

redis的类型
一、字符串类型
string操作,redis中的String在内存中按照一个name对应一个value来存储
set操作
set(name, value, ex=None, px=None, nx=False, xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行,值存在,就修改不了,执行没效果
xx,如果设置为True,则只有name存在时,当前set操作才执行,值存在才能修改,值不存在,不会设置新值
原来存在name,执行set,值存在发生了修改
import redis
conn = redis.Redis()
res = conn.set('name', 'zrr')
print(res) # value 只能是字符串或byte格式
原来不存在username,执行set,创建了
res = conn.set('username', 'zrr')
print(res)


ex 是过期时间,到4s过期,数据就没了
res = conn.set('password', '12345678', ex=4)
print(res)
px 是过期时间,到3s过期,数据就没了
res = conn.set('password', '12345678', px=3000)
print(res)
如果设置为True,则只有name不存在时,当前set操作才执行,值存在,就修改不了,执行没效果
conn.set('age', 30, nx=True)
print(res)
res = conn.set('age', 30, nx=False)
print(res)
如果设置为True,则只有name存在时,当前set操作才执行,值存在才能修改,值不存在,不会设置新值
conn.set('age', 30, xx=True)
print(res)
res = conn.set('age', 30, xx=False)
print(res)
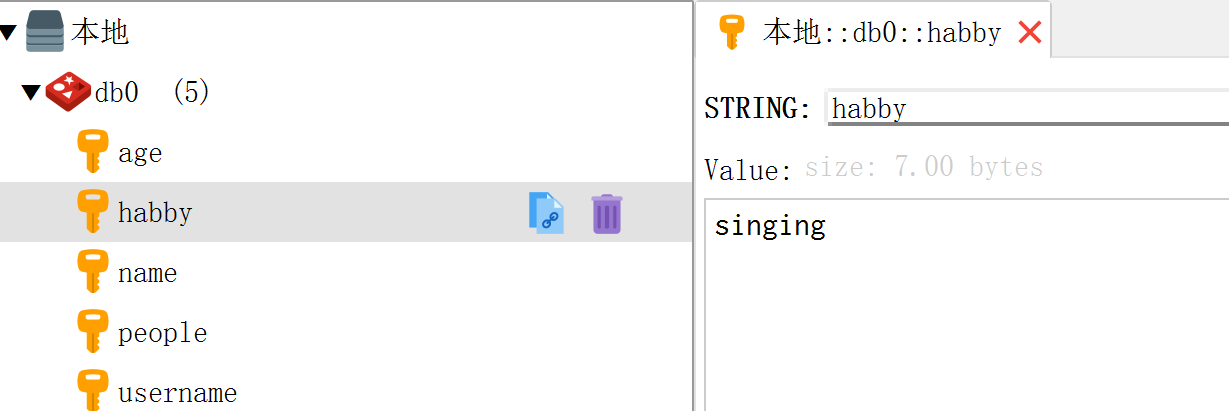
