


正反向查询进阶操作、聚合查询、分组查询、F与Q查询、ORM查询优化
正反向查询进阶操作
'''正反向查询进阶操作'''
# 1.查询主键为1的书籍对应的出版社名称及书名
res = models.Publish.objects.filter(book__pk=1).values('name', 'book__title')
print(res) # <QuerySet [{'name': '清华大学出版社', 'book__title': '女人你成功引起了我的注意'}]>
# 2.查询主键为3的书籍对应的作者姓名及书名
res1 = models.Author.objects.filter(book__pk=3).values('name', 'book__title')
print(res1) # <QuerySet [{'name': 'jfw', 'book__title': '凉生,我们可不可以不忧伤'}]>
# 3.查询zxb的作者的电话号码和地址
res2 = models.AuthorDetail.objects.filter(author__name='zxb').values('phone', 'addr')
print(res2) # <QuerySet [{'phone': 119, 'addr': '浙江'}]>
# 4.查询东方出版社出版的书籍名称和价格
res4 = models.Book.objects.filter(publish__name='东方出版社').values('title', 'price')
print(res4) # <QuerySet [{'title': '桃疆', 'price': Decimal('14.67')}, {'title': '三生三十十里桃花', 'price': Decimal('35.98')}, {'title': '玄霜', 'price': Decimal('54.21')}]>
# 5.查询zxr写过的书的名称和日期
res5 = models.Book.objects.filter(author__name='zxb').values('title', 'publish_time')
print(res5) # <QuerySet [{'title': '女人你成功引起了我的注意', 'publish_time': datetime.datetime(2022, 9, 5, 13, 16, 43, 303992, tzinfo=<UTC>)}]>
