查询反模式 - 随机选择
一、问题提出
随机数在数据库中是经常用到的系统。
例如,一个广告系统希望随机选择一个广告来显示。随机推荐相关文章等等。
在SQL Server中查找随机数最简单的方法为:
SELECT TOP 1 * FROM Person ORDER BY NEWID()
以上SQL语句的执行计划如下:
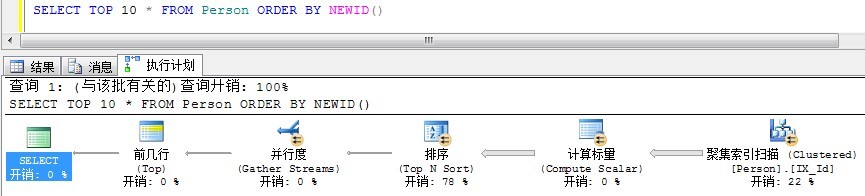
以上这种方法,需要对整个表进行一次排序,而且还无法有效地使用索引。加入我们只需要前几条数据,那么好不容易对整个结果集完成了排序,但绝大多数都浪费了。
以上的方式缺点如下:
- 随着数据量的增加,随机数的产生会变慢。
- 数据主键并不连续,并且随机数生成算法并没有考虑到这一点。
二、合理使用反模式
随机排序的性能问题在数据量很小的时候是可容忍的。
假如我们要从中国23个省中随机选择一个,那么这是很快的,并且基本不会有改变。
三、解决方案
1、从1到最大值之间的随机选择
这是一种避免对所有数据进行排序的方法,就是在1到最大的主键值之间随机选择1个。
不过,这个方案有一个非常大的缺点,就是该方案假设主键的值是从1开始并保持连续的,这意味着在1到最大值之间没有任何值是未使用的。如果当中漏掉一些值,那随机获得的主键可能取不到任何数据。当确信主键是从1到最大值连续的时候,可以使用这个方案。
SELECT p1.* FROM Person AS p1
INNER JOIN (SELECT FLOOR(RAND() * (SELECT MAX(Id) FROM Person)) AS Rand_Id) AS p2
ON p1.Id = p2.Rand_Id
执行计划如下:
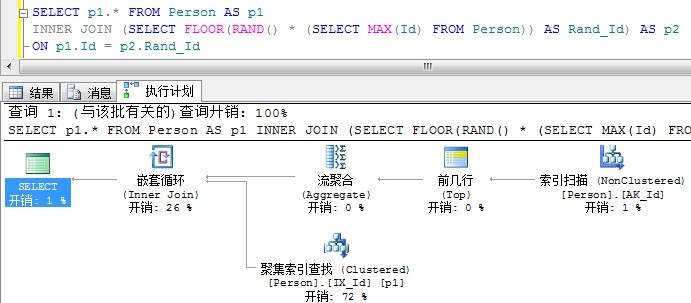
由上面的执行计划已经看出,已经不用排序了。
2、选择下一个最大值
这个方案和前一个方案类似,但解决了在1到最大值之间主键有缝隙的情况,这个查询会返回它随机找到的第一个有效值。
SELECT TOP 1 p1.* FROM Person AS p1 INNER JOIN (SELECT FLOOR(RAND() * (SELECT MAX(Id) FROM Person)) AS Rand_Id) AS p2 ON p1.Id = p2.Rand_Id WHERE p1.Id >= p2.Rand_Id ORDER BY p1.Id
这个方法解决了随机数没有主键的情况,同时也意味着在一个缝隙之后的那个值被选中的概率会增大。
当队列中的缝隙不大并且每个值要被等概率选择的重要性不高时,可以考虑这种方案。
3、高级程序获取所有的键值,随机选择一个
使用主程序代码获取所有的主键值,然后随机选择一个。再使用这个随机选择出来的主键查询完整的记录。可以用如下的.Net代码实现:
Random ran = new Random(10); ran.Next();
使用高级程序获取随机数有如下缺点:
读取整个表的主键出来,占用空间过多,可能超过内存上限。
查询必须执行两次:一次获取主键的列表,第二次获取对应的记录。如果查询太复杂或者太耗时,就会成为问题。
4、使用偏移量选择随机行
这种方案能够避免之前几个方案中的问题,那就是计算总的数据行数,随机选择0到总行数之间的一个值,然后用这个值作为位移来获取随机行。

DECLARE @i int
--产生0到COUNT()随机数
SELECT @i = CAST(CEILING(rand() * COUNT(*)) as int) FROM Person1
--获取行号等于随机数的记录
SELECT * FROM (
SELECT PersonId,PersonName,ROW_NUMBER() OVER (ORDER BY PersonId) AS RN
FROM Person1) AS T1
WHERE RN = @i
当需要每行出现的概率相等,并且主键列是不连续的,可以使用这个方案。
5、专有解决方案
每种数据库都可能针对这个需求提供独有的解决方案,比如SQL Server 2005就增加了TABLESAMPLE()函数。但是这个方法不能够返回指定行数的记录,可能会多点,也可能会少点。具体请了解函数说明:
SELECT * FROM Person TABLESAMPLE(50 ROWS);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号