
python提效小工具-统计xmind用例数量 编辑
问题:做测试的朋友们经常会用到xmind这个工具来梳理测试点或写测试用例,但是xmind8没有自带的统计测试用例,其他版本的xmind有些自带节点数量统计功能,但也也不会累计最终的数量,导致统计测试工作量比较困难。
解决方法:利用python开发小工具,实现同一份xmind文件中一个或多个sheet页的用例数量统计功能。
一、源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 | #!/usr/bin/env python # -*- coding:utf-8 -*-__author__ = 'zhongxintao'import tkinter as tkfrom tkinter import filedialogfrom xmindparser import xmind_to_dictimport xmindclass ParseXmind: def __init__(self, root): self.count = 0 self.case_fail = 0 self.case_success = 0 self.case_block = 0 self.case_priority = 0 # total汇总用 self.total_cases = 0 self.total_success = 0 self.total_fail = 0 self.total_block = 0 self.toal_case_priority = 0 # 设置弹框标题、初始位置、默认大小 root.title(u'xmind文件解析及用例统计工具') width = 760 height = 600 xscreen = root.winfo_screenwidth() yscreen = root.winfo_screenheight() xmiddle = (xscreen - width) / 2 ymiddle = (yscreen - height) / 2 root.geometry('%dx%d+%d+%d' % (width, height, xmiddle, ymiddle)) # 设置2个Frame self.frm1 = tk.Frame(root) self.frm2 = tk.Frame(root) # 设置弹框布局 self.frm1.grid(row=1, padx='20', pady='20') self.frm2.grid(row=2, padx='30', pady='30') self.but_upload = tk.Button(self.frm1, text=u'上传xmind文件', command=self.upload_files, bg='#dfdfdf') self.but_upload.grid(row=0, column=0, pady='10') self.text = tk.Text(self.frm1, width=55, height=10, bg='#f0f0f0') self.text.grid(row=1, column=0) self.but2 = tk.Button(self.frm2, text=u"开始统计", command=self.new_lines, bg='#dfdfdf') self.but2.grid(row=0, columnspan=6, pady='10') self.label_file = tk.Label(self.frm2, text=u"文件名", relief='groove', borderwidth='2', width=25, bg='#FFD0A2') self.label_file.grid(row=1, column=0) self.label_case = tk.Label(self.frm2, text=u"用例数", relief='groove', borderwidth='2', width=10, bg='#FFD0A2').grid(row=1, column=1) self.label_pass = tk.Label(self.frm2, text=u"成功", relief='groove', borderwidth='2', width=10, bg='#FFD0A2').grid(row=1, column=2) self.label_fail = tk.Label(self.frm2, text=u"失败", relief='groove', borderwidth='2', width=10, bg='#FFD0A2').grid(row=1, column=3) self.label_block = tk.Label(self.frm2, text=u"阻塞", relief='groove', borderwidth='2', width=10, bg='#FFD0A2').grid(row=1, column=4) self.label_case_priority = tk.Label(self.frm2, text="p0case", relief='groove', borderwidth='2', width=10, bg='#FFD0A2').grid(row=1, column=5) def count_case(self, li): """统计xmind中的用例数""" for i in range(len(li)): if li[i].__contains__('topics'): # 带topics标签表示有子标题,递归执行方法 self.count_case(li[i]['topics']) # 不带topics表示无子标题,此级别即是用例 else: # 有标记成功或失败时会有makers标签 if li[i].__contains__('makers'): for mark in li[i]['makers']: # 成功 if mark == "symbol-right": self.case_success += 1 # 失败 elif mark == "symbol-wrong": self.case_fail += 1 # 阻塞 elif mark == "symbol-attention": self.case_block += 1 # 优先级 elif mark == "priority-1": self.case_priority += 1 # 用例总数 self.count += 1 def new_line(self, filename, row_number): """用例统计表新增一行""" # sheets是一个list,可包含多sheet页 sheets = xmind_to_dict(filename) # 调用此方法,将xmind转成字典 for sheet in sheets: print(sheet) # 字典的值sheet['topic']['topics']是一个list my_list = sheet['topic']['topics'] print(my_list) self.count_case(my_list) # 插入一行统计数据 lastname = filename.split('/') self.label_file = tk.Label(self.frm2, text=lastname[-1], relief='groove', borderwidth='2', width=25) self.label_file.grid(row=row_number, column=0) self.label_case = tk.Label(self.frm2, text=self.count, relief='groove', borderwidth='2', width=10) self.label_case.grid(row=row_number, column=1) self.label_pass = tk.Label(self.frm2, text=self.case_success, relief='groove', borderwidth='2', width=10) self.label_pass.grid(row=row_number, column=2) self.label_fail = tk.Label(self.frm2, text=self.case_fail, relief='groove', borderwidth='2', width=10) self.label_fail.grid(row=row_number, column=3) self.label_block = tk.Label(self.frm2, text=self.case_block, relief='groove', borderwidth='2', width=10) self.label_block.grid(row=row_number, column=4) self.label_case_priority = tk.Label(self.frm2, text=self.case_priority, relief='groove', borderwidth='2', width=10) self.label_case_priority.grid(row=row_number, column=5) self.total_cases += self.count self.total_success += self.case_success self.total_fail += self.case_fail self.total_block += self.case_block self.toal_case_priority += self.case_priority def new_lines(self): """用例统计表新增多行""" # 从text中获取所有行 lines = self.text.get(1.0, tk.END) row_number = 2 # 分隔成每行 for line in lines.splitlines(): if line == '': break print(line) self.new_line(line, row_number) row_number += 1 # total汇总行 self.label_file = tk.Label(self.frm2, text='total', relief='groove', borderwidth='2', width=25) self.label_file.grid(row=row_number, column=0) self.label_case = tk.Label(self.frm2, text=self.total_cases, relief='groove', borderwidth='2', width=10) self.label_case.grid(row=row_number, column=1) self.label_pass = tk.Label(self.frm2, text=self.total_success, relief='groove', borderwidth='2', width=10) self.label_pass.grid(row=row_number, column=2) self.label_fail = tk.Label(self.frm2, text=self.total_fail, relief='groove', borderwidth='2', width=10) self.label_fail.grid(row=row_number, column=3) self.label_block = tk.Label(self.frm2, text=self.total_block, relief='groove', borderwidth='2', width=10) self.label_block.grid(row=row_number, column=4) self.label_case_priority = tk.Label(self.frm2, text=self.toal_case_priority, relief='groove', borderwidth='2', width=10) self.label_case_priority.grid(row=row_number, column=5) def upload_files(self): """上传多个文件,并插入text中""" select_files = tk.filedialog.askopenfilenames(title=u"可选择1个或多个文件") for file in select_files: self.text.insert(tk.END, file + '\n') self.text.update()if __name__ == '__main__': r = tk.Tk() ParseXmind(r) r.mainloop() |
二、工具使用说明
1、xmind文件中使用下列图标进行分类标识:
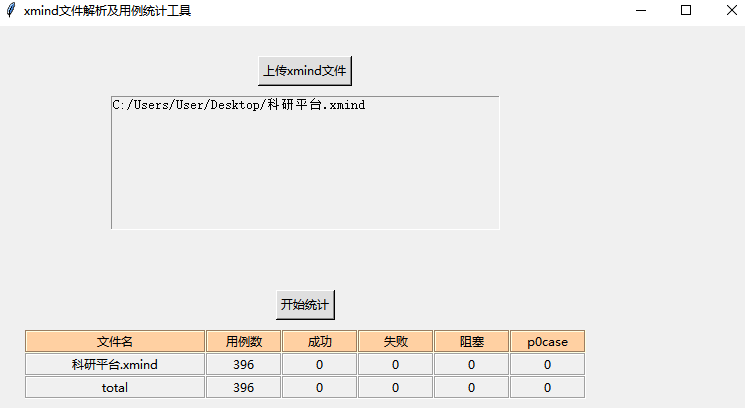
标记表示p0级别case:数字1
标记表示执行通过case:绿色√
标记表示执行失败case:红色×
标记表示执行阻塞case:橙色!
2、执行代码
3、在弹框内【上传xmind文件】按钮
4、在弹框内【开始统计】按钮
三、实现效果
转载请说明原文出处!!!
作者:Xintao zhong
出处:https://zxt518.cnblogs.com/
版权声明:本文为博主原创或转载文章,欢迎转载,但转载文章之后必须在文章页面明显位置注明出处,否则保留追究法律责任的权利。如您有任何疑问或者授权方面的协商,请 .
如果,您希望更容易地发现我的新文章,不妨点击一下绿色通道的【关注我】,亦可微信搜索号「Zxt-shenhaiweilan」关注我。
如果您觉得阅读本文对您有帮助,请点击一下右下方的推荐按钮,您的推荐将是我写作的最大动力!版权声明:本文为博主原创或转载文章,欢迎转载,但转载文章之后必须在文章页面明显位置注明出处,否则保留追究法律责任的权利。如您有任何疑问或者授权方面的协商,请 .





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 25岁的心里话
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现