# 6.查询电话是110的作者姓名和年龄
res6 = models.Author.objects.filter(author_detail__phone=110).values('name', 'age')
print(res6) # <QuerySet [{'name': 'zxr', 'age': 18}]>
# 7.查询主键为1的书籍对应的作者电话号码
res7 = models.AuthorDetail.objects.filter(author__book__pk=1).values('phone')
print(res7) # <QuerySet [{'phone': 120}, {'phone': 119}]>
res8 = models.Author.objects.filter(book__pk=1).values('author_detail__phone')
print(res8) # <QuerySet [{'author_detail__phone': 120}, {'author_detail__phone': 119}]>
聚合查询
聚合函数:max、min、sum、avg、count
1.使用聚合函数之前需要导入模块
from django.db.models import Max, Min, Sum, Avg, Count
2.聚合函数的使用
聚合函数通常情况下是配合分组一起使用的
3.关键字aggregate
没有分组之前如果单纯的使用聚合函数 需要关键字aggregate
# 1.查询所有书的平均价格
res = models.Book.objects.aggregate(Avg('price'))
print(res) # {'price__avg': Decimal('183.117778')}
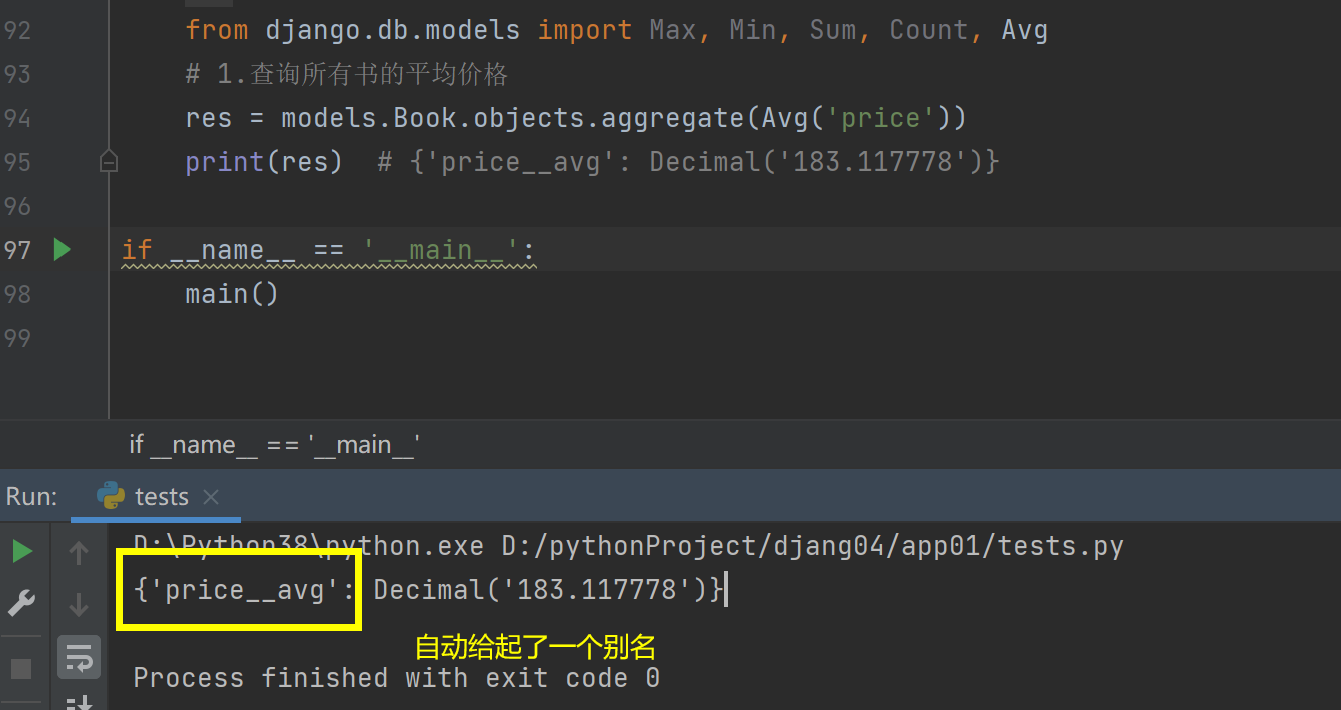
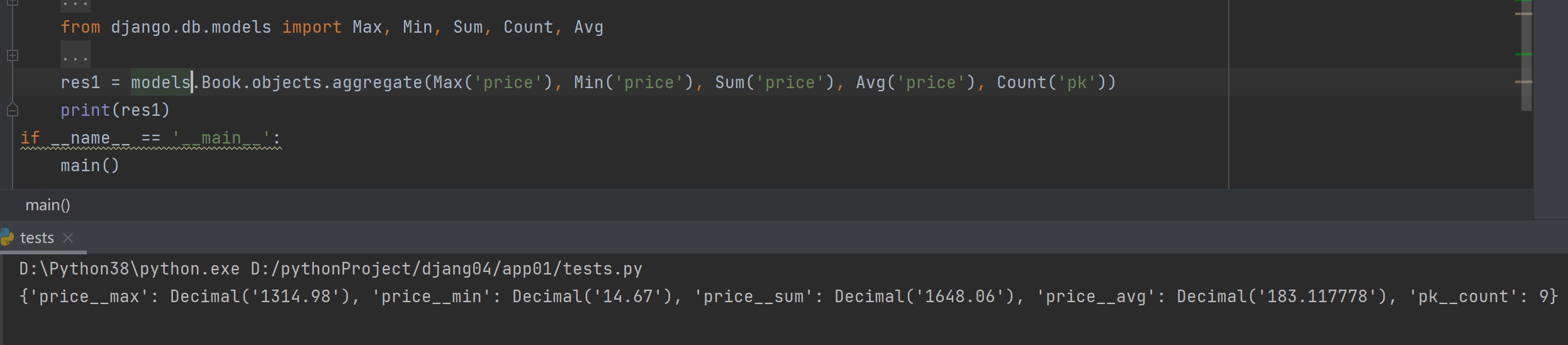
res1 = models.Book.objects.aggregate(Max('price'), Min('price'), Sum('price'), Avg('price'), Count('pk'))
print(res1)
分组查询
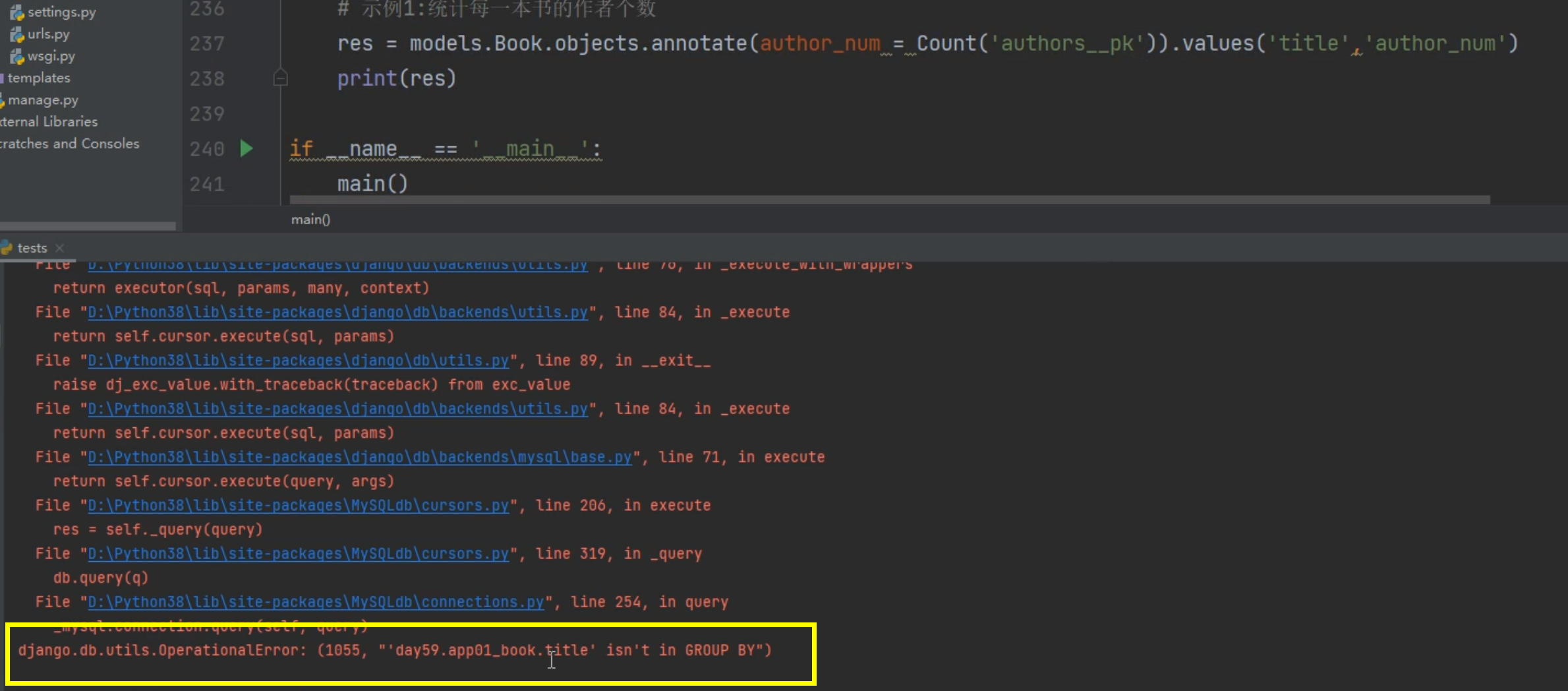
报错原因
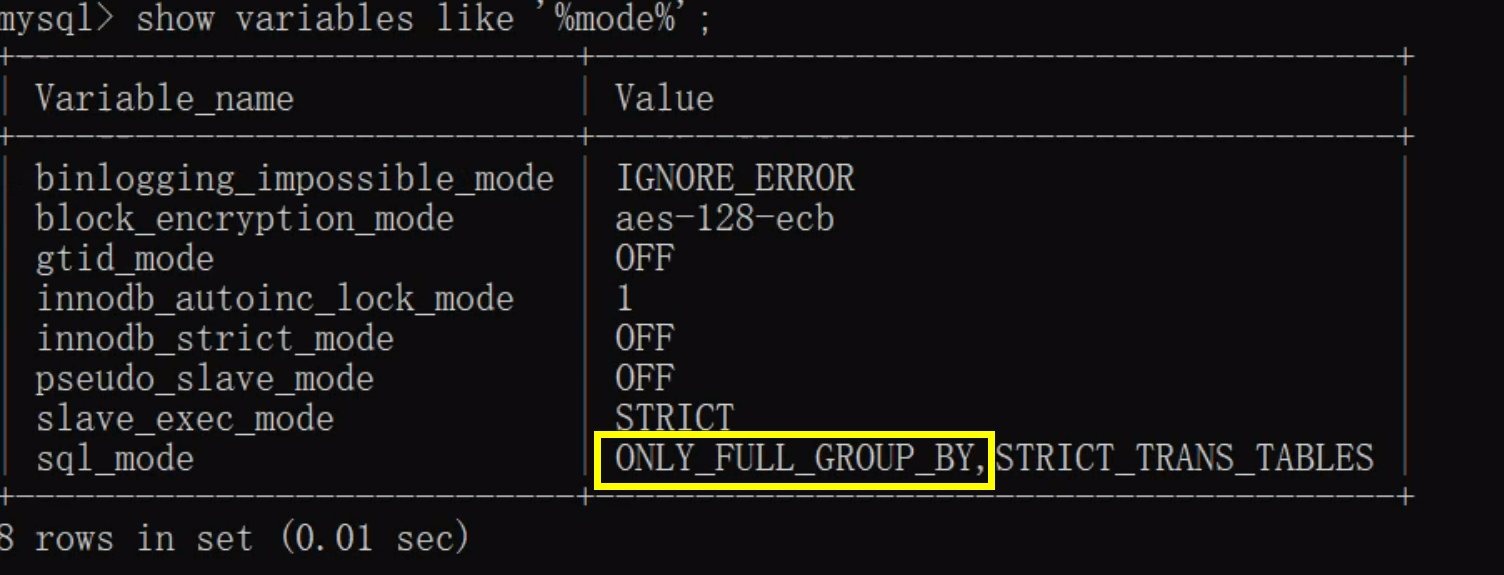
打开MySQL
输入>>>:show variables like '%mode%';
分组有一个特性 默认只能够直接获取分组的字段 其他字段需要使用方法
