详解索引连接类型
SQL Server有3种连接类型:
- Hash连接;
- 合并连接;
- 嵌套循环连接;
在许多影响小的行集的简单查询中,嵌套循环连接远远优于hash和合并连接。用于查询的连接类型由优化器动态决定。
下面我来先来建立两张简单的表。Province(十条数据)=》PersonTenThousand(1万数据),省份和人的关系,一对多,外键相连;
一、Hash连接
为了理解哈希连接,在这个连接中PersonTenThousand在连接列PId上没有任何索引,先来看看如下查询:
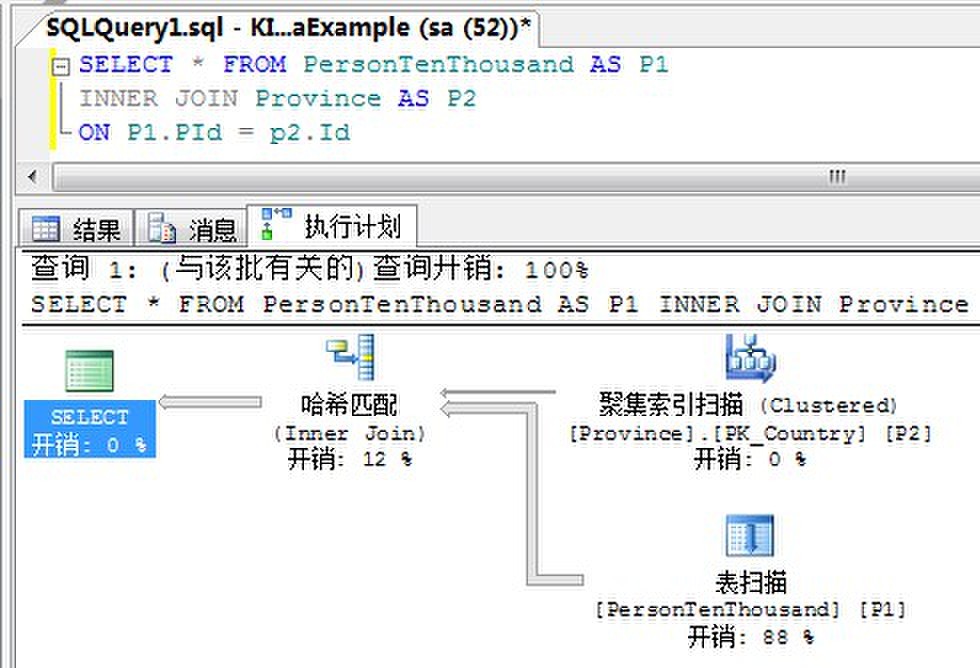
可以看到,优化器在两个表之间使用了Hash连接。这种情况经常出现于下表(大表)较大,并且下表(大表)的连接列上没有索引。
Hash连接使用两个连接输入-建立输入和探查输入。建立输入是执行计划中上面的那个输入(小表),探查输入是下面那个输入(大表)。两个输入中较小的一个作为建立输入。
Hash连接的执行分为两个阶段:建立阶段和探查阶段。在最常用的Hash连接方式-内存中的Hash连接中,整个建立输入被扫描或计算,然后再内存中建立一个Hash表。每个行根据计算的Hash键值(相当于断言中的一组列)被插入到一个Hash表元中。
这个建立阶段之后是探查阶段。整个探查输入被逐行进行扫描或计算,对于每个探查行,计算一个Hash键值。对应的Hash表元使用来自探查输入的Hash键值进行扫描,匹配被生成。
查询优化器使用Hash连接高效处理大的、未排序、没有索引的输入。通常:所求数据在其中一方或双方没有排序的条件达成时,会选用哈希匹配。
二、合并连接
先看下面的查询:
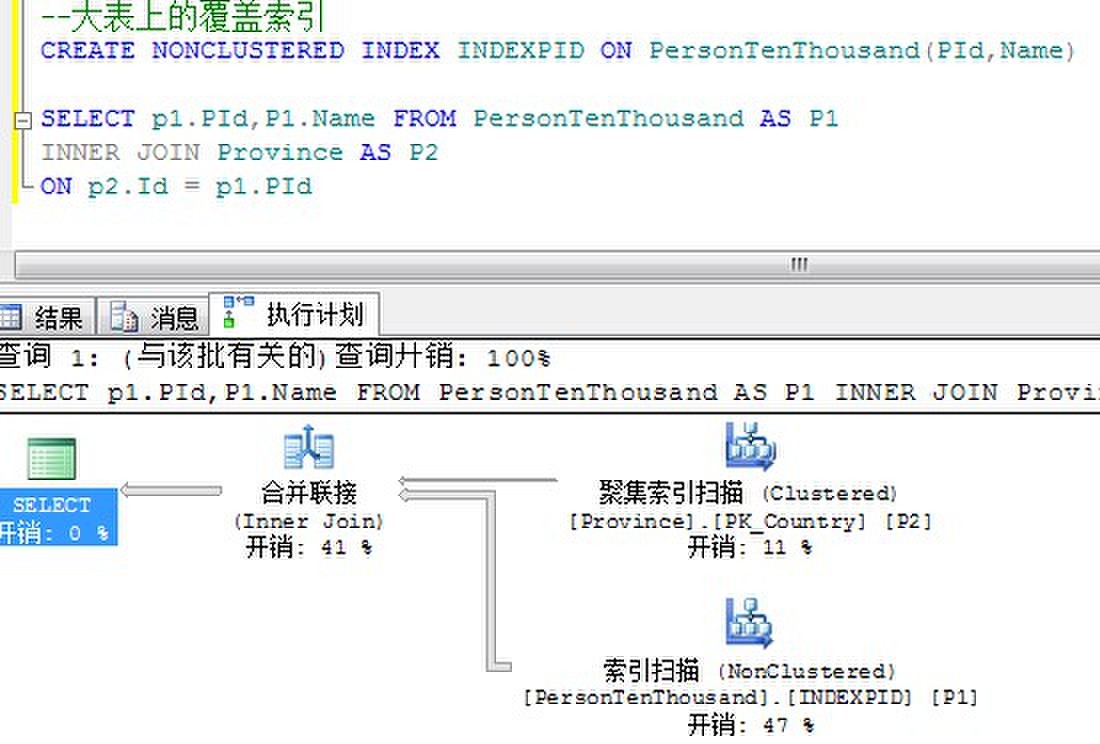
