
KMP字符串匹配(看猫片)
KMP 算法介绍
简介
KMP是由三个人的首字母命名的(自己查),大体先说一下,方便有个基本的概念
用途
这里引出一个小问题
给出主串 \(S\) 和 子串 \(a\),求出子串在主串中的数量
最暴力的想法就是哈希表或固定区间挨个判断,类似公交换乘。可是复杂度可想而知,因此有神人发明了 \(KMP\),简单说就是字符匹配
开始我也是觉着还不如哈希表,真绕,但是听完后感觉真香
 (
(请忽略作者的调皮)
思想
这列给出主串
我们发现没有必要一个一个的移动,当子串为 \({\color{Aquamarine}{A}}\) \({\color{GreenYellow}{B}}\) \({\color{Aquamarine}{CAB}}\) 时,假若与主串匹配到第一个 \({\color{GreenYellow}{B}}\) 就失败了,那么匹配串(主串与子串正在匹配的串,下同)可以往后移动一位,移两位都不会成功(因为移动后得到的匹配串的第一位都不是 \(A\))。
那么往后移\({\color{Magenta}{三}}\)位呢,我们不难发现,第一位必定是 \(A\) ,

那我们是不是可以省去这次单个比较啦,同理 第二位的 \(B\) 也不用比较了(看上方图解),但是后面的我们并不知道,因此需要再挨个比较
像这样,如果每次都可找到一些不需要匹配的字母,是不是复杂度会大大降低,这就是 \({\color{Purple}{KMP}}\) 算法的思想
\(next\)
上面的想法对应到代码中有个响亮的名字叫失配数组,用 \(next[]\) 表示.具体的说,当子串中的位置 \(i\) 与 主串中位置 \(j\) 匹配失败时,应当用主串中位置 \(j\) 上表示的字符在子串中的位置 \(k\),这样往后比会更加的省时。
而 \(next[i]\) 的含义是子串到 \(i\) 位置的前缀串 \(l\) 中最长相同前后缀(不含自身)的前缀结束的位置。
就拿上面的子串 \((ABCAB)\) 来说, 则\(next={-1,-1,-1,0,1}\) \(-1\)表示没有合法的前缀串 \(l\) ,作者一般喜欢设成 \(-1\).
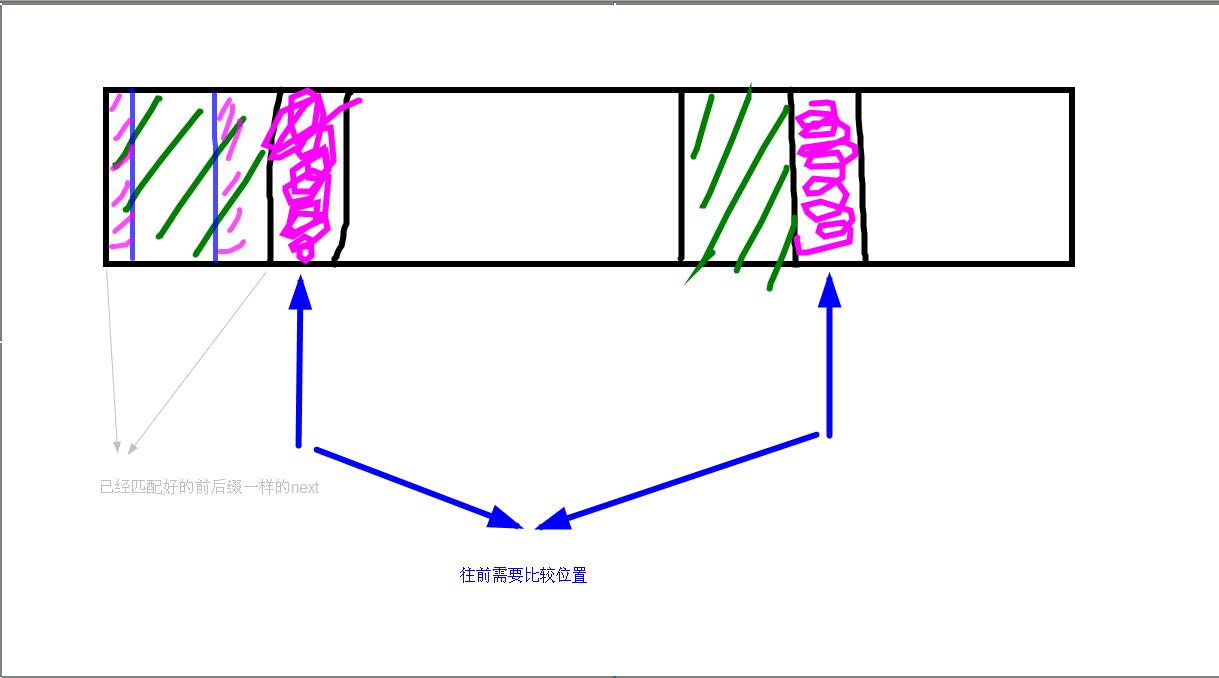
\({\color{GreenYellow}{绿色}}\) 的是已经一样的,\({\color{Magenta}{紫色}}\) 是正在比较的,若判断当前位置 \(i\) 是否与 图前部分紫色位置 \(k\) 一样,只需要知道 \(k\) 往前的前缀串中前缀位置 \(+1\) 是否是 \(k\) 即可,(因为已经一样的子串即绿色部分我们也是按上述进行的操作),因此我们对于 \(k\) 往前的 \(next\) 是已知的,以此类推,就类似 \(dp\) 后面的 \(next\) 由是前面的位置,不理解可以去先看看线性筛素数的优化讲解,用到的\(pre[]\) 的方法和 \(next\) 雷同
//next代码
inline void getnext(){
next_[0] = -1;
int j;
for(int i = 1;i < ss; ++i)
{
j = next_[i - 1];
while(c[i] != c[j + 1] && j >= 0)
j = next_[j];
next_[i] = c[i] == c[j+1] ? j + 1 : -1;
}
}
匹配的过程
相互匹配中,主串\(s[]\)的位置为 \(j\), 子串\(ss[]\)的位置为 \(i\) 匹配过程中存在三种情况
s[j] == ss[i]直接后移一位- 如果上述不成立,那就早 \(ss[i]\) 的 \(next[i-1]\) 的下一个位置即
next[i-1]+1(因为这种情况是在第一条不成立的情况下进行,也就是说前面的是匹配好的,因此调用 \(next\) 了解他的下一个位置是否一样即可) i==0表示没有合法的\(next\) 可以与 \(j\) 相匹配,那么这个 \(j\)就不法匹配成功, 直接进行下一位的比较