setnx(name, value) 就是:set nx=True
res = conn.setnx('habby', 'singing')
print(res)
psetex(name, time_ms, value) 本质就是 set px设置时间
res = conn.psetex('name', 3000, 'zxb')
print(res)
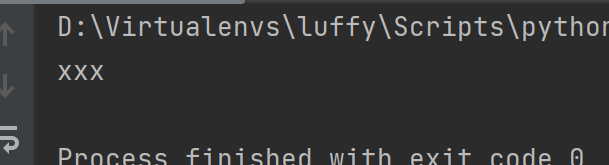
mset(*args, **kwargs) 传字典批量设置
res = conn.mset({'name': 'xxx', 'age': 19})
print(res)
get(name) 获取值,取到是bytes格式
import redis
conn = redis.Redis(decode_responses=True)
res = conn.get('name')
print(res)
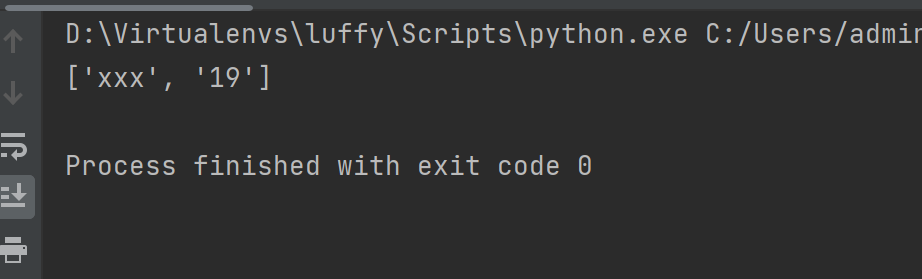
mget(keys, *args) 批量获取
import redis
conn = redis.Redis(decode_responses=True)
res = conn.mget('name', 'age')
print(res)
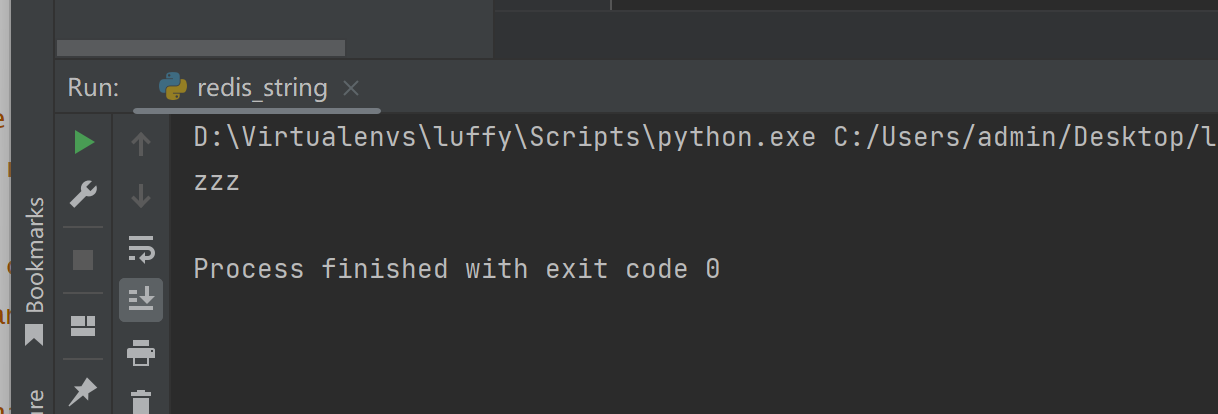
getset(name, value) 先获取,再设置
res = conn.getset('name', 'zzz')
print(res)
getrange(key, start, end) 取的是字节,前闭后闭区间
res = conn.getrange('name', 0, 1)
print(res)
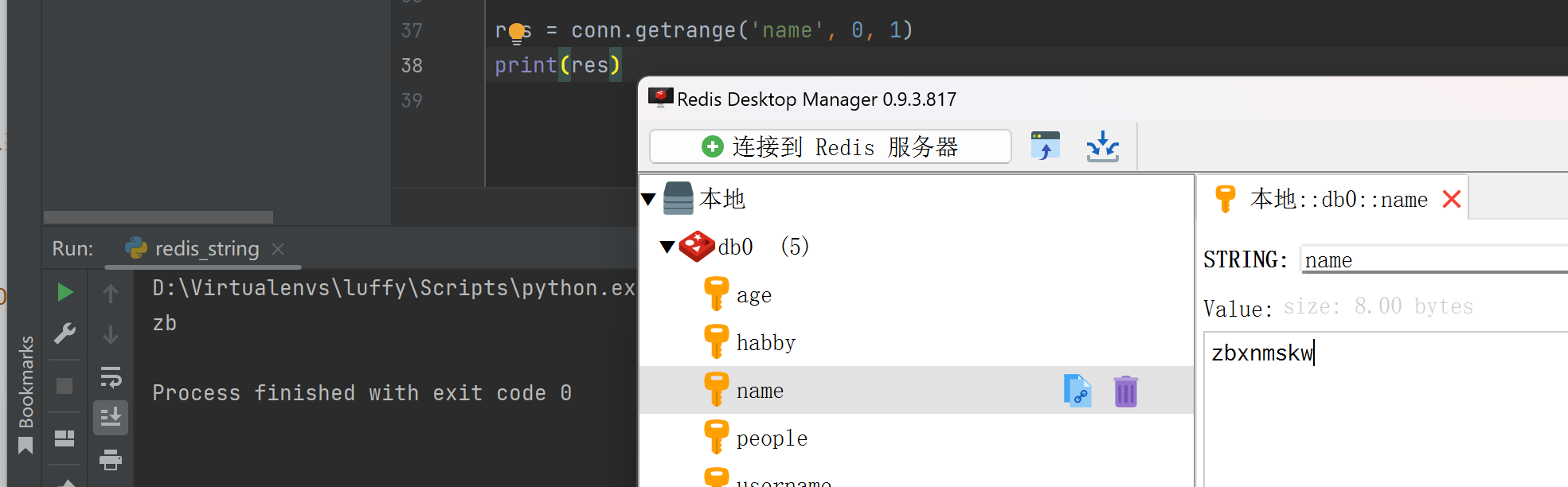
setrange(name, offset, value) 从某个起始位置开始替换字符串
res = conn.setrange('name', 2, '11')