对于这个查询,优化器使用两个表之间的一个合并连接。合并连接要求两个连接输入在合并列上排序,这将在连接条件中定义。如果两个连接上有索引,那么连接输入由该索引排序。因为每个连接输入都被排序,合并排序从每个输入得到一行比较是否相等,如果它们相等,匹配的行被生成。这个过程重复道所有行都被处理。
三、嵌套循环
在以上的查询中,下面我们将在PersonTenThousand表的PId(连接列)上建立聚集索引,在运行相同的查询:

嵌套循环连接使用一个连接输入作为外部输入表,另一个作为内部输入表。外部输入表是执行计划中上面的输入,而内部输入表是下面的输入表。外部循环逐行消费外部输入表。内部循环为每个外部行执行一次,搜索内部输入表的匹配行。
如果外部输入相当小,内部输入大但是有索引,嵌套循环连接是非常高效的。在许多影响少数行的简单查询中,嵌套循环连接远远优于Hash和合并连接。连接通过牺牲其他方面来提高速度-使用内存来取得小的数据集并且快速地与第二个数据集比较,循环连接熟读很快。合并连接与此相似,使用内存和一小部分tempdb来进行其排序的比较,Hash连接使用内存和tempdb建立hash表。虽然循环连接更快,但是随着数据集变得更大,它比Hash或合并消耗更多的内存,这就是SQL Server在不同数据集的情况下使用不通计划的原因。
| 连接类型 | 连接列上的索引 | 连接表的一般大小 | 预先排序 | 连接子句 |
| Hash |
内部表:不需要索引 外部表:可选 最佳条件:小的外部表,大的内部表 |
任意 | 不需要 | Equi-join |
| 合并 |
内部/外部表:必须有索引 最佳条件:两个表都有聚集或覆盖索引 |
大 | 需要 | Equi-join |
| 嵌套循环 |
内部:必须索引 外部:最好有索引 |
小 | 可选 | 所有 |
要注意排序条件。上面的表格总结的已经非常好了,要不是说最佳条件覆盖索引,我到现在都搞不出合并连接的示例。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号