一般数据库增量数据处理和数据仓库增量数据处理的几种策略
通常在数据量较少的情况下,我们从一个数据源将全部数据加载到目标数据库的时候可以采取的策略可以是:先将目标数据库的数据全部清空掉,然后全部重新从数据源加载进来。这是一个最简单并且最直观的并且不容易出错的一种解决方案,但是在很多时候会带来性能上的问题。
如果我们的数据源来自于不同的业务系统,数据动辄百万,千万甚至亿级计算。第一次需要全部加载,如果在第二次周期或者第三次周期的时候仍然全部加载的话,耗费了极大的物理和时间资源。有可能部分数据源并未发生变化,而有的数据源可能只是增加了少量的数据。
我们要考虑的问题是,对于已经存在目标数据库中的数据都是历史数据,对于数据源中的数据我们只应该考虑新修改的记录和新插入的记录,只应该考虑这两种数据。所以增量处理实质上就是处理变化的数据。
下面我们一起看看这些表,忽略从数据仓库设计的角度,只考虑如何实现增量数据的检测和抽取。
第一类 - 具有时间戳或者自增长列的绝对历史数据表

这张表能够代表一部分数据源的特征 - 绝对历史事实数据。它指的是表中的数据是不可逆的,只有插入操作没有删除或者修改操作,表示在过去一段时间内完成的事实业务数据。比如这张表表示的某些产品的下载信息,用户什么时候下载了产品就会在数据库中记录一条数据。
这种数据表一般会提供一列能够记载这条记录生成的历史时间,或者说这个操作发生的时间,越早的操作时间越靠前,越晚的操作时间越靠后。
那么对于这类表的增量处理策略就是:
- 第一次加载动作完成之后,记录一下最大的时间点,保存到一个加载记录表中。
- 从第二次加载开始先比较上次操作保存的最后/最大的时间点,只加载这个时间点以后的数据。
- 当加载过程全部成功完成之后再更新加载记录表,更新这次最后的时间点。
另外,如果这类表有自增长列的话,那么也可以使用自增长列来实现这个标识特征。
第二类 - 有修改时间特征的数据表

这类表中的数据一般属于可以修改带有维护性质的数据,比如像会员信息表,创建会员的时候会生成一条记录,会在 CreateDate 标记一下,并且在 UpdateDate 中保存的也是 CreateDate 的值。当 CreateDate 和 UpdateDate 相同的时候说明这一条数据是插入操作,但是这个会员的信息是可以被编辑和修改的,于是每次更新的同时也更新了 UpdateDate 时间戳。
假设上面的这几条数据在第一次加载到目标数据库后,源表新加入了一条会员记录并同时修改了一条会员的信息。

那么像这种情况下增量数据处理的策略就可以是:
- 第一次加载动作完成以后,记录一下最大的 UpdateDate 时间戳,保存到一个加载记录表中。(第一次是 2010-10-23)
- 在第二次加载数据的时候,用加载记录表中的时间戳与源表里的 UpdateDate 相比较,比时间戳大的说明是新添加的或者修改的数据。(大于 2010-10-23 的是第一条 Update 的数据和第四条新增的数据)
- 当整个加载过程成功之后,更新最大的 UpdateDate到记录表中。(记录表中将 2010-10-26 记录下来)
但是要注意的是,不是每一个带有修改时间特征的数据表都会这么设计,有可能在插入数据的时候只会放入 CreateDate 但是并不会写入 UpdateDate。这样的话,在每次加载的过程中可能就需要同时比较 CreateDate 和 UpdateDate 了。
第三类 - 关联编辑信息的无时间特征数据表

