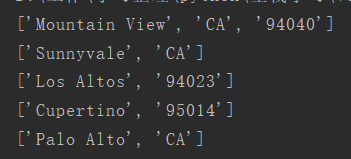
linux使用命令
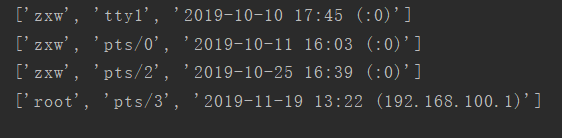
who > whofile.txt获取登录用户信息后,继续进行信息处理
# 两个以上空格切割或者制表符分割 with open('whofile.txt') as f: for eachLine in f: print(re.split(r'\s\s+|\t', eachLine.strip()))
使用命令tasklist获取进程信息
windows下使用命令
tasklist > tasklist.info
获取进程信息,处理进行信息
with open('tasklist.info', encoding='GBK') as f: for eachline in f: print(eachline, end='') # 匹配切割取出进程名或id和所占内存 f = open('tasklist.info','r',encoding ='GBK') for eachline in f: print(re.findall(r'([\w.]+(?:[\w.]+)*)\s\s+(\d+ \w+)\s\s+\d+\s\s+([\d,]+ K)', eachline.rstrip())) f.close()
11、扩展符号
# (?i)忽律大小写匹配 s = re.findall(r'(?i)yes', 'yes? Yes. YES!!!') print(s) s = re.findall(r'(?i)th\w+', 'The quickset way is through this tunnel.') print(s) # 如果没有m将不会整体当做一个字符串,加了m每行当做一个字符串 s = re.findall(r'(?im)(^th[\w ]+)', """This line is the first, another line, that line, it's the best """ ) print(s) # (?s).可以匹配/n s = re.findall(r'th.+', '''The first line the second line the third line''') print(s) # ['the second line', 'the third line'] # .可以匹配/n后,匹配到一个元素,不是两个 s = re.findall(r'(?s)th.+', '''The first line the second line the third line''') print(s) # ['the second line\nthe third line'] # (?x)允许用户通过抑制在正则表达式中使用空白符 res = re.search(r'''(?x) \((\d{3})\) [ ] (\d{3}) - (\d{4}) ''', '(800) 555-1212').groups() print(res) # (?...)进行分组,并不保存用于后续检索或者应用 l = re.findall(r'http://(?:\w+\.)*(\w+\.com)', 'http://google.com http://www.google.com http://code.google.com') print(l) # (?:\w+\.)进行了子组匹配,最后子组使用,并未检索 # (?P<name>)匹配分组,给分组取名 # (?P=name)重复使用取名后的分组 l = re.sub(r'\((?P<areacode>\d{3})\) (?P<prefix>\d{3})-(?:\d{4})', \ '(\g<areacode>) (\g<prefix>-xxx)', '(800) 555-1212') print(l) l = re.sub(r'\((?P<areacode>\d{3})\) (?P<prefix>\d{3})-(?:\d{4})', \ '(\g<areacode>) (\g<prefix>-xxx)', '(800) 555-1212') print(l) # 重复使用分组 l = re.match(r'\((?P<areacode>\d{3})\) (?P<prefix>\d{3})-(?P<number>\d{4}) (?P=areacode)-(?P=prefix)-(?P=number) 1(?P=areacode)(?P=prefix)(?P=number)'\ , '(800) 555-1212 800-555-1212 18005551212') print(l.group()) l = re.match(r"""(?x) # match (800) 555-1212,保存arecode,prefix,number \((?P<areacode>\d{3})\)[ ](?P<prefix>\d{3})-(?P<number>\d{4}) [ ] # match 800-555-1212 (?P=areacode)-(?P=prefix)-(?P=number) [ ] # match 18005551212 1(?P=areacode)(?P=prefix)(?P=number) """, '(800) 555-1212 800-555-1212 18005551212') print(l.group()) # 正向前视断言和负向前视断言 # (?=...)(?!...) # 查找姓氏为van Rossum的数据 l = re.findall(r'\w+(?= van Rossum)', """ Guido van Rossum Tim Peters Alex Martelli Just van Rossum Raymond Hettinger """) print(l) # 忽略以noreply和postmaster开头的数据 l = re.findall(r'(?m)^\s+(?!noreply|postmaster)(\w+)', #如果不加(?m)后面的行会被视为一个字符串,只能匹配到一个值 ''' sales@phpter.com postmaster@phptr.com eng@phptr.com noreply@phptr.com admin@phptr.com ''' ) print(l) # 列表表达式,根据finditer返回的迭代器,生成mail地址 l = ['%s@aw.com' % e.group(1) for e in \ re.finditer(r'(?m)^\s+(?!noreply|postmaster)(\w+)', #如果不加(?m)后面的行会被视为一个字符串,只能匹配到一个值 ''' sales@phpter.com postmaster@phptr.com eng@phptr.com noreply@phptr.com admin@phptr.com ''' )] print(l)