我们也可以忽略掉该特性 将sql_mode中only_full_group_by配置移除即可
# 示例1:统计每一本书的作者个数
res = models.Book.objects.annotate(author_num=Count('author__pk')).values('title', 'author_num')
print(res)
"""
1.按照整条数据分组
models.Book.objects.annotate() 按照一条条书籍记录分组
2.按照表中某个字段分组()
models.Book.objects.values('title').annotate() 按照annotate之前values括号中指定的字段分组
"""
"""
<QuerySet [{'title': '女人你成功引起了我的注意爆款~爆款', 'author_num': 2},
{'title': '凉生,我们可不可以不忧伤爆款~爆款', 'author_num': 1},
{'title': '桃疆爆款~爆款', 'author_num': 2},
{'title': '我是你的,生生世世爆款~爆款', 'author_num': 2},
{'title': '国民大侦探爆款~爆款', 'author_num': 1},
{'title': '十宗罪爆款~爆款', 'author_num': 1},
{'title': '三生三十十里桃花爆款~爆款', 'author_num': 1},
{'title': '玄霜爆款~爆款', 'author_num': 1},
{'title': '一生一世爆款~爆款', 'author_num': 1}]>
"""
1.分组查询
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数,所有使用前要从django.db.models引入Avg,Max,Count,Sum(首字母大写))。
2.返回值
分组后,用values取值,则返回值是QuerySet书籍类型里面为一个个字典
分组后,用values_list取值,则返回值是QuerySet数据类型里面为一个个元组
MySQL中的limit相当于ORM中的QuerySet数据类型的切片。
3.分组查询关键字
annotate() 里面放聚合函数
1.values 或者 values_list 放在 annotate 前面:values 或者 values_list 是声明以什么字段分组,annotate 执行分组。