这类表本身没有任何可以标识的自增长 ID 或者时间戳,只保留基本信息,所有的编辑操作等信息专门有一张表来记录。这样的设计可以是为了单独记载所有的编辑历史信息,但是同时又保留了主要信息的独立性,在查询主表的时候查询体积变小提供查询效率。类似于这样的设计可以参照第一类和第二类的设计方案,在这个示例中多出的就是要关联 Member Audit History 表并进行时间戳或者自增长ID 的判断。
第四类 - 无特征数据表
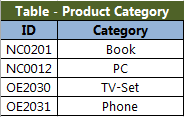
很少有人这样设计数据表,但是不代表不存在。我曾经碰到过一个文件表,由于部分数据的敏感性不能直接访问源数据库,因此是由客户从源数据库将数据抽取出来保存到一个文本文件中。很遗憾的是,抽取出来的数据中只保留了创建时间,但是并没有任何能够标识修改行为的列。与客户的沟通到最终客户接受意见修改,到最终修改完成这中间是没法停下来等客户的,因此只能暂时采用另外的一种方法 - 基于唯一列的数据对比。
很简单的概念 - 即每次加载数据源中的数据时,基于主键或者唯一列到目标表中查询是否存在,如果不存在就插入。如果存在就比较关键列数据是否相等,不相等就修改。
这种实现可以采用 SQL Merge 语句来完成 - 请参看- SQL Server - 使用 Merge 语句实现表数据之间的对比同步
或者通过 SSIS 中的 Lookup + Conditional Split 实现 - 请参看-SSIS 系列 - 数据仓库中实现 Slowly Changing Dimension 缓慢渐变维度的三种方式
那么对于前三类数据表,它们可以共同使用一个加载记录表来记录它们上一次的时间戳或者自增 ID。
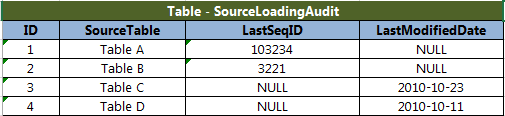
对于 Table A -
SELECT 列1, 列2 FROM Table_A WHERE ID > (SELECT LastSeqID FROM SourceLoadingAudit WHERE SourceTable = 'Table_A ')
对于 Table C -
SELECT 列1, 列2 FROM Table_C WHERE UpdateDate > (SELECT LastModifiedDate FROM SourceLoadingAudit WHERE SourceTable = 'Table_C')
数据仓库增量数据处理
数据仓库增量数据处理一般发生在从 Source 到 Staging 的过程中,从 Staging 到DW 一般又分为维度 ETL 处理和事实 ETL 处理两个部分。那么实际上从 Source 到 Staging 的过程中,就已经有意识的对维度和事实进行了分类加载处理。通常情况下,作为维度的数据量较小,而作为业务事实数据量通常非常大。因此,着重要处理的是业务事实数据,要对这一部分数据采取合适的增量加载策略。
通常情况下,对数据仓库从 Source 到 Staging 增量数据的处理可以按照这种方式:
- 对于具有维度性质的数据表可以在 Staging 中采取全卸载,全重新加载的模式。即每次加载数据的时候,先将 Staging 表数据清空掉,然后再重新从数据源加载数据到 Staging 表中。
- 对于具有事实性质的数据表,需要考虑使用上面通用的集中增量数据处理的方案,选择一个合适的方式来处理数据。保证在 Staging 事实中的数据相对于后面的 DW 数据库来说就是新增的或者已修改过的数据。
但是也不排除大维度表的情况出现,即具有维度性质的数据表本身就非常庞大,像会员表有可能作为维度表,动辄百万甚至千万的数据。这种情况下,也可以考虑使用合适的增量数据加载策略来提高加载的性能。
至于从 Staging 到 DW 的这一过程,通常情况下包含了维度 SCD 过程和事实 Lookup 过程,这个在后面再陆续写。关于缓慢渐变维度 Slowly Change Dimension 的相关理论文章可以查看我的这篇博客 - 数据仓库系列 - 缓慢渐变维度 (Slowly Changing Dimension) 常见的三种类型及原型设计
在 SSIS 中的实现可以参看我的这篇博客 - SSIS 系列 - 数据仓库中实现 Slowly Changing Dimension 缓慢渐变维度的三种方式
其它的加载策略
增量加载的处理策略不是一成不变的,采取哪一种加载策略跟数据源的设计有很大的关系。良好的数据源设计可能直接就给后续的增量处理提供了最直接的判断依据,比如自增长列,时间日期戳等。还有的数据源设计可能加入了触发器,在数据新增,修改或者删除的过程中就做出了有效的日志记录。或者加入了一些审核表,在数据的增删改过程中记录并跟踪了数据的操作细节,那么这样也是可以变通的采用上面的几种增量加载策略来设计符合当前系统的流程。
如何在增量加载之上更进一步?
还有一个非常重要的问题就是:如何处理在增量加载过程中失败的情况? 比如从 Source 到 Staging 的过程总共需要将数据写入到10个不同的 Staging 表,但是在数据加载的过程中由于一些意外情况导致其中5个表加载失败,其它5个表成功。由于考虑到效率问题,不想每次都重新加载,因此可以考虑采用以下两种方式:
第一种方式 - SSIS Package 过程处理日志和错误日志模式
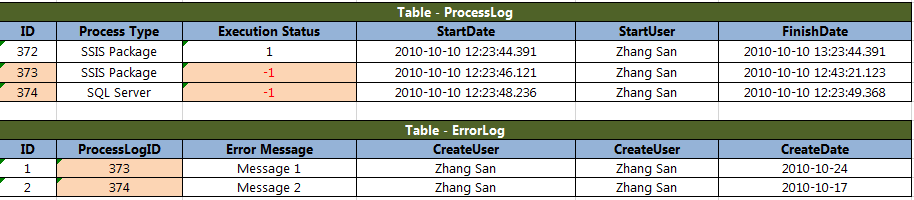
在每次 SSIS Package 执行的时候,写入一条记录到 ProcessLog 中,ExecutionStatus = 0 表示开始。执行成功的时候,更新 ExecutionStatus = 1 表示成功。执行失败的时候,更新 ExecutionStatus = -1 同时在 Event Handlers 中记录一条 Error Log 来记录一些错误信息。
下面这张表反映了在 ProcessLogID = 372 这一批次增量加载的 Audit 信息表,当然甚至可以添加加载的条数等等信息。Process Log ID = 372 的在 Process Log 表中反映出来的是一次成功的执行。

