
DDP.动态树分治
"动态 DP"&动态树分治--DDP
题面
每次强制点的权值,求整棵树的最小覆盖子集
概念:
最小覆盖子集:从V中取尽量少的点组成一个集合,使得E中所有边都与取出来的点相连
通俗理解:两座城市相连,其中必须选一个城市,求选出最少的城市数量
最小覆盖子集:从 \(V\) 中取尽量少的点组成一个集合,使得E中所有边都与取出来的点相连
通俗理解:用最少的点覆盖整个树,存在断层现象
最大独立子集:从 \(V\) 中取尽量多的点组成一个集合,使得这些点之间没有边相连
通俗理解:选尽量多的点使他们之间各无连边,即不存在一条边两个点都被选择的情况
仔细发现,最小覆盖子集中没有选的点恰好就是最大独立子集的点
原因:任意一条边的一个点会出现在覆盖子集中,那么与之相连的另一个点构成的集合成为独立集,覆盖集最小,也就意味着独立及最大。
所以:最小覆盖子集=全集(全点数)-最大独立子集
思路
由上面的结论,问题求动态最大独立子集,DDP运营而生
当一个点被修改,他所影响的范围是多少?
由树形DP的性质可知,\(f\) 数组是通过树形结构递归完成更新,那么一个点只有在回溯时才会产生影响,
所以影响的范围是该点的父亲及祖先们
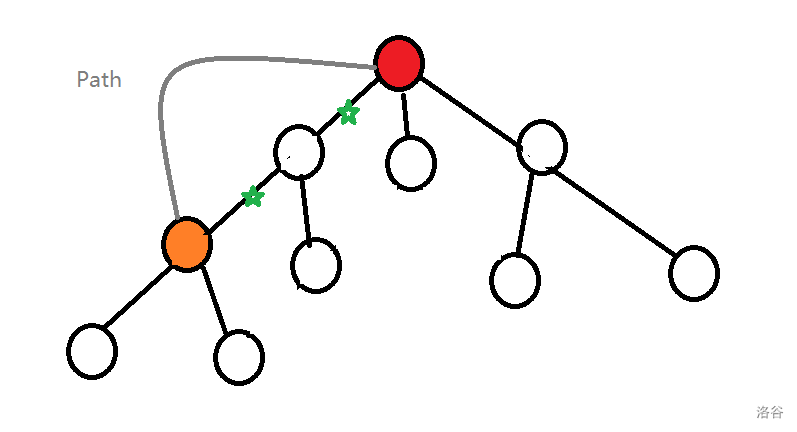
更改路径上的 \(dp\) 值,暴力的思路就是递归向上暴力更新,看似 \(O(\log n)\),良心出题人就会卡成 \(O(n)\)。
有人想到重链剖分,通过以重链为基准,只对重链操作。重链的几点性质为维护DP值提供了保障
- 重链部分在dfs序上是连续的,也就是一段区间,这可以使用数据结构进行维护
- \(O(\log n)\) 查询,操作
- 每条重链的链尾都是叶子节点,且只有叶子节点没有重儿子。这为动态规划的初始状态和转移方式做了保障。
具体实现是希望将其他轻儿子的信息都转移到重儿子上统一操作,顺着这个想法,我们更改一下转移方程。
\(f\) 含义不变,设 \(g_{i,1}\) 表示 \(i\) 点选,他的轻儿子们不选的最大价值,单独把重儿子拎出来。\(g_{i,0}\) 表示 \(i\) 点不选的最大价值,转移方程就变成
为了形式统一,其实也是为了规定重链中的叶子结点的初值,我们重新定义 \(g_{i,1}\) 表示轻儿子们不选的价值和与 \(i\) 点价值的总和,柿子就变得十分优美
树形DP的柿子本来不满足线性方程,可是现在的dp对象只有重儿子,换句话说一个点的dp值只会从重儿子转移过来,这不就是线性方程吗,用快速幂搞一下,构造转移矩阵,做完了
为了完美的构造转移矩阵,我们将柿子变得相似一些。
广义矩阵乘的话就把加法改成取 \(\max\),乘法边加法。
矩阵的构造,结合率的证明,口胡。
矩阵转移方程为:
对于一条重链,我们用叶子结点做存初值,一条链的转移就是将链上每一条点的转移矩阵相乘,重链,这不区间乘法吗,线段树可以维护,然后做完了
不过还没有,在线段树中我们是递归求区间积,即从后往前乘,转移矩阵相乘的顺序反了,这样答案是不对滴,所以我们需要构造一个转移矩阵在前的矩阵转移式。
这样可以说是全部完成了一条重链的操作,一条重链的是父亲的轻儿子,所以搞完重链记得更新重链父亲的 \(g\) 数组,现在可以看题目该怎么做了
口胡一,最终的答案为什么去 \((1,1),(1,2)\) 的位置,但是矩阵是 \(2\times 2\) 的,转移时 \((2,1),(2,2)\) 不会产生影响吗?