2.values 或者 values_list 放在annotate后面: annotate 表示直接以当前表的pk执行分组,values 或者 values_list 表示查询哪些字段, 并且要将 annotate 里的聚合函数起别名,在 values 或者 values_list 里写其别名。
3.filter放在 annotate 前面:表示where条件
4.filter放在annotate后面:表示having
跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询
分组练习题
models后面点什么 就按什么分组
author_num 是我们自己定义的字段 用来存储统计出来的每本书对应的作者个数
1.统计每一本书的作者个数
res = models.Book.objects.annotate(author_num=Count('author__pk')).values('title', 'author_num')
print(res)
res1 = models.Book.objects.values('publish_id').annotate(book_num=Count('pk')).values('publish_id','book_num')
print(res1)
"""
1.按照整条数据分组
models.Book.objects.annotate() 按照一条条书籍记录分组
2.按照表中某个字段分组()
models.Book.objects.values('title').annotate() 按照annotate之前values括号中指定的字段分组
"""
"""
<QuerySet [{'title': '女人你成功引起了我的注意', 'author_num': 2},
{'title': '凉生,我们可不可以不忧伤', 'author_num': 1},
{'title': '桃疆', 'author_num': 2},
{'title': '我是你的,生生世世', 'author_num': 2},
{'title': '国民大侦探', 'author_num': 1},
{'title': '十宗罪', 'author_num': 1},
{'title': '三生三十十里桃花', 'author_num': 1},
{'title': '玄霜', 'author_num': 1},
{'title': '一生一世', 'author_num': 1}]>
"""

2.统计每个出版社卖的最便宜的书的价格