print(res)
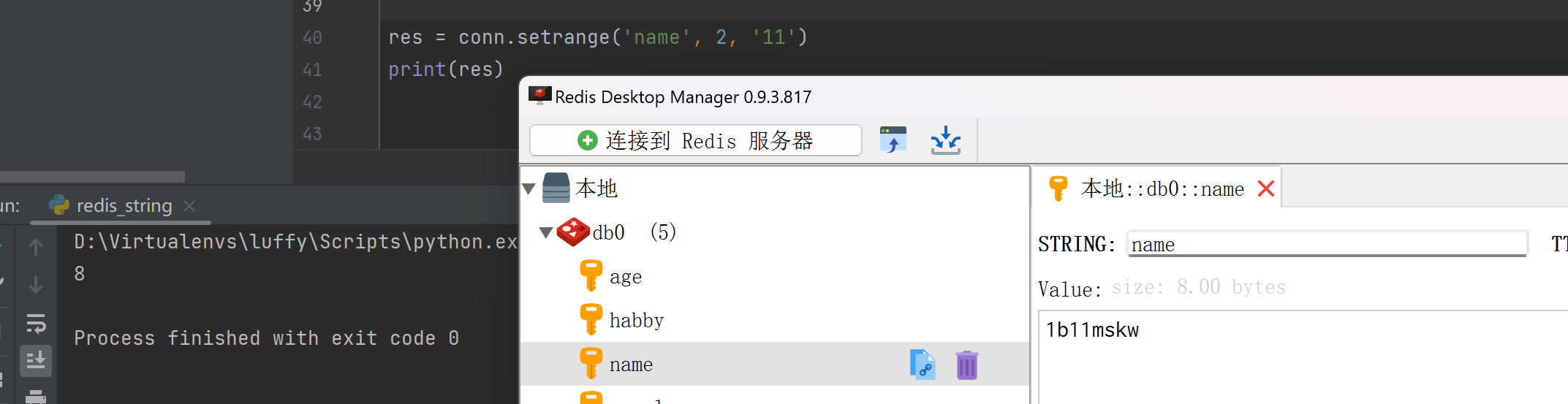
setbit(name, offset, value)
res = conn.setbit('name', 1, 0)
print(res)
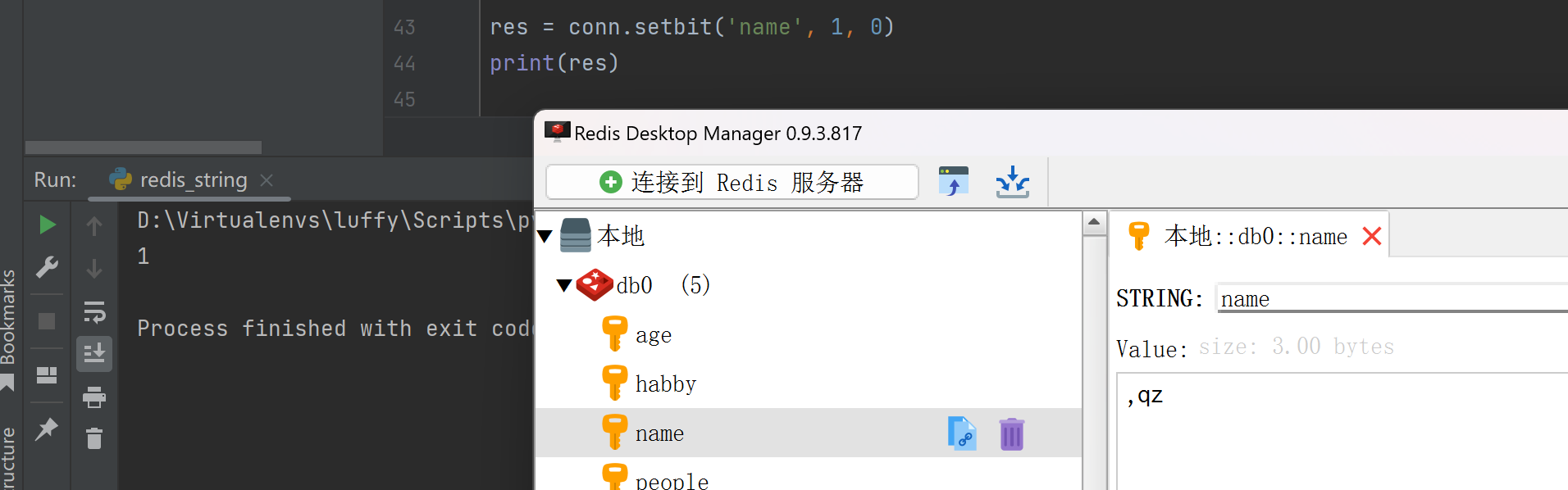
getbit(name, offset)
res = conn.getbit('name', 1)
print(res)
bitcount(key, start=None, end=None)
print(conn.bitcount('name',0,3)) # 3 指的是3个字符
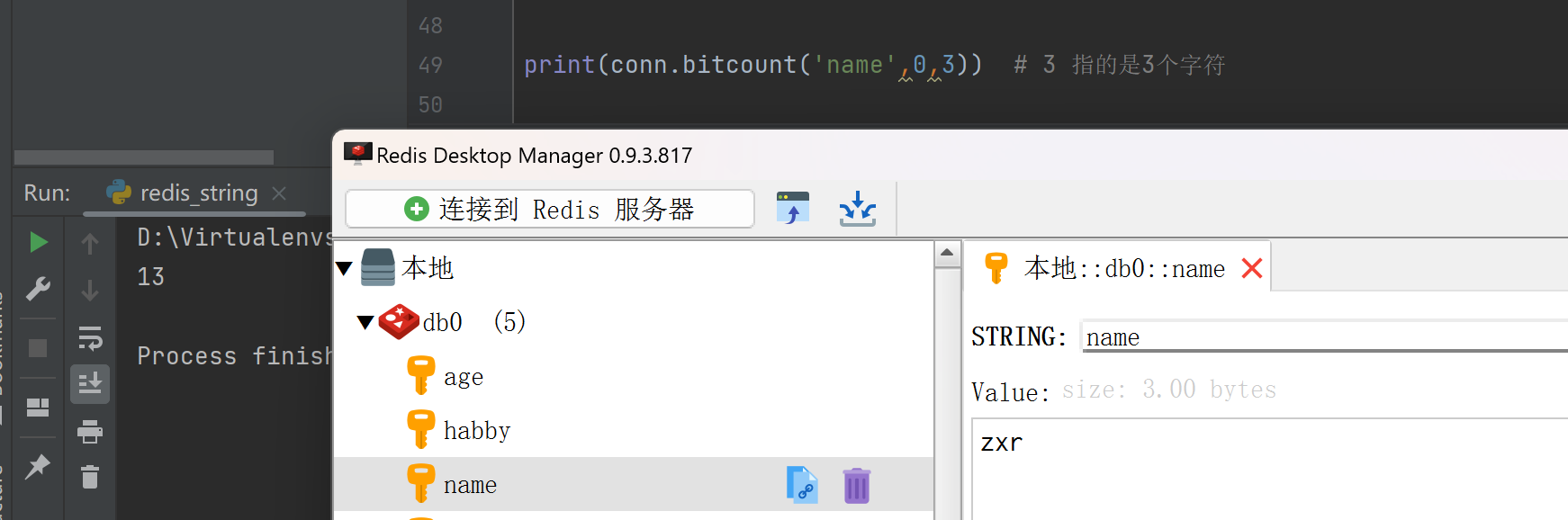
strlen(name) 统计字节长度
print(conn.strlen('name'))
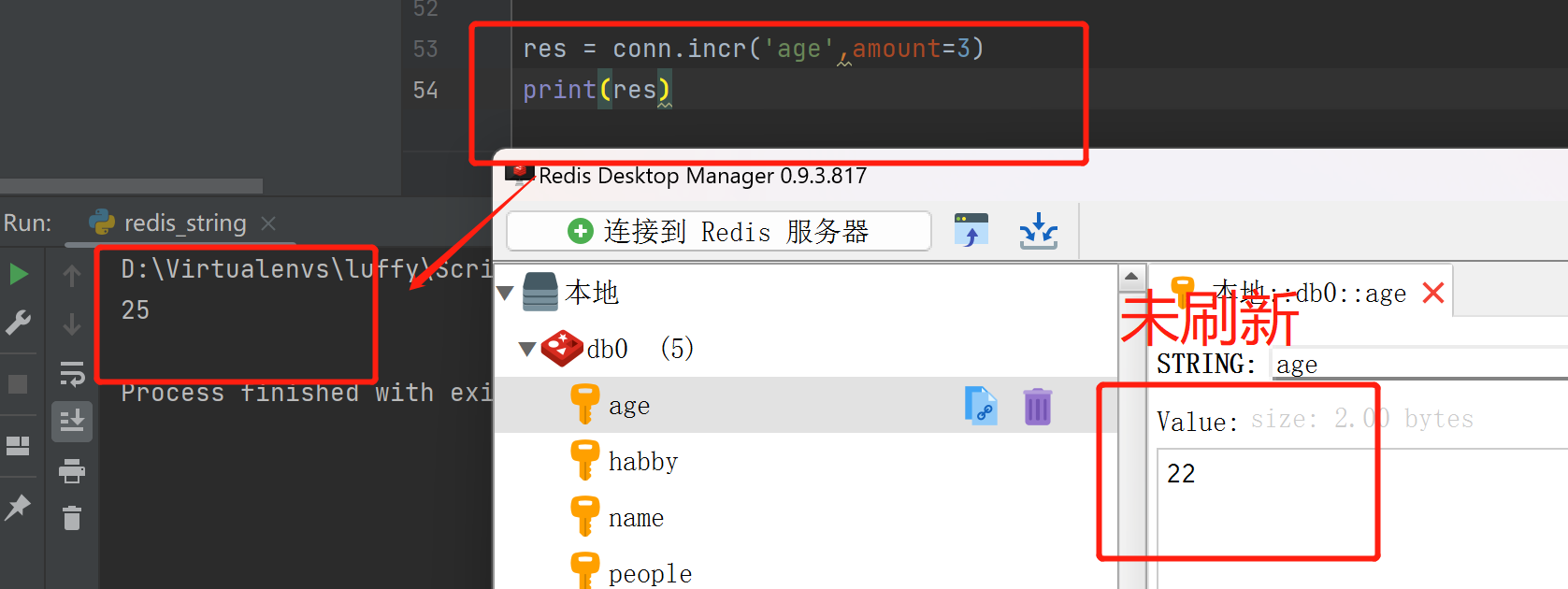
incr(self, name, amount=1) 计数器
res = conn.incr('age',amount=3)
print(res)
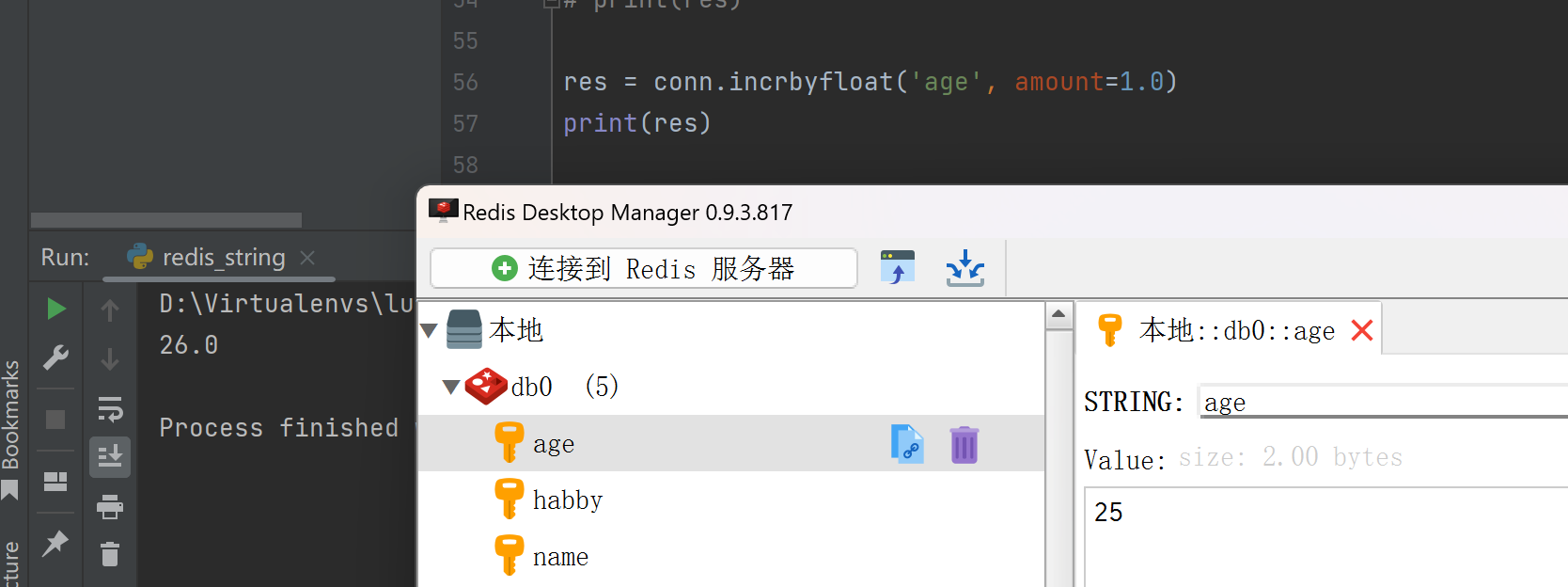
incrbyfloat(self, name, amount=1.0)
res = conn.incrbyfloat('age', amount=1.0)
print(res)
decr(self, name, amount=1)
res = conn.decr('age', amount=1)
print(res)
append(key, value)
conn.append('name', 'nb')
二、哈希类型
hset(name, key, value)
conn.hset('userinfo', 'name', '李易峰')
conn.hset('userinfo', 'age', '32')
conn.hset('xx', mapping={'name': 'xxx', 'hobby': '篮球'})