查询操作
对于查询一个点的 dp 值就是查询从该点一直到在该点上重链的链尾,我们用数组 \(End\) 表示以 \(i\) 点为链头,链尾在dfs的编号,用 \(val[i]\) 记录 \(i\) 点的转移矩阵
自己的看法
-
线段树的最终下标是dfsn
-
虽然矩阵中维护的是 \(G\) 数组,但是最终求出的答案为 \(F\) 因为:
\[\left[ \begin{matrix} g_{i,0}& g_{i,0}\\ g_{i,1}&-inf \end{matrix} \right]^n \times \left[ \begin{matrix} f_{j,0}\\ f_{j,1} \end{matrix}\right]=\left[ \begin{matrix} f_{i,0}\\ f_{i,1} \end{matrix}\right] \]由于开始我们都对每一矩阵赋值成该点的 \(f\) 值,所以重儿子且为叶子节点的矩阵就等价于
\[\left[ \begin{matrix} f_{j,0}\\ f_{j,1} \end{matrix}\right] \]则: 查询一个点的 DP 值,相当于查询这条重链上链尾矩阵和链中转移矩阵的 '*' 积
代码有关于DDP的详细注释
/*
对于一个点查其 dp 值,需要从这个点一直查到区间链尾。
因此,树剖时我们需要多维护一个 End[i](这里的 i 是一条重链的链头),
表示以 i 为链头的这条链,链尾(叶子)节点在 DFS 序上的位置。
更新线段树上某个点的转移矩阵时,
传入的如果是矩阵,递归下去常数太大。一个解决方法是,
在线段树外,维护一个矩阵组 Val[i],表示每个节点对应的转移矩阵。
这样在线段树更新找到对应位置时,直接赋值进来即可。
Dfn[i] 表示在 DFS 序中下标 i 的位置对应的是什么点(与 Id[i] 相反),
Fa[i] 是父亲节点,
Siz[i] 是子树大小,
Dep[i] 是该节点深度(好像没什么用),
Wson[i] 是 i 号节点的重儿子,
Top[i] 表示 i 号点所在重链链顶编号。
Id[i] 表示 i 号点在 DFS 序中的位置,
A[i] 原本的值
*/
#include <cmath>
#include <queue>
#include <cstdio>
#include <vector>
#include <cstring>
#include <iostream>
#include <algorithm>
#define ll long long
#define root 1,n,1
#define lson l,m,rt<<1
#define rson m+1,r,rt<<1|1
using namespace std;
const int A = 1e7+10;
const int B = 1e6+10;
const int mod = 1e9 + 7;
const int inf = 0x3f3f3f3f;
inline int read() {
char c = getchar();
int x = 0, f = 1;
for ( ; !isdigit(c); c = getchar()) if (c == '-') f = -1;
for ( ; isdigit(c); c = getchar()) x = x * 10 + (c ^ 48);
return x * f;
}
struct Matrix {
int mat[2][2];//竖着
Matrix() {memset(mat,-0x3f,sizeof(mat));}
inline Matrix operator *(Matrix b)
{
Matrix c;
for (int i=0;i<2;i++)
for (int j=0;j<2;j++)
for (int k=0;k<2;k++)
c.mat[i][j]=max(c.mat[i][j],mat[i][k]+b.mat[k][j]);
return c;
}
};
int n,m;
int cnt,head[B],cntv;
int a[B];
int fa[B],size[B],dep[B],hson[B];
int top[B],id[B],dfn[B],end[B];
int f[B][2];
struct node{int v,nxt;}e[B];
Matrix Val[B];
namespace Seg
{
struct node_
{
int l,r; Matrix M;
node_() {l=r=0;}
void init(int l_,int r_) {l=l_,r=r_; M=Val[dfn[l]];}
}z[B<<2];
node_ operator +(node_ &l, node_ &r)
{
node_ p; p.l=l.l,p.r=r.r; p.M=(l.M*r.M);