res1 = models.Publish.objects.annotate(min_price=Min('book__price')).values('name', 'min_price')
print(res1)
"""
<QuerySet [{'name': '清华大学出版社',
'min_price': Decimal('28.98')},
{'name': '北方出版社', 'min_price': Decimal('34.98')},
{'name': '南方出版社', 'min_price': Decimal('56.29')},
{'name': '东方出版社', 'min_price': Decimal('14.67')}]>
"""

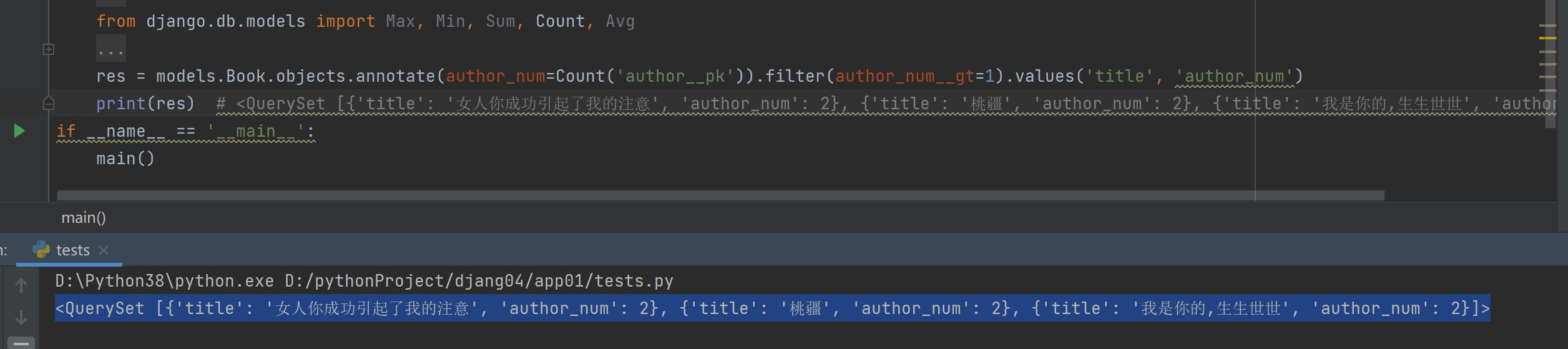
3.统计不止一个作者的图书
'''filter在annotate前面则是where 在annotate后面则是having'''
res = models.Book.objects.annotate(author_num=Count('author__pk')).filter(author_num__gt=1).values('title', 'author_num')
print(res)
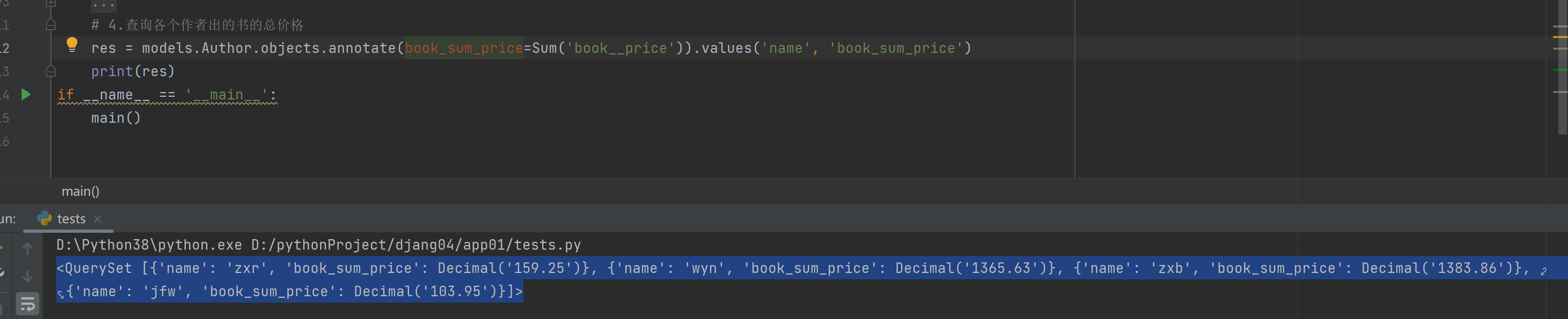
4.查询各个作者出的书的总价格
res = models.Author.objects.annotate(book_sum_price=Sum('book__price')).values('name', 'book_sum_price')
print(res)
"""
<QuerySet [{'name': 'zxr', 'book_sum_price': Decimal('159.25')},
{'name': 'wyn', 'book_sum_price': Decimal('1365.63')},
{'name': 'zxb', 'book_sum_price': Decimal('1383.86')},
{'name': 'jfw', 'book_sum_price': Decimal('103.95')}]>
"""
F与Q查询
导入模块
from django.db.models import F,Q
F查询
能够帮助你直接获取到列表中某个字段对应的数据
注意:
在操作字符串类型的数据的时候, F不能够直接做到字符串的拼接
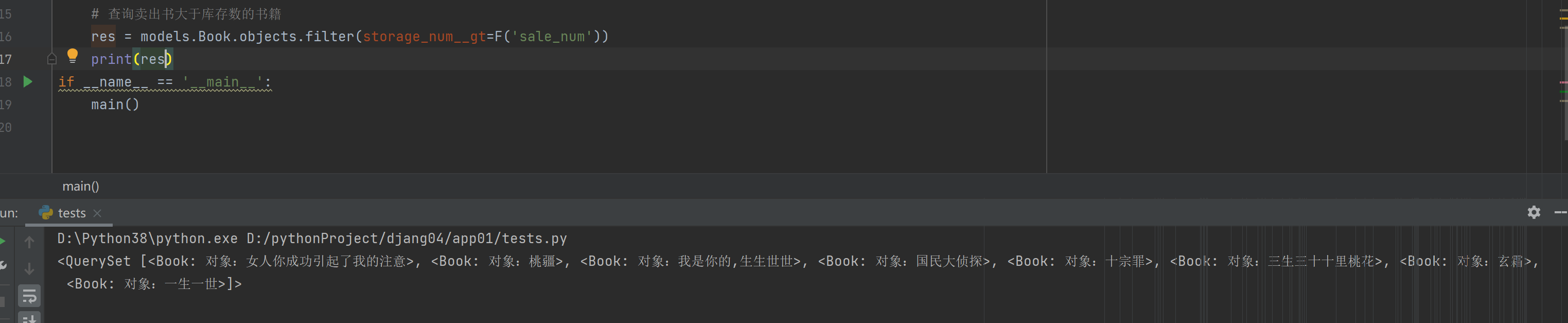
1.查询卖出书大于库存数的书籍