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
name,redis的name
key,name对应的hash中的key
value,name对应的hash中的value
# 注:
hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
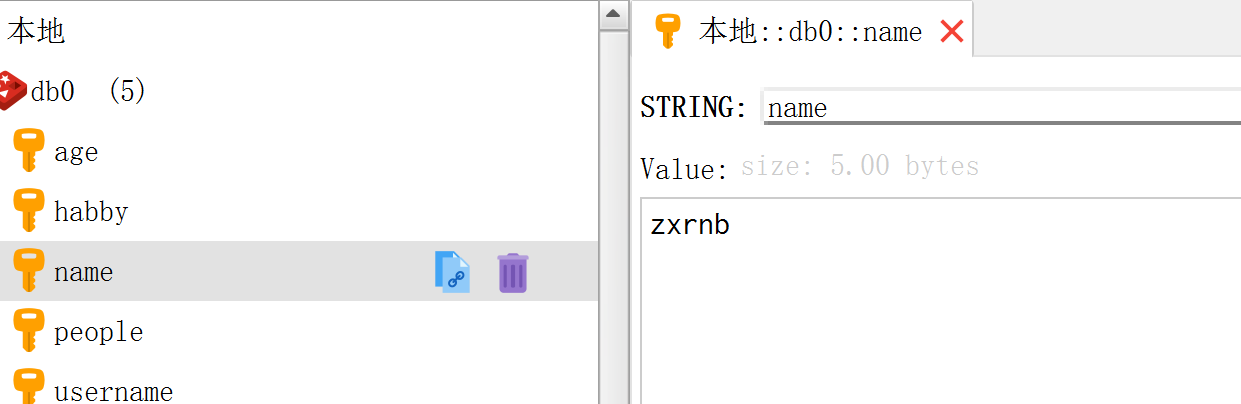
hmset(name, mapping) 弃用了
conn.hmset('yy', {'a': 'a', 'b': 'b'})
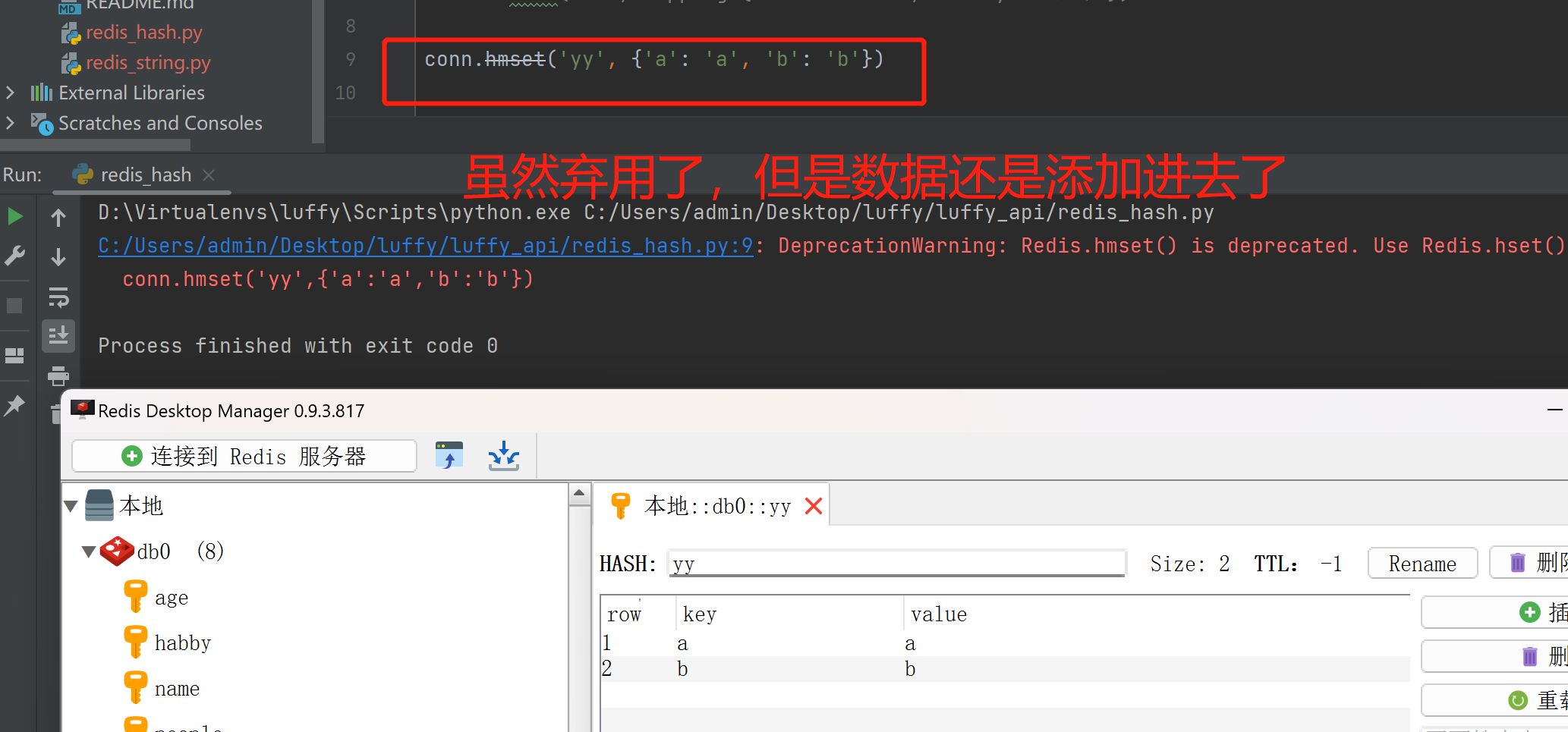
hget(name,key)
res = conn.hget('userinfo', 'age')
print(res)
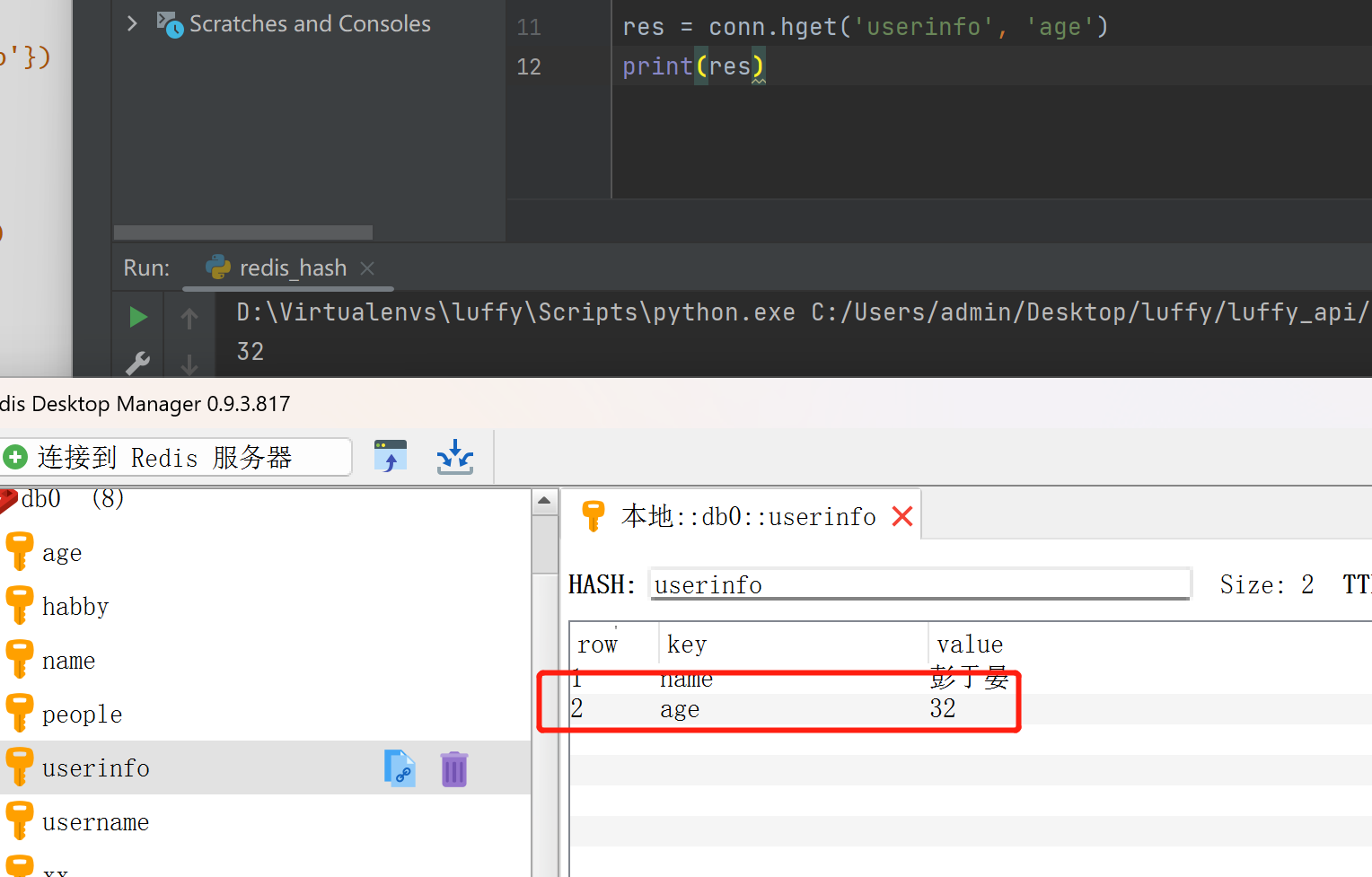
hmget(name, keys, *args)
res=conn.hmget('userinfo',['name','age'])
print(res)
hgetall(name) 慎用,可能会造成 阻塞 尽量不要在生产代码中执行它
res=conn.hgetall('userinfo')
print(res)
hlen(name)
res = conn.hlen('userinfo')
print(res)
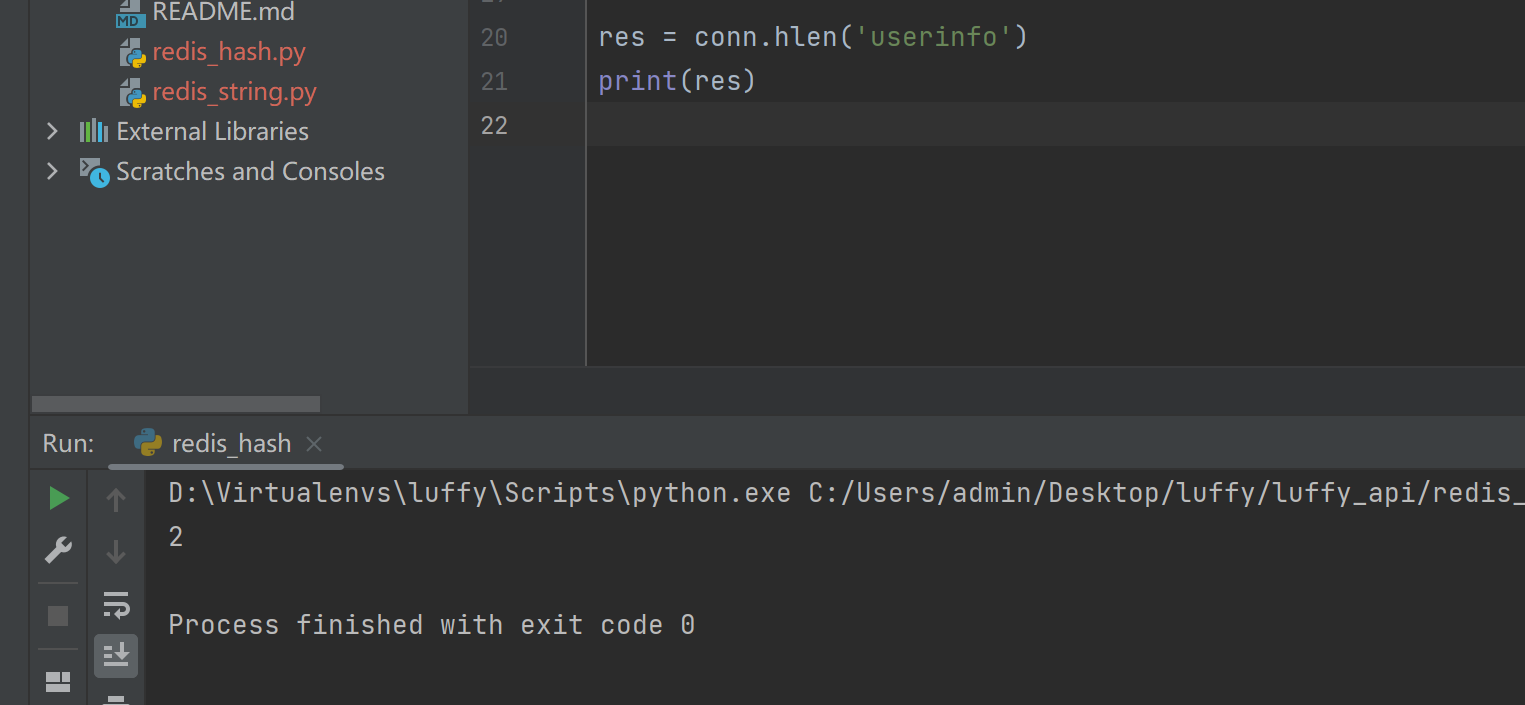
hkeys(name)
res = conn.hkeys('userinfo')
print(res)
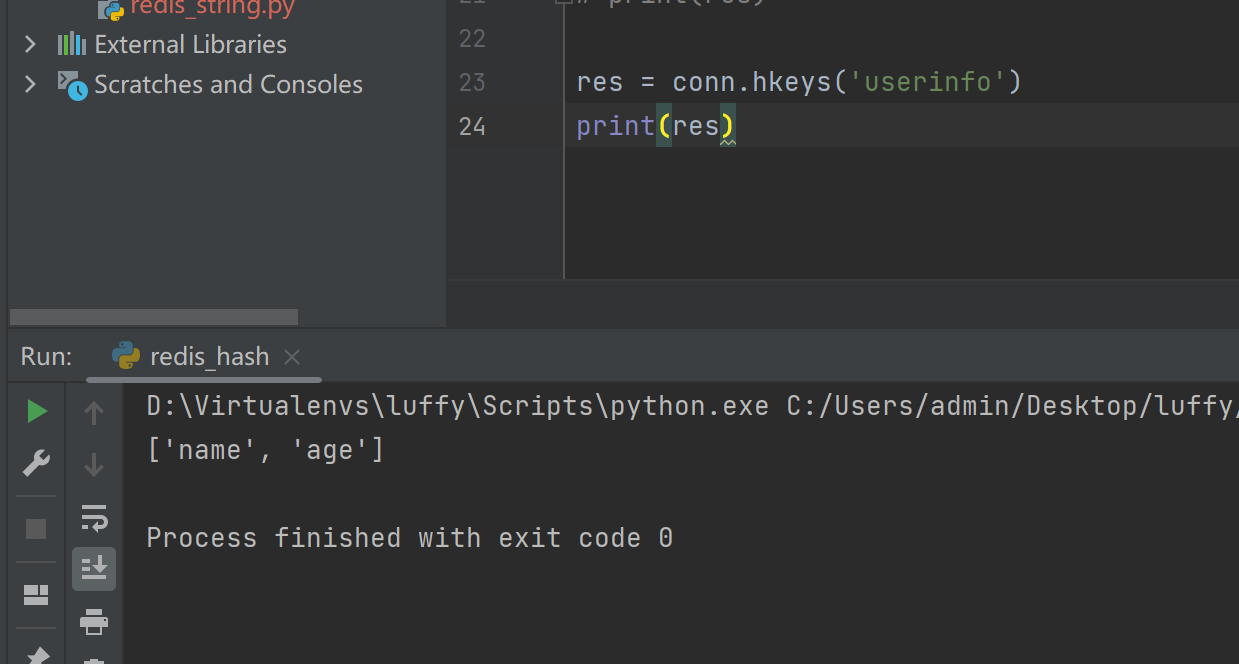
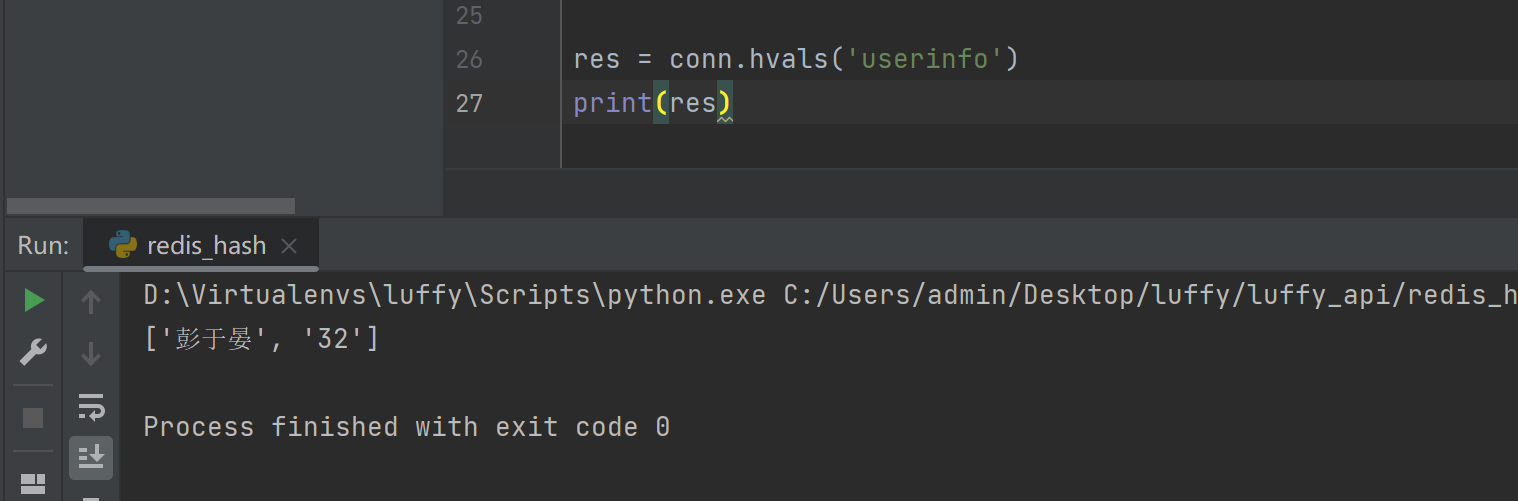
hvals(name)
res = conn.hvals('userinfo')
print(res)
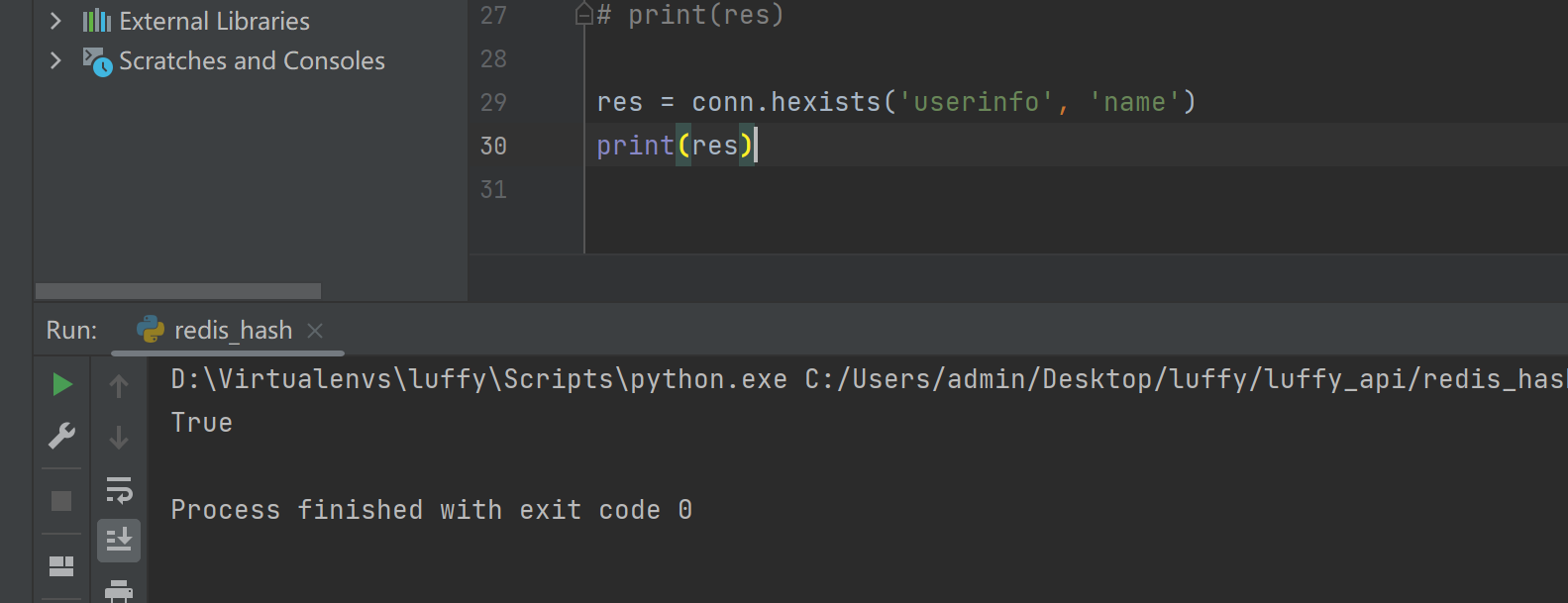