return p;
}
void update(int rt) {z[rt]=z[rt<<1]+z[rt<<1|1];}
void build(int l,int r,int rt)
{
if (l==r) {z[rt].init(l,r);return;}
int m=l+r>>1;
build(lson); build(rson);
update(rt);
}
void T_modify(int l,int r,int rt,int x)//单点修改 x--> id[x]是数,i是编号
{
if (l==r) {z[rt].M=Val[dfn[x]];return;}// 直接赋值,减小常数
int m=l+r>>1;
if (x <= m) T_modify(lson,x);
else T_modify(rson,x);
update(rt);
}
// 查询一个点的 DP 值,相当于查询这条重链上链尾矩阵和链中转移矩阵的 '*' 积
Matrix Query(int l,int r,int rt,int nowl,int nowr)
{
if (nowl<=l && r<=nowr) return z[rt].M;
int m=(l+r)>>1;
if (nowl<=m)
{
if (m<nowr) return Query(lson,nowl,nowr)*Query(rson,nowl,nowr);
else return Query(lson,nowl,nowr);
}
else return Query(rson,nowl,nowr);
}
}
void modify(int u,int v)
{
e[++cnt].nxt=head[u];
e[cnt].v=v;
head[u]=cnt;
}
void readin()
{
int u,v;
n=read(),m=read();
for (int i=1;i<=n;i++) a[i]=read();
for (int i=1;i<=n-1;i++) {modify(u=read(),v=read()),modify(v,u);}
}
void dfs1(int u,int pre)
{
size[u]=1;
for (int i=head[u];i;i=e[i].nxt)
{
int v=e[i].v;
if (v==fa[u]) continue;
fa[v]=u; dep[v]=dep[u]+1;
dfs1(v,u);
size[u]+=size[v];
if (size[v]>size[hson[u]]) hson[u]=v;
}
}
void dfs2(int u,int chain)
{
cntv++;
id[u]=cntv; dfn[cntv]=u; top[u]=chain;//链顶
end[chain]=max(end[chain],cntv);//记录处这条链的最低端
//第二次树剖时直接更新 f, G 数组(这里直接将 G 放入矩阵更新)
f[u][0]=0, f[u][1]=a[u];//跑最大独立子集
Val[u].mat[0][0]=Val[u].mat[0][1]=0;
Val[u].mat[1][0]=a[u];//矩阵赋初值 [1][1]=-inf
if (hson[u]!=0)//存在中儿子
{
dfs2(hson[u],chain);
//依照定义,重儿子不应计入 G 数组
f[u][0]+=max(f[hson[u]][0],f[hson[u]][1]);
f[u][1]+=f[hson[u]][0];
//因为跑得是重儿子,不计入矩阵更新范畴
}
//不存在重儿子
for (int i=head[u];i;i=e[i].nxt)
{
int v=e[i].v;
if (v==fa[u] || v==hson[u]) continue;
dfs2(v,v);
f[u][0]+=max(f[v][0],f[v][1]);
f[u][1]+=f[v][0];//更新矩阵,即G数组
Val[u].mat[0][0]+=max(f[v][0],f[v][1]);//更新矩阵,即G数组
Val[u].mat[0][1]=Val[u].mat[0][0];//G[i][0]=\sum max(f[v][1],f[v][0]) 不含重儿子
Val[u].mat[1][0]+=f[v][0];
}
}
void init()//读入,处理
{
// freopen("DDP.out","w",stdout);
readin();
dfs1(1,0), dfs2(1,1);
}
void modify_path(int u,int w)
{
Val[u].mat[1][0]+=(w-a[u]);//更新矩阵,
a[u]=w;//更新权值
Matrix bef,aft;
while (u!=0)