res = models.Book.objects.filter(storage_num__gt=F('sale_num'))
print(res)
将所有书籍的价格上涨1000快
res = models.Book.objects.update(price=F('price') + 1000)
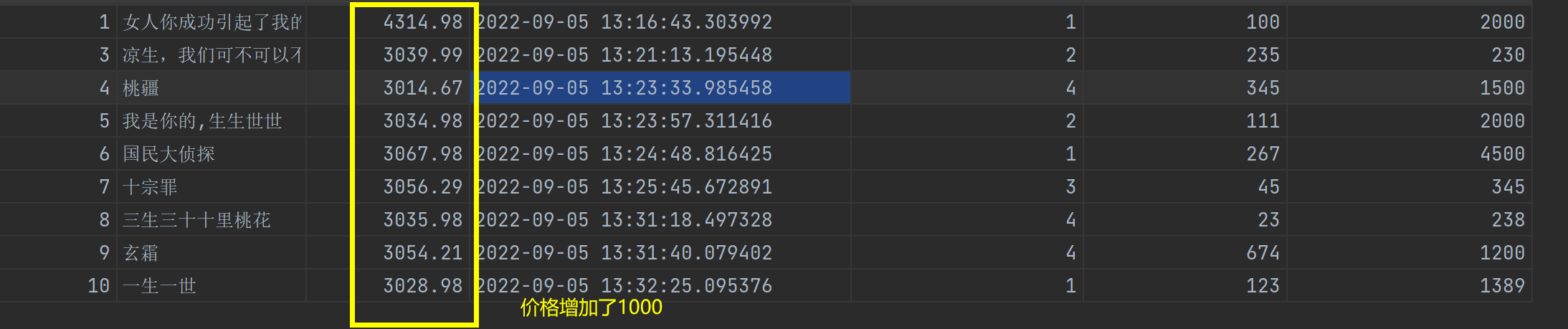
给所有书籍名称后面加上爆款后缀
针对字符串数据无法直接拼接
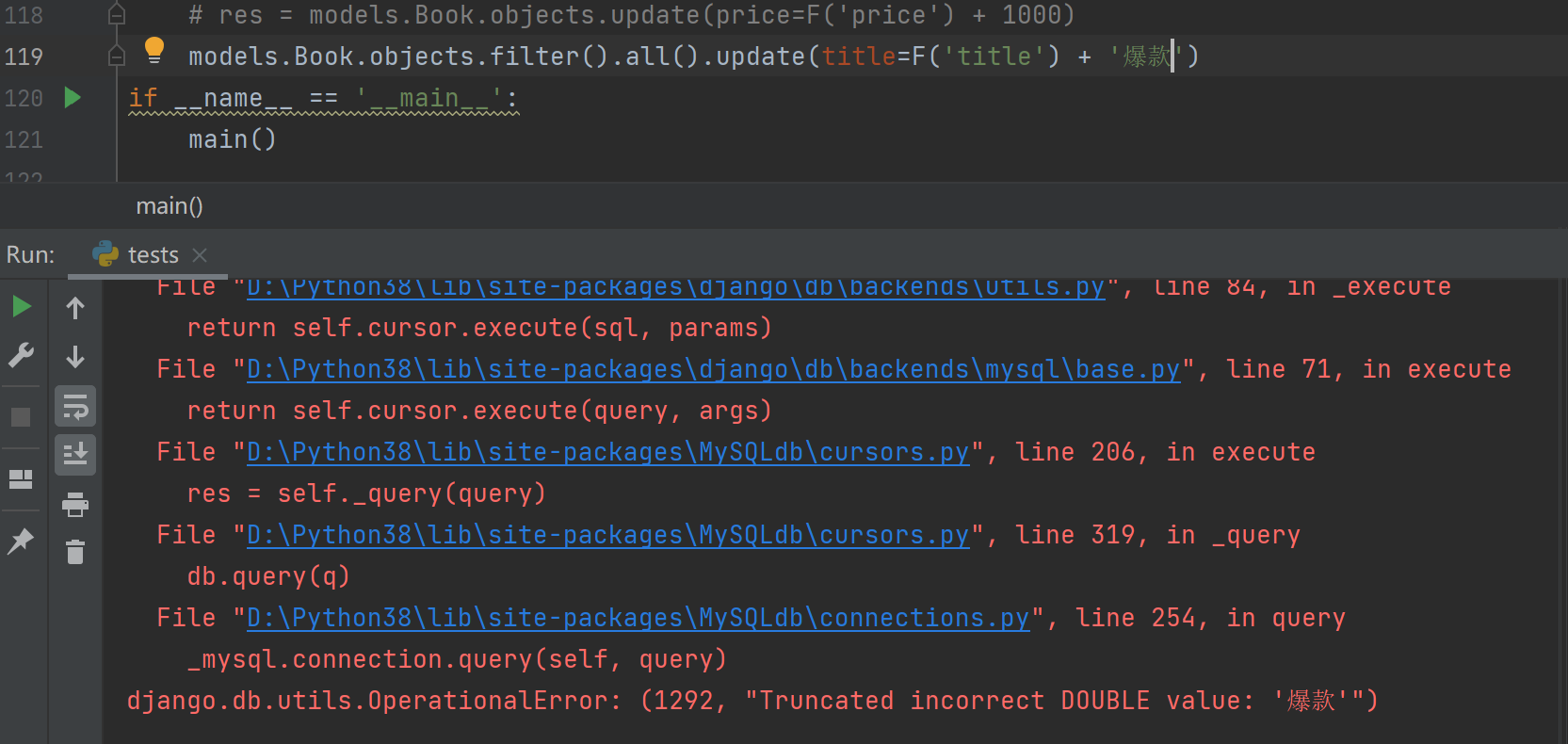
models.Book.objects.filter().all().update(title=F('title') + '爆款') # 针对字符串数据无法直接拼接
# 导入Concat模块
from django.db.models.functions import Concat
# 导入Value模块
from django.db.models import Value
models.Book.objects.filter().all().update(title=Concat(F('title'), Value('~爆款')))
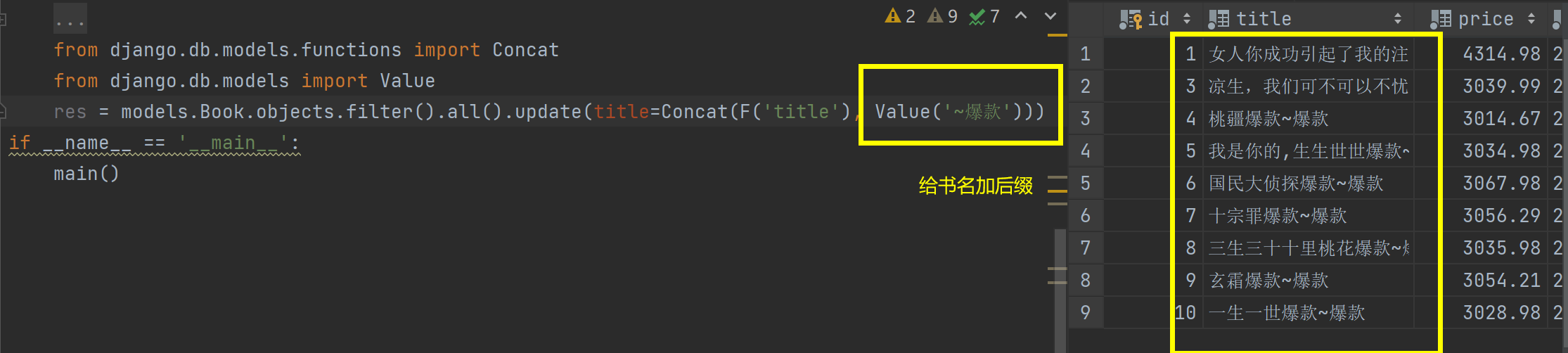
Q查询
可以改变filter括号内多个条件之间的逻辑运算符,还可以将查询的结果改为字符串形式
filter()等方法中的关键字参数查询都是一起进行"and",如果你需要执行更复杂的查询(列如ORM语句),你可以使用Q对象。
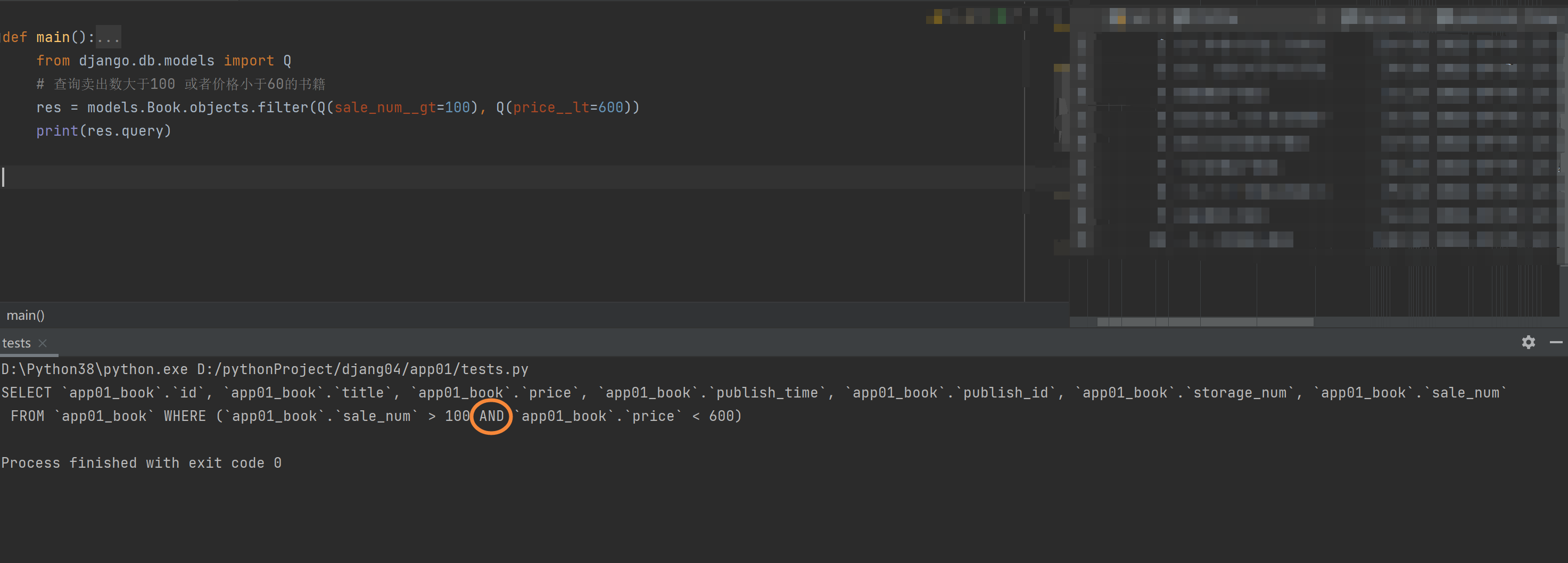
查询卖出数大于100并且价格小于60的书籍
res = models.Book.objects.filter(Q(sale_num__gt=100), Q(price__lt=600))
print(res)
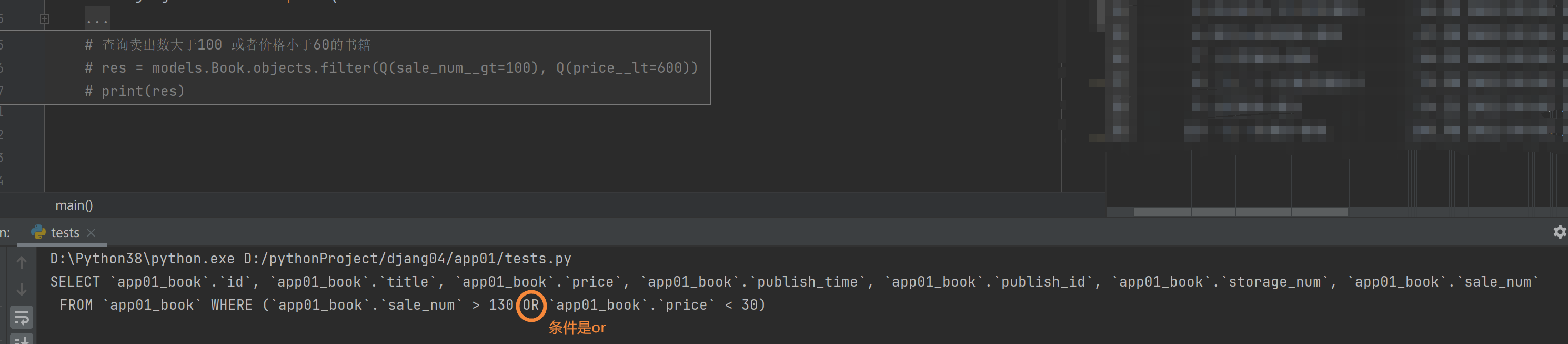
查询卖出数大于130或者价格小于30的书籍
res = models.Book.objects.filter(Q(sale_num__gt=130) | Q(price__lt=30))
print(res)
查询卖出数不是大于80或者价格大于600的书籍
res = models.Book.objects.filter(~Q(sale_num__gt=80) | Q(price__gt=600))
print(res)

总结
, and关系
| or关系
~ not关系