hexists(name, key)
res = conn.hexists('userinfo','name')
print(res)
hdel(name,*keys)
conn.hdel('userinfo','age')
hincrby(name, key, amount=1)
conn.hincrby('userinfo','age')
hincrbyfloat(name, key, amount=1.0)
conn.hincrbyfloat('userinfo','age',5.44)
hscan(name, cursor=0, match=None, count=None)
# hash类型没有顺序---》python字典 之前没有顺序,3.6后有序了 python字段的底层实现
# for i in range(1000):
# conn.hset('test_hash','key_%s'%i,'鸡蛋%s号'%i)
# count 是要取的条数,但是不准确,有点上下浮动
# 它一般步单独用
# res=conn.hscan('test_hash',cursor=0,count=19)
# print(res)
# print(res[0])
# print(res[1])
# print(len(res[1]))
# res=conn.hscan('test_hash',cursor=res[0],count=19)
# print(res)
# print(res[0])
# print(res[1])
# print(len(res[1]))
# 咱么用它比较多,它内部封装了hscan,做成了生成器,分批取hash类型所有数据
hscan_iter(name, match=None, count=None) 获取所有hash的数据
res = conn.hscan_iter('test_hash',count=100)
print(res) # 生成器
for item in res:
print(item)
conn.close()
三、列表类型