第二次执行的时候就会去检查是否执行失败的 Process Log ,如果没有的话就根据 LastSegID 或者 LastModifiedDate 完成增量加载。

第三次执行的时候,发现 Audit 表中第二次有两条没有执行成功,因此只会对上次没有成功的两个表再次加载数据。
第二种方式 - SSIS Package 中的检查点
具体内容可以参看 - SSIS 系列 - 通过设置 CheckPoints 检查点来增强 SSIS Package 流程的重用性
通过这两种方式,可以使我们的数据加载流程更加合理一些。通过增量数据的加载模式减少了一部分不必要的数据加载提升了性能,那么在这个基础之上通过日志和检查点模式在增量模式之上提高了加载过程的可重用性。已经加载过的,不再重复加载。加载失败了的,重新加载,这样对包的性能和健壮性又是一种提升。
不足之处就是第二次加载之后,由于有两个表加载成功,另外两张表加载失败。因此等失败的表重新加载之时数据源可能已经发生变化,这样造成成功与失败的表面对的数据源有所不一致,这一点在设计阶段需要考虑,这种变化是否在允许的范围内。
总结
增量数据加载的策略与数据源有莫大的关系,也与实际需求有莫大关系,因此在设计增量数据加载的过程中需要围绕实际需求以及数据源能够提供的增量变化特征仔细思考,甚至反复测试来达到加载机制的稳定和可靠性。
上面都是本人在各个不同的项目中的实际总结,数据表格定义以及思路方面只供参考。具体实现因项目不同也会存在一些差异,但这些精简过的思路可供尝试,欢迎大家补充。
最后补充一下,在这个帖子里有关于增量实现的部分内容,可以参考一下 - SSIS 系列 - 在 SSIS 中使用 Multicast Task 将数据源数据同时写入多个目标表,以及写入Audit 与增量处理信息
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号