Q 默认是and,可以进行修改
q = Q()
q.connector = 'or'
Q查询的进阶用法
可以将查询的结果改为字符串形式
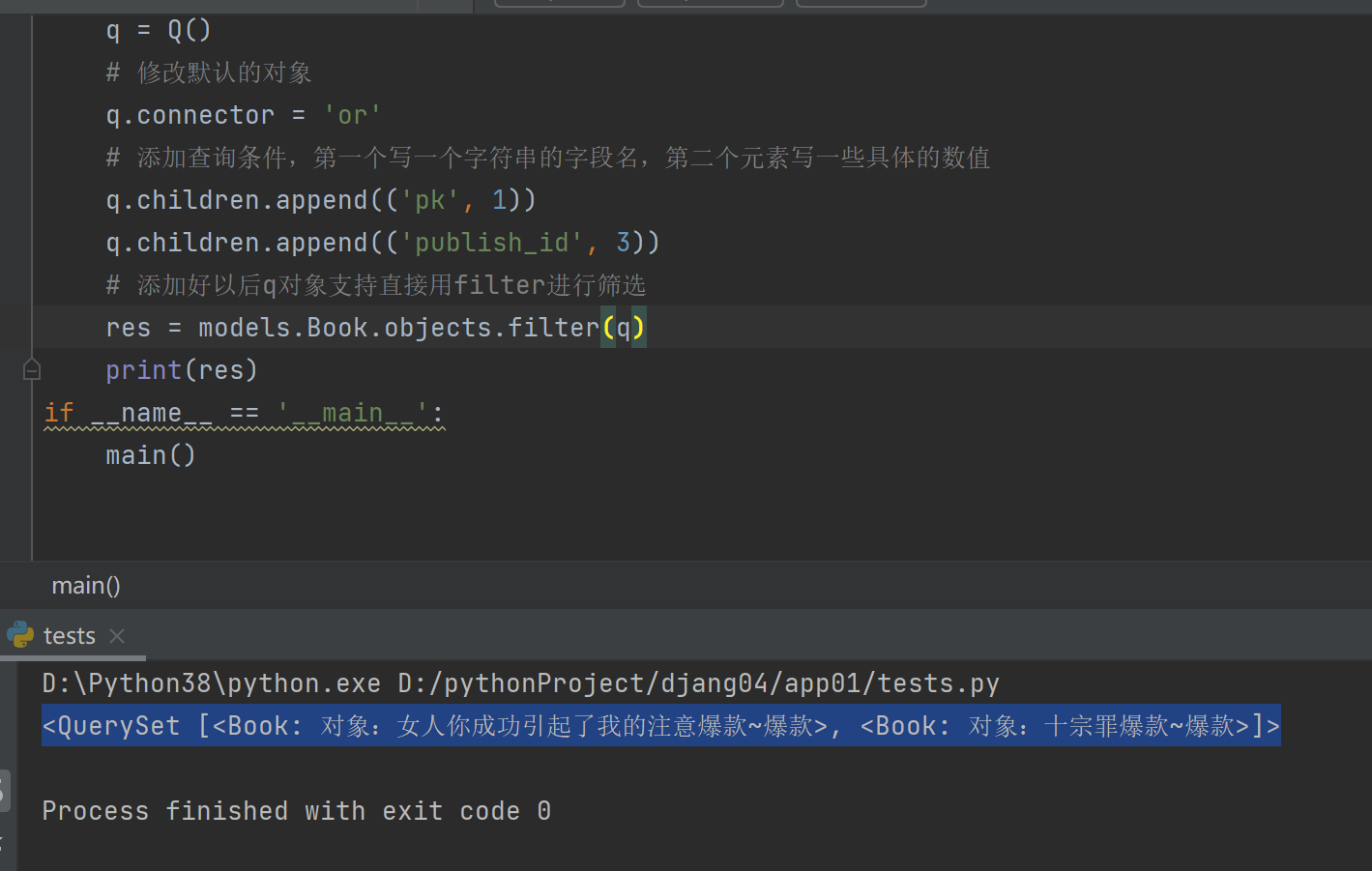
先产生一个对象
q = Q()
修改默认的对象
q.connector = 'or'
添加查询条件,第一个写一个字符串的字段名 第二个元素写一些具体的数值
q.children.append(('pk', 1))
q.children.append(('publish_id', 3))
添加好以后q对象支持直接用filter进行筛选
res = models.Book.objects.filter(q)
print(res)

ORM查询优化
django orm默认都是惰性查询
当orm的语句在后续的代码中真正需要使用的时候才会执行
django orm自带limit分页
减轻数据库端以及服务端的压力
1.ORM查询优化之only(单表)
res = models.Book.objects.only('title','price')
for obj in res:
print(obj.title)
print(obj.price)
print(obj.publish_time)
"""
only会将括号内填写的字段封装成一个个数据对象 对象在点击的时候不会再走数据库查询
但是对象也可以点击括号内没有的字段 只不过每次都会走数据库查询
如果看到有人只有only查询的话 尽量不要去点括号内没有的字段 因为它每次都会去查询一次
"""
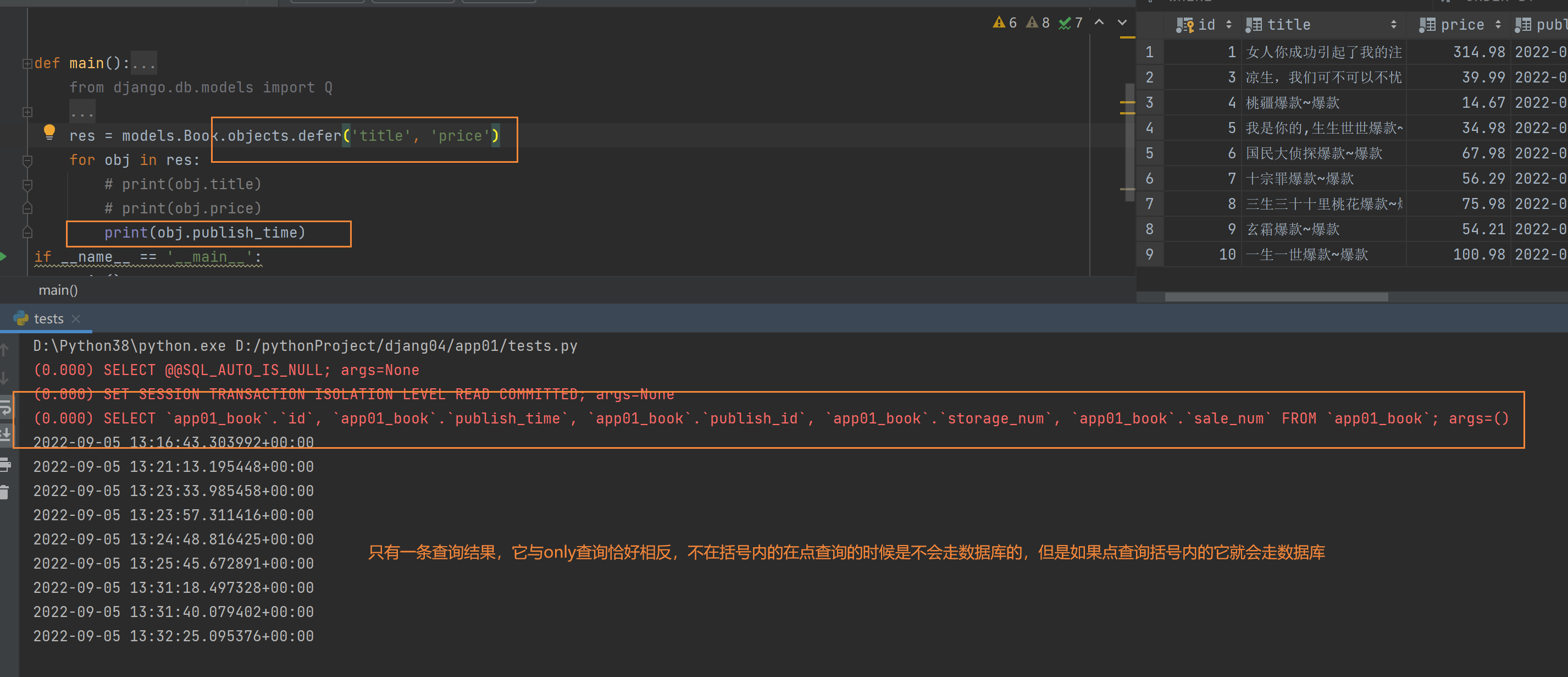
2.ORM查询优化之defer(单表)
res = models.Book.objects.defer('title', 'price')
for obj in res:
# print(obj.title)
# print(obj.price)
print(obj.publish_time)
"""
defer与only刚好相反
数据对象点击括号内出现的字段 每次都会走数据库查询
数据对象点击括号内没有的字典 不会走数据库查询
"""
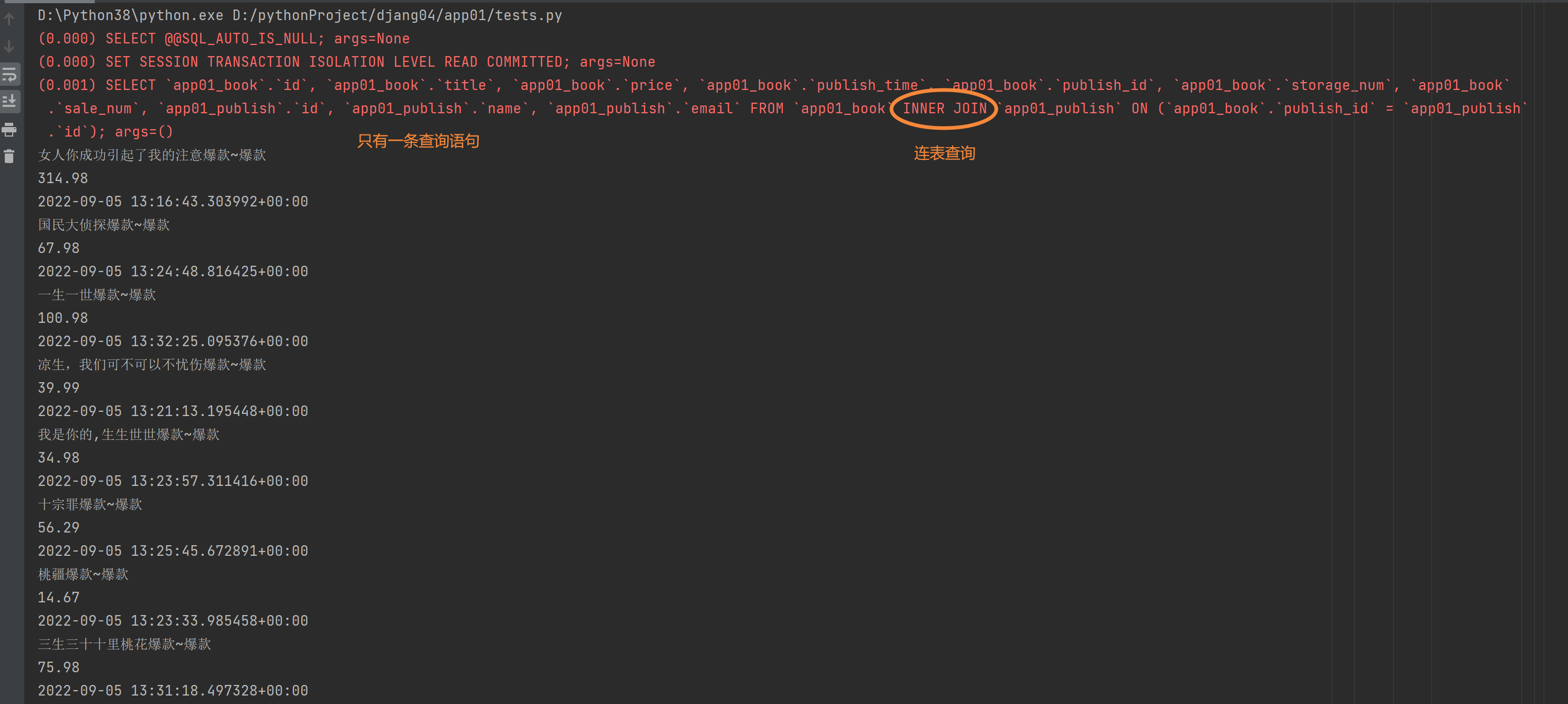
3.ORM查询优化之select_related(多表)
res = models.Book.objects.all()
for obj in res:
print(obj.publish.name) # 频繁走数据库查询