lpush(name,values)
conn.lpush('list1', '小金', '小里', '小莫')
lpushx(name,value)
conn.lpush('list1', '迪丽热巴')
rpushx(name, value) 表示从右向左操作
conn.rpushx('list1','古力娜扎')
llen(name)
print(conn.llen('list1'))
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值
# 参数:
# name,redis的name
# where,BEFORE或AFTER(小写也可以)
# refvalue,标杆值,即:在它前后插入数据(如果存在多个标杆值,以找到的第一个为准)
# value,要插入的数据
lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值
# 参数:
name,redis的name
index,list的索引位置
value,要设置的值
lrem(name, value, num)
# 在name对应的list中删除指定的值
# 参数:
name,redis的name
value,要删除的值
num, num=0,删除列表中所有的指定值;
num=2,从前到后,删除2个;
num=-2,从后向前,删除2个
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
# 更多:
rpop(name) 表示从右向左操作
lindex(name, index)
在name对应的列表中根据索引获取列表元素
lrange(name, start, end)
# 在name对应的列表分片获取数据
# 参数:
name,redis的name
start,索引的起始位置
end,索引结束位置 print(re.lrange('aa',0,re.llen('aa')))
ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
name,redis的name
start,索引的起始位置
end,索引结束位置(大于列表长度,则代表不移除任何)
rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
# 参数:
src,要取数据的列表的name
dst,要添加数据的列表的name
blpop(keys, timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素
# 参数:
keys,redis的name的集合
timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
# 更多:
r.brpop(keys, timeout),从右向左获取数据爬虫实现简单分布式:多个url放到列表里,往里不停放URL,程序循环取值,但是只能一台机器运行取值,可以把url放到redis中,多台机器从redis中取值,爬取数据,实现简单分布式
brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
# 参数:
src,取出并要移除元素的列表对应的name
dst,要插入元素的列表对应的name
timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
自定义增量迭代
# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要:
# 1、获取name对应的所有列表
# 2、循环列表
# 但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能:
import redis
conn=redis.Redis(host='127.0.0.1',port=6379)
# conn.lpush('test',*[1,2,3,4,45,5,6,7,7,8,43,5,6,768,89,9,65,4,23,54,6757,8,68])
# conn.flushall()
def scan_list(name,count=2):
index=0
while True:
data_list=conn.lrange(name,index,count+index-1)
if not data_list:
return
index+=count
for item in data_list:
yield item
print(conn.lrange('test',0,100))
for item in scan_list('test',5):
print('---')
print(item)
redis其他操作
# 集合,有序集合 --- redis模块提供的方法API
# 通用操作:无论是5大类型的那种,都支持
import redis
conn = redis.Redis()
# 1 delete(*names)
# conn.delete('age', 'name')
# 2 exists(name)
# res=conn.exists('xx')
# print(res) # 0
# 3 keys(pattern='*')
# res=conn.keys('*o*')
# res=conn.keys('?o*')
# print(res)
# 4 expire(name ,time)
# conn.expire('test_hash',3)
# 5 rename(src, dst) # 对redis的name重命名为
# conn.rename('xx','xxx')
# 6 move(name, db) # 将redis的某个值移动到指定的db下
# 默认操作都是0 库,总共默认有16个库
# conn.move('xxx',2)
# 7 randomkey() 随机获取一个redis的name(不删除)
# res=conn.randomkey()
# print(res)
# 8 type(name) 查看类型
# res = conn.type('aa') # list hash set
# print(res)
conn.close()