//KMP代码
inline void KMP(){
int i = 0, j = 0;
while(j < s && i < ss)
{
if(a[j] == c[i])
{
i++, j++;//情况一
}
else if(i == 0) j++;//情况三
else i = next_[i - 1] + 1;//情况二
if(i == ss)//匹配成功啦
{
ans++;//记录答案
i = next_[i-1] + 1;//重置i,(貌似-1也可以)
}
}
}
时间复杂度
在整个匹配过程中,主串指针 \(j\) 只会向后走,子串指针 \(i\) 失配是会 \(O(1)\) 到失配位置,因此时间复杂度为
例题
#include <iostream>
#include <cstdio>
#include <algorithm>
#include <queue>
#include <cmath>
#include <cstring>
#define F(i,l,r) for(int i=l;i<=r;i++)
#define FK(x) memset(x,0,sizeof(0))
using namespace std;
/*-----------------------------*/
const int manx = 1e6+10;
const int mod = 1e9+9;
const int base = 1e7+7;
inline int read(){
char c = getchar();int x = 0,f = 1;
for(;!isdigit(c);c = getchar())if(c == '-') f = -1;
for(;isdigit(c);c = getchar()) x = x*10 + (c^48);
return x * f;
}
/*----------------------------------------------*/
int s, ss, n, sum[manx], k, next_[manx];
char c[manx], a[manx];
/*----------------------------------------------*/
inline void prepare(){
FK(next_);
}
inline void getnext(){
next_[0] = -1;
int j;
for(int i = 1;i < ss; ++i)
{
j = next_[i - 1];
while(c[i] != c[j + 1] && j >= 0)
j = next_[j];
next_[i] = c[i] == c[j+1] ? j + 1 : j;
}
}
inline void KMP(){
int i = 0, j = 0, ans = 0;
while(j < s && i < ss)
{
if(a[j] == c[i])
{
i++, j++;
}
else if(i == 0) j++;
else i = next_[i - 1] + 1;
if(i == ss)
{
cout<<j-ss+1<<endl;
i = next_[i - 1] + 1;
}
}
// return ans;
}
int main(){
cin >> a ;
cin >> c ;
s = strlen(a ), ss = strlen(c );
getnext();
KMP();
F(i,0,ss - 1) cout<< next_[i] + 1 <<" ";
}
注:本 \(blog\) 只供了解,毕竟我是一名小菜鸡,写文章时差点把自己绕进去~
作者@_Thorzy,转载请标明出处