res = models.Book.objects.select_related('publish')
"""
select_related括号内只能接收外键字段(一对多 一对一) 它会在内部自动拼表 得出的数据对象在点击表中数据的时候都不会再走数据库查询
"""
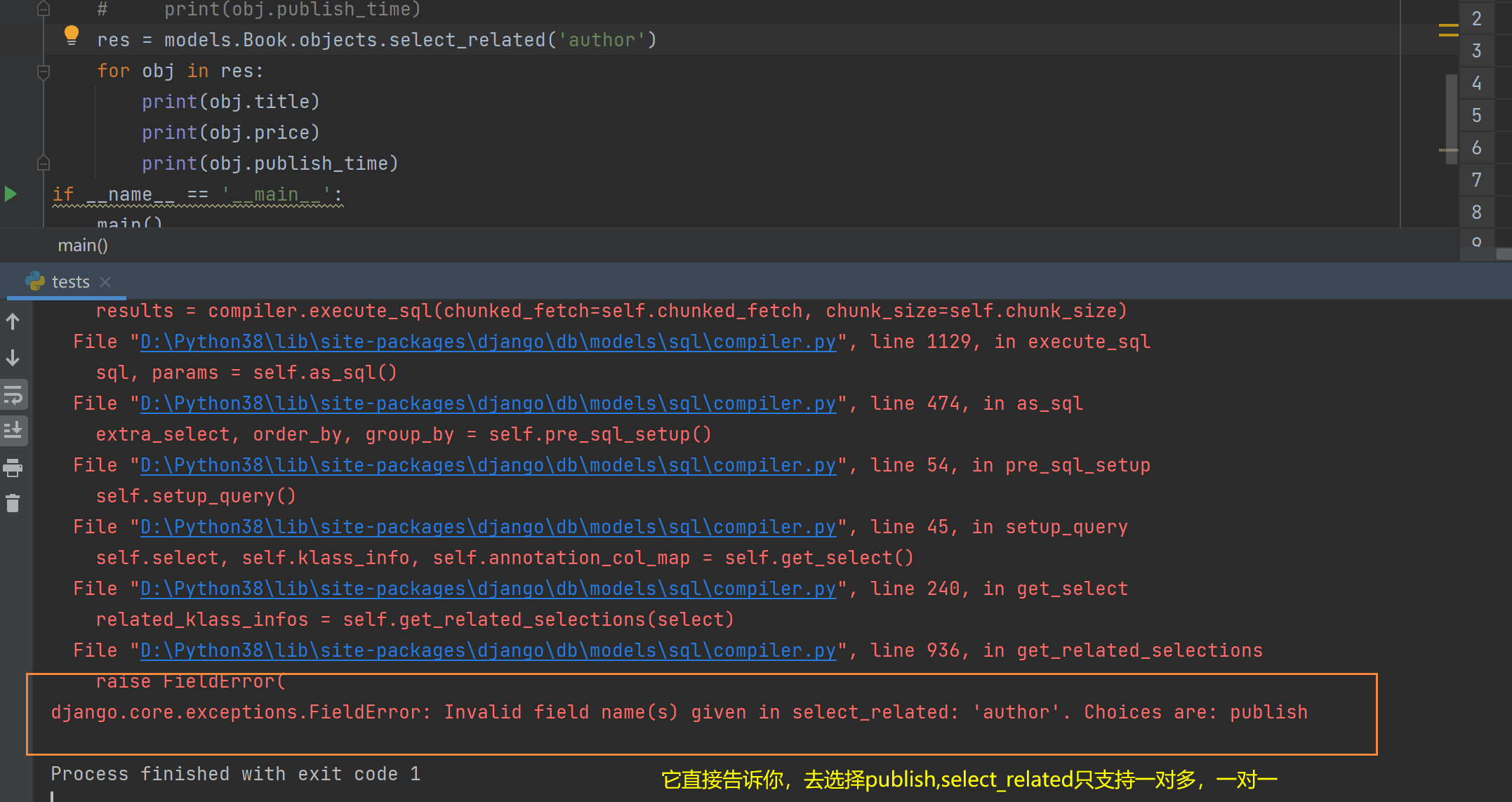
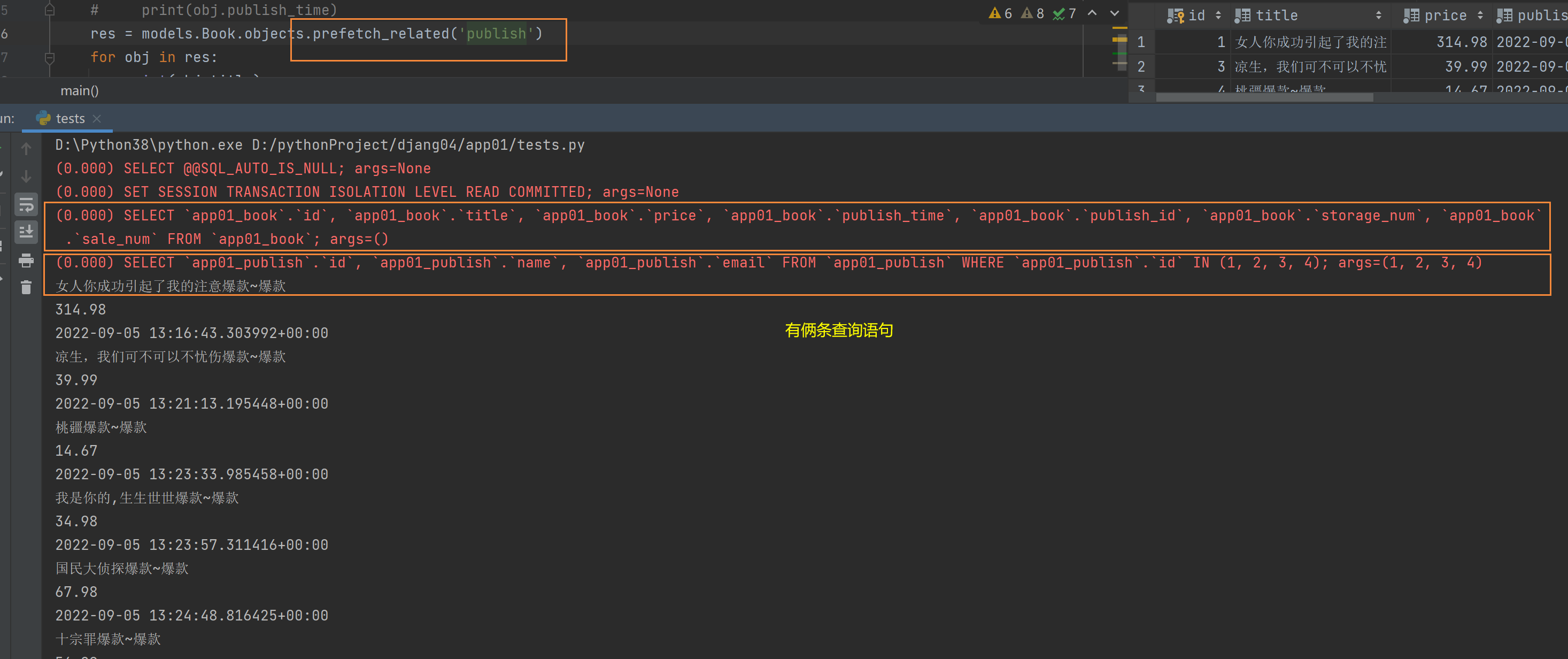
4.ORM查询优化之prefetch_related(多表)
for obj in res:
print(obj.publish.name)
"""
prefetch_related底层其实是子查询 将查询之后的结果也一次性封装到数据对象中 用户在使用的时候是感觉不出来的
"""
res = models.Book.objects.prefetch_related('publish')
for obj in res:
print(obj.publish.name)
额外补充个知识:当表中已经有数据的情况下 添加新的字段需要指定一些参数
class Book(models.Model):
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8, decimal_places=2)
publish_time = models.DateTimeField(auto_now=True)
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
author = models.ManyToManyField(to='Author')
'''
当表中已经有数据的情况下 添加新的字段需要指定一些参数
1.设置字段值存于为空 null=True
2.设置字段默认值 default=1000
3.在终端直接给出默认值
'''
storage_num = models.IntegerField(verbose_name='库存数', null=True)
sale_num = models.IntegerField(verbose_name='卖出数目', default=1000)
def __str__(self):
return f'对象:{self.title}'
报错问题
django.db.utils.OperationalError: (2002, "Can't connect to server on '127.0.0.1' (10061)")
解决方法:查看数据库是否启动,导致这个错误很可能是MySQL停止了服务