{
// 计算贡献时,应当用一个 bef 矩阵还原出少掉这个轻儿子的情况,再将 aft 加入更新
bef=Seg::Query(root,id[top[u]],end[top[u]]);//得到状态矩阵
Seg::T_modify(root,id[u]);//更改状态矩阵 1就是平常的线段树的编号 去更新父亲上边的节点
aft=Seg::Query(root,id[top[u]],end[top[u]]);//得到更新后的矩阵
u=fa[top[u]];
/*
删去原来的矩阵 bef 更新现在的矩阵 aft
*/
Val[u].mat[0][0] += max(aft.mat[0][0], aft.mat[1][0]) - max(bef.mat[0][0], bef.mat[1][0]);
Val[u].mat[0][1] = Val[u].mat[0][0];
Val[u].mat[1][0] += aft.mat[0][0] - bef.mat[0][0];
}//注意括号位置
}
void solve()
{
Seg::build(root);
for (int i=1;i<=m;i++)
{
int u=read(),w=read();
modify_path(u,w);//更改节点的权值
Matrix Ans=Seg::Query(root,id[1],end[1]);
printf("%d\n",max(Ans.mat[0][0],Ans.mat[1][0]));
}
}
int main()
{
init();
solve();
return 0;
}
精简版
#include <set>
#include <cmath>
#include <queue>
#include <cstdio>
#include <vector>
#include <cstring>
#include <iostream>
#include <algorithm>
#include <bits/stdc++.h>
#define ll long long
using namespace std;
const int A = 1e7+10;
const int B = 1e6+10;
const int mod = 1e9 + 7;
const int inf = 0x3f3f3f3f;
inline int read() {
char c = getchar();
int x = 0, f = 1;
for ( ; !isdigit(c); c = getchar()) if (c == '-') f = -1;
for ( ; isdigit(c); c = getchar()) x = x * 10 + (c ^ 48);
return x * f;
}
#define root 1,n,1
#define lson l,m,rt<<1
#define rson m+1,r,rt<<1|1
struct Matrix
{
int mat[2][2];
Matrix() {memset(mat,-0x3f,sizeof(mat));}
inline Matrix operator *(Matrix b)
{
Matrix c;
for (int i=0;i<2;i++)
for (int j=0;j<2;j++)
for (int k=0;k<2;k++)
c.mat[i][j]=max(c.mat[i][j],mat[i][k]+b.mat[k][j]);
return c;
}
};
struct node {int v,nxt;} e[B<<1];
int head[B],cnt;
void modify(int u,int v)
{
e[++cnt].nxt=head[u];
e[cnt].v=v;
head[u]=cnt;
}
int top[B],dfn[B],id[B],end[B],t;
int a[B];
int fa[B],dep[B],size[B],hson[B];
int f[B][2];
Matrix val[B];
namespace Seg
{
struct tree {
int l,r;
Matrix M;
tree() {l=r=0;}
void init(int l_,int r_) {l=l_,r=r_,M=val[dfn[l]];}
}z[B<<2];
tree operator +(tree &l,tree &r)
{
tree p;
p.l=l.l,p.r=r.r,p.M=l.M*r.M;
return p;
}
void update(int rt) {z[rt]=z[rt<<1]+z[rt<<1|1];}
void build(int l,int r,int rt)
{
if (l==r) {z[rt].init(l,r);return;}
int m=l+r>>1;
build(lson),build(rson);
update(rt);
}
void modify(int l,int r,int rt,int x)
{
if (l==r) {z[rt].M=val[dfn[x]];return;}
int m=l+r>>1;
if (x<=m) modify(lson,x);
else modify(rson,x);
update(rt);
}
Matrix query(int l,int r,int rt,int nowl,int nowr)
{
if (nowl<=l && r<=nowr) return z[rt].M;
int m=l+r>>1;
if (nowl<=m)
{
if (m<nowr) return query(lson,nowl,nowr)*query(rson,nowl,nowr);
else return query(lson,nowl,nowr);
}
return query(rson,nowl,nowr);
}
}
int n,m;
void readin()
{
int u,v;
n=read(),m=read();
for (int i=1;i<=n;i++) a[i]=read();
for (int i=1;i<=n-1;i++) modify(u=read(),(v=read())),modify(v,u);
}
void dfs1(int u,int pre)
{
dep[u]=dep[pre]+1,fa[u]=pre,size[u]=1;
for (int i=head[u];i;i=e[i].nxt)
{
int v=e[i].v;
if (v==pre) continue;
dfs1(v,u);
size[u]+=size[v];
if (!hson[u] || size[v]>size[hson[u]]) hson[u]=v;
}
}
void dfs2(int u,int chain)
{
t++;
id[u]=t,dfn[t]=u,top[u]=chain;
end[chain]=max(end[chain],t);///// 出锅两次
f[u][0]=0,f[u][1]=a[u];
val[u].mat[0][1]=val[u].mat[0][0]=0;
val[u].mat[1][0]=a[u];
if (hson[u])
{
dfs2(hson[u],chain);
f[u][0]+=max(f[hson[u]][0],f[hson[u]][1]);//
f[u][1]+=f[hson[u]][0];
}
for (int i=head[u];i;i=e[i].nxt)
{
int v=e[i].v;
if (v==fa[u] || v==hson[u]) continue;
dfs2(v,v);
f[u][0]+=max(f[v][0],f[v][1]);
f[u][1]+=f[v][0];//不是重链
val[u].mat[0][0]+=max(f[v][0],f[v][1]);//.///
val[u].mat[0][1]=val[u].mat[0][0];
val[u].mat[1][0]+=f[v][0];
}
}
void init() {readin(); dfs1(1,0), dfs2(1,1);}
void T_modify(int u,int w)
{
val[u].mat[1][0]+=(w-a[u]);
a[u]=w;
Matrix bef,aft;
while (u!=0)
{
bef=Seg::query(root,id[top[u]],end[top[u]]);
Seg::modify(root,id[u]);
aft=Seg::query(root,id[top[u]],end[top[u]]);
u=fa[top[u]];
val[u].mat[0][0]+=max(aft.mat[0][0],aft.mat[1][0])-max(bef.mat[0][0],bef.mat[1][0]);
val[u].mat[0][1]=val[u].mat[0][0];
val[u].mat[1][0]+=aft.mat[0][0]-bef.mat[0][0];//继承错了
}
}
void solve()
{
Seg::build(root);
for (int i=1;i<=m;i++)
{
int u=read(),w=read();
T_modify(u,w);
Matrix ans=Seg::query(root,id[1],end[1]);
printf("%d\n",max(ans.mat[1][0],ans.mat[0][0]));
}
}
int main()
{
init();
solve();
return 0;
